Android应用程序UI硬件加速渲染环境初始化过程分析
Android应用程序UI硬件加速渲染环境初始化过程分析
在Android应用程序中,我们是通过Canvas API来绘制UI元素的。在硬件加速渲染环境中,这些Canvas API调用最终会转化为Open GL API调用(转化过程对应用程序来说是透明的)。由于Open GL API调用要求发生在Open GL环境中,因此在每当有新的Activity窗口启动时,系统都会为其初始化好Open GL环境。这篇文章就详细分析这个Open GL环境的初始化过程。
Open GL环境也称为Open GL渲染上下文。一个Open GL渲染上下文只能与一个线程关联。在一个Open GL渲染上下文创建的Open GL对象一般来说只能在关联的Open GL线程中操作。这样就可以避免发生多线程并发访问发生的冲突问题。这与大多数的UI架构限制UI操作只能发生在UI线程的原理是差不多的。
在Android 5.0之前,Android应用程序的主线程同时也是一个Open GL线程。但是从Android 5.0之后,Android应用程序的Open GL线程就独立出来了,称为Render Thread,如图1所示:
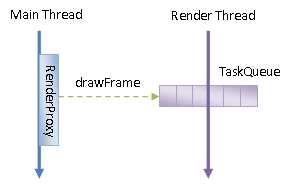
图1 Android应用程序Main Thread和Render Thread
Render Thread有一个Task Queue,Main Thread通过一个代理对象Render Proxy向这个Task Queue发送一个drawFrame命令,从而驱使Render Thread执行一次渲染操作。因此,Android应用程序UI硬件加速渲染环境的初始化过程任务之一就是要创建一个Render Thread。
一个Android应用程序可能存在多个Activity组件。在Android系统中,每一个Activity组件都是一个独立渲染的窗口。由于一个Android应用程序只有一个Render Thread,因此当Main Thread向Render Thread发出渲染命令时,Render Thread要知道当前要渲染的窗口是什么。从这个角度看,Android应用程序UI硬件加速渲染环境的初始化过程任务之二就是要告诉Render Thread当前要渲染的窗口是什么。
一旦Render Thread知道了当前要渲染的窗口,它就将可以将该窗口绑定到Open GL渲染上下文中去,从而使得后面的渲染操作都是针对被绑定的窗口的,如图2所示:
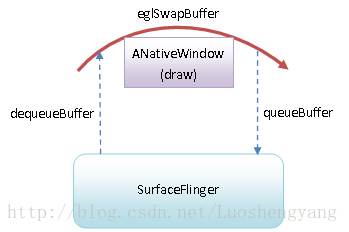
图2 绑定窗口到Open GL渲染上下文中
Java层的Activity窗口到了Open GL这一层,被抽象为一个ANativeWindow。将它绑定到Open GL渲染上下文之后,就可以通过eglSwapBuffer函数向SurfaceFlinger服务Dequeue和Queue Graphic Buffer。其中,Dequeue Graphic Buffer是为了在上面进行绘制UI,而Queue Graphic Buffer是为了将绘制好的UI交给Surface Flinger合成和显示。
接下来,我们就结合源代码分析Android应用程序UI硬件加速渲染环境的初始化过程,主要的关注点就是创建Render Thread的过程和绑定窗口到Render Thread的过程。
从前面Android应用程序窗口(Activity)的视图对象(View)的创建过程分析一文可以知道,Activity组件在创建的过程中,也就是在其生命周期函数onCreate的调用过程中,一般会通过调用另外一个成员函数setContentView创建和初始化关联的窗口视图,最后通过调用ViewRoot类的成员函数setView完成这一过程。上述文章分析的源码是Android 2.3版本的。到了Android 4.0之后,ViewRoot类的名字改成了ViewRootImpl,它们的作用仍然一样的。
Android应用程序UI硬件加速渲染环境的初始化过程是在ViewRootImpl类的成员函数setView开始,如下所示:
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, HardwareRenderer.HardwareDrawCallbacks {
......
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
synchronized (this) {
if (mView == null) {
mView = view;
......
if (view instanceof RootViewSurfaceTaker) {
mSurfaceHolderCallback =
((RootViewSurfaceTaker)view).willYouTakeTheSurface();
if (mSurfaceHolderCallback != null) {
mSurfaceHolder = new TakenSurfaceHolder();
mSurfaceHolder.setFormat(PixelFormat.UNKNOWN);
}
}
......
// If the application owns the surface, don't enable hardware acceleration
if (mSurfaceHolder == null) {
enableHardwareAcceleration(attrs);
}
......
}
}
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/ViewRootImpl.java中。
参数view描述的是当前正在创建的Activity窗口的顶级视图。如果它实现了RootViewSurfaceTaker接口,并且通过该接口的成员函数willYouTakeTheSurface提供了一个SurfaceHolder.Callback2接口,那么就表明应用程序想自己接管对窗口的一切渲染操作。这样创建出来的Activity窗口就类似于一个SurfaceView一样,完全由应用程序自己来控制它的渲染。
基本上我们是不会将一个Activity窗口当作一个SurfaceView来使用的,因此在ViewRootImpl类的成员变量mSurfaceHolder将保持为null值,这样就会导致ViewRootImpl类的成员函数enableHardwareAcceleration被调用为判断是否需要为当前创建的Activity窗口启用硬件加速渲染。
ViewRootImpl类的成员函数enableHardwareAcceleration的实现如下所示:
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, HardwareRenderer.HardwareDrawCallbacks {
......
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
mAttachInfo.mHardwareAccelerated = false;
mAttachInfo.mHardwareAccelerationRequested = false;
......
// Try to enable hardware acceleration if requested
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
if (hardwareAccelerated) {
if (!HardwareRenderer.isAvailable()) {
return;
}
// Persistent processes (including the system) should not do
// accelerated rendering on low-end devices. In that case,
// sRendererDisabled will be set. In addition, the system process
// itself should never do accelerated rendering. In that case, both
// sRendererDisabled and sSystemRendererDisabled are set. When
// sSystemRendererDisabled is set, PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED
// can be used by code on the system process to escape that and enable
// HW accelerated drawing. (This is basically for the lock screen.)
final boolean fakeHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FAKE_HARDWARE_ACCELERATED) != 0;
final boolean forceHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED) != 0;
if (fakeHwAccelerated) {
// This is exclusively for the preview windows the window manager
// shows for launching applications, so they will look more like
// the app being launched.
mAttachInfo.mHardwareAccelerationRequested = true;
} else if (!HardwareRenderer.sRendererDisabled
|| (HardwareRenderer.sSystemRendererDisabled && forceHwAccelerated)) {
.......
mAttachInfo.mHardwareRenderer = HardwareRenderer.create(mContext, translucent);
if (mAttachInfo.mHardwareRenderer != null) {
.......
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
}
}
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/ViewRootImpl.java中。
虽然硬件加速渲染是个好东西,但是也不是每一个需要绘制UI的进程都必需的。这样做是考虑到两个因素。第一个因素是并不是所有的Canvas API都可以被GPU支持。如果应用程序使用到了这些不被GPU支持的API,那么就需要禁用硬件加速渲染。第二个因素是支持硬件加速渲染的代价是增加了内存开销。例如,只是硬件加速渲染环境初始化这一操作,就要花掉8M的内存。因此,对于两类进程就不是很适合使用硬件加速渲染。
第一类进程是Persistent进程。Persistent进程是一种常驻进程,它们的优先级别很高,即使在内存紧张的时候也不会被AMS杀掉。对于低内存设备,这类进程是不适合使用硬件加速渲染的。在这种情况下,它们会将HardwareRenderer类的静态成员变量sRendererDisabled设置为true,表明要禁用硬件加速渲染。这里顺便提一下,一个应用程序进程可以在AndroidManifest.xml文件将Application标签的persistent属性设置为true来将自己设置为Persistent进程,不过只有系统级别的应用设置才有效。类似的进程有Phone、Bluetooth和Nfc等应用。
第二类进程是System进程。System进程有很多线程是需要显示UI的。这些UI一般都是比较简单的,并且System进程也像Persistent进程一样,在内存紧张时是无法杀掉的,因此它们完全没有必要通过硬件加速来渲染。于是,System进程就会将HardwareRenderer类的静态成员变量sRendererDisabled和sSystemRendererDisabled都会被设置为true,表示它要禁用硬件加速渲染。
对于System进程,有两种UI需要特殊处理。第一种UI是Starting Window。当一个Activity启动时,如果它的宿主进程还没有创建,那么在等待其宿主进程创建的过程中,System进程就会根据该Activity窗口设置的Theme显示一个Starting Window,也称为Preview Window。由于System进程是禁用了硬件加速渲染的,因此Starting Window是通过软件方式渲染的。但是为了使得Starting Window的渲染更像它对应的Activity窗口,我们将用来描述Starting Window属性的一个AttachInfo对象的成员变量mHardwareAccelerationRequested的值设置为true。这将会使得Starting Window的view_state_accelerated属性设置为true。该属性一旦被设置为true,将会使得Starting Window的另一属性colorBackgroundCacheHint被忽略。属性colorBackgroundCacheHint被忽略之后,Starting Window在绘制的过程中将不会被缓存。使用了硬件加速渲染的Activity窗口在渲染的过程中也是不会被缓存的。这就使得它们的渲染行为保持一致。Starting Window的这一特性是通过将参数attrs指向的一个WindowManager.LayoutParams对象的成员变量privateFlags的位WindowManager.LayoutParams.PRIVATE_FLAG_FAKE_HARDWARE_ACCELERATED设置为1来描述的。
第二种UI是锁屏界面。锁屏界面是一个例外,它允许使用硬件加速渲染。但是System进程又表明了它要禁用硬件加速渲染,这时候就通过将参数attrs指向的一个WindowManager.LayoutParams对象的成员变量privateFlags的位WindowManager.LayoutParams.PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED设置为1来强调锁屏界面不受System进程禁用硬件加速的限制。
除了上面提到的两类进程以及一些特殊的UI,其余的就根据Activity窗口自己是否请求了硬件加速渲染而决定是否要为其开启硬件加速。在默认情况下,Activity窗口是请求硬件加速渲染的,也就是参数attrs指向的一个WindowManager.LayoutParams对象的成员变量flags的位WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED是被设置为1的。不过即便如此,也是要设备本身支持硬件加速渲染才行。判断设备是否设置硬件加速渲染可以通过调用HardwareRenderer类的静态成员函数isAvailable来获得。
最后,如果当前创建的窗口支持硬件加速渲染,那么就会调用HardwareRenderer类的静态成员函数create创建一个HardwareRenderer对象,并且保存在与该窗口关联的一个AttachInfo对象的成员变量的成员变量mHardwareRenderer对象。这个HardwareRenderer对象以后将负责执行窗口硬件加速渲染的相关操作。
HardwareRenderer类的静态成员函数create的实现如下所示:
public abstract class HardwareRenderer {
......
static HardwareRenderer create(Context context, boolean translucent) {
HardwareRenderer renderer = null;
if (GLES20Canvas.isAvailable()) {
renderer = new ThreadedRenderer(context, translucent);
}
return renderer;
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/HardwareRenderer.java。
从这里就可以看到,在设备支持Open GL ES 2.0的情况下,HardwareRenderer类的静态成员函数create创建的实际上是一个ThreadedRenderer对象。该ThreadedRenderer对象是从HardwareRenderer类继承下来的。
接下来我们就继续分析ThreadedRenderer对象的创建过程,如下所示:
public class ThreadedRenderer extends HardwareRenderer {
......
private long mNativeProxy;
......
private RenderNode mRootNode;
......
ThreadedRenderer(Context context, boolean translucent) {
......
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
......
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
AtlasInitializer.sInstance.init(context, mNativeProxy);
......
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/ThreadedRenderer.java。
在创建ThreadedRenderer对象的过程中,最主要的是做了三件事情:
1. 调用ThreadedRenderer类的成员函数nCreateRootRenderNode在Native层创建了一个Render Node,并且通过Java层的RenderNode类的静态成员函数adopt将其封装在一个Java层的Render Node中。这个Render Node即为窗口的Root Render Node。
2. 调用ThreadedRenderer类的成员函数nCreateProxy在Native层创建了一个Render Proxy对象。该Render Proxy对象以后将负责从Main Thread向Render Thread发送命令。
3. 调用AtlasInitializer类的成员函数init初始化一个系统预加载资源的地图集。通过这个地图集,可以优化资源的内存使用。
关于系统预加载资源地图集,我们在下一篇文章中再详细分析,这里我们主要关注窗口的Root Render Node以及在Main Thread线程中使用的Render Proxy对象的创建过程。
窗口的Root Render Node是通过调用ThreadedRenderer类的成员函数nCreateRootRenderNode创建的。这是一个JNI函数,由Native层的函数android_view_ThreadedRenderer_createRootRenderNode实现,如下所示:
static jlong android_view_ThreadedRenderer_createRootRenderNode(JNIEnv* env, jobject clazz) {
RootRenderNode* node = new RootRenderNode(env);
node->incStrong(0);
node->setName("RootRenderNode");
return reinterpret_cast<jlong>(node);
}这个函数定义在文件frameworks/base/core/jni/android_view_ThreadedRenderer.cpp中。
从这里就可以看出,窗口在Native层的Root Render Node实际上是一个RootRenderNode对象。
窗口在Main Thread线程中使用的Render Proxy对象是通过调用ThreadedRenderer类的成员函数nCreateProxy创建的。这是一个JNI函数,由Native层的函数android_view_ThreadedRenderer_createProxy实现,如下所示:
static jlong android_view_ThreadedRenderer_createProxy(JNIEnv* env, jobject clazz,
jboolean translucent, jlong rootRenderNodePtr) {
RootRenderNode* rootRenderNode = reinterpret_cast<RootRenderNode*>(rootRenderNodePtr);
ContextFactoryImpl factory(rootRenderNode);
return (jlong) new RenderProxy(translucent, rootRenderNode, &factory);
}这个函数定义在文件frameworks/base/core/jni/android_view_ThreadedRenderer.cpp中。
参数rootRenderNodePtr指向前面创建的RootRenderNode对象。有了这个RootRenderNode对象之后,函数android_view_ThreadedRenderer_createProxy就创建了一个RenderProxy对象。
RenderProxy对象的创建过程如下所示:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())
, mContext(0) {
SETUP_TASK(createContext);
args->translucent = translucent;
args->rootRenderNode = rootRenderNode;
args->thread = &mRenderThread;
args->contextFactory = contextFactory;
mContext = (CanvasContext*) postAndWait(task);
mDrawFrameTask.setContext(&mRenderThread, mContext);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderProxy.cpp中。
RenderProxy类有三个重要的成员变量mRenderThread、mContext和mDrawFrameTask,它们的类型分别为RenderThread、CanvasContext和DrawFrameTask。其中,mRenderThread描述的就是Render Thread,mContext描述的是一个画布上下文,mDrawFrameTask描述的是一个用来执行渲染任务的Task。接下来我们就重点分析这三个成员变量的初始化过程。
RenderProxy类的成员变量mRenderThread指向的Render Thread是通过调用RenderThread类的静态成员函数getInstance获得的。从名字我们就可以看出,RenderThread类的静态成员函数getInstance返回的是一个RenderThread单例。也就是说,在一个Android应用程序进程中,只有一个Render Thread存在。
为了更好地了解Render Thread是如何运行的,我们继续分析Render Thread的创建过程,如下所示:
RenderThread::RenderThread() : Thread(true), Singleton<RenderThread>()
...... {
mFrameCallbackTask = new DispatchFrameCallbacks(this);
mLooper = new Looper(false);
run("RenderThread");
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
RenderThread类的成员变量mFrameCallbackTask指向一个DispatchFrameCallbacks对象,用来描述一个帧绘制任务。下面描述Render Thread的运行模型时,我们再详细分析。
RenderThread类的成员变量mLooper指向一个Looper对象,Render Thread通过它来创建一个消息驱动运行模型,类似于Main Thread的消息驱动运行模型。关于Looper的实现,可以参考前面Android应用程序消息处理机制(Looper、Handler)分析一文。
RenderThread类是从Thread类继承下来的,当我们调用它的成员函数run的时候,就会创建一个新的线程。这个新的线程的入口点函数为RenderThread类的成员函数threadLoop,它的实现如下所示:
bool RenderThread::threadLoop() {
.......
initThreadLocals();
int timeoutMillis = -1;
for (;;) {
int result = mLooper->pollOnce(timeoutMillis);
......
nsecs_t nextWakeup;
// Process our queue, if we have anything
while (RenderTask* task = nextTask(&nextWakeup)) {
task->run();
// task may have deleted itself, do not reference it again
}
if (nextWakeup == LLONG_MAX) {
timeoutMillis = -1;
} else {
nsecs_t timeoutNanos = nextWakeup - systemTime(SYSTEM_TIME_MONOTONIC);
timeoutMillis = nanoseconds_to_milliseconds(timeoutNanos);
if (timeoutMillis < 0) {
timeoutMillis = 0;
}
}
if (mPendingRegistrationFrameCallbacks.size() && !mFrameCallbackTaskPending) {
drainDisplayEventQueue(true);
mFrameCallbacks.insert(
mPendingRegistrationFrameCallbacks.begin(), mPendingRegistrationFrameCallbacks.end());
mPendingRegistrationFrameCallbacks.clear();
requestVsync();
}
}
return false;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
这里我们就可以看到Render Thread的运行模型:
1. 空闲的时候,Render Thread就睡眠在成员变量mLooper指向的一个Looper对象的成员函数pollOnce中。
2. 当其它线程需要调度Render Thread,就会向它的任务队列增加一个任务,然后唤醒Render Thread进行处理。Render Thread通过成员函数nextTask获得需要处理的任务,并且调用它的成员函数run进行处理。
RenderThread类的成员函数nextTask的实现如下所示:
RenderTask* RenderThread::nextTask(nsecs_t* nextWakeup) {
AutoMutex _lock(mLock);
RenderTask* next = mQueue.peek();
if (!next) {
mNextWakeup = LLONG_MAX;
} else {
mNextWakeup = next->mRunAt;
// Most tasks won't be delayed, so avoid unnecessary systemTime() calls
if (next->mRunAt <= 0 || next->mRunAt <= systemTime(SYSTEM_TIME_MONOTONIC)) {
next = mQueue.next();
} else {
next = 0;
}
}
if (nextWakeup) {
*nextWakeup = mNextWakeup;
}
return next;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
RenderThread类的成员变量mQueue描述的是一个Task Queue。每一个Task都是用一个RenderTask对象来描述。同时,RenderTask类有一个成员变量mRunAt,用来表明Task的执行时间。这样,保存在Task Queue的Task就可以按照执行时间从先到后的顺序排序。于是,RenderThread类的成员函数nextTask通过判断排在队列头的Task的执行时间是否小于等于当前时间,就可以知道当前是否有Task需要执行。如果有Task需要执行的话,就将它返回给调用者。
RenderThread类的成员函数nextTask除了返回下一个要执行的Task之外,还会通过参数nextWakeup返回下一个要执行的Task的执行时间。这个时间同时也会记录在RenderThread类的成员变量mNextWakeup中。注意,下一个要执行的Task可能是马上就要执行的,也有可能是由于执行时间还未到而不能执行的Task。返回这个时间的意义是使得Render Thread可以准确计算下一次需要进入睡眠状态的时间。这个计算可以回过头去看前面分析的RenderThread类的成员函数threadLoop。
注意,如果没有下一个任务可以执行,那么RenderThread类的成员函数nextTask通过参数nextWakeup返回的值为LLONG_MAX,表示Render Thread接下来无限期进入睡眠状态,直到被其它线程唤醒为止。
RenderThread类提供了queue、queueAtFront和queueDelayed三个成员函数向Task Queue增加一个Task,它们的实现如下所示:
void RenderThread::queue(RenderTask* task) {
AutoMutex _lock(mLock);
mQueue.queue(task);
if (mNextWakeup && task->mRunAt < mNextWakeup) {
mNextWakeup = 0;
mLooper->wake();
}
}
void RenderThread::queueAtFront(RenderTask* task) {
AutoMutex _lock(mLock);
mQueue.queueAtFront(task);
mLooper->wake();
}
void RenderThread::queueDelayed(RenderTask* task, int delayMs) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
task->mRunAt = now + milliseconds_to_nanoseconds(delayMs);
queue(task);
}这三个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
其中, RenderThread类的成员函数queue按照执行时间将参数task描述的Task排列在Task Queue中,并且如果该Task的执行时间小于之前记录的下一个要执行任务的执行时间,就会马上唤醒Render Thread来处理;RenderThread类的成员函数queue将参数task描述的Task排列在Task Queue的头部,并且马上唤醒Render Thread来处理;RenderThread类的成员函数queueDelayed指定参数task描述的Task的执行时间为当前时间之后的delayMs毫秒。
理解了Render Thread的Task Queue之后,回到RenderThread类的成员函数threadLoop中,我们再来看Render Thread在进入无限循环之前调用的RenderThread类的成员函数initThreadLocals,它的实现如下所示:
void RenderThread::initThreadLocals() {
initializeDisplayEventReceiver();
mEglManager = new EglManager(*this);
mRenderState = new RenderState();
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
RenderThread类的成员函数initThreadLocals首先调用另外一个成员函数initializeDisplayEventReceiver创建和初始化一个DisplayEventReceiver对象,用来接收Vsync信号。接着又会分别创建一个EglManager对象和一个RenderState对象,并且保存在成员变量mEglManager和mRenderState中。前者用在初始化Open GL渲染上下文需要用到,而后者用来记录Render Thread当前的一些渲染状态。
接下来我们主要关注DisplayEventReceiver对象的创建和初始化过程,即RenderThread类的成员函数initializeDisplayEventReceiver的实现,如下所示:
void RenderThread::initializeDisplayEventReceiver() {
......
mDisplayEventReceiver = new DisplayEventReceiver();
......
// Register the FD
mLooper->addFd(mDisplayEventReceiver->getFd(), 0,
Looper::EVENT_INPUT, RenderThread::displayEventReceiverCallback, this);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
创建的DisplayEventReceiver对象关联的文件描述符被注册到了Render Thread的消息循环中。这意味着屏幕产生Vsync信号时,SurfaceFlinger服务(Vsync信号由SurfaceFlinger服务进行管理和分发)会通过上述文件描述符号唤醒Render Thread。这时候Render Thread就会调用RenderThread类的静态成员函数displayEventReceiverCallback。
RenderThread类的静态成员函数displayEventReceiverCallback的实现如下所示:
int RenderThread::displayEventReceiverCallback(int fd, int events, void* data) {
......
reinterpret_cast<RenderThread*>(data)->drainDisplayEventQueue();
return 1; // keep the callback
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
RenderThread类的静态成员函数displayEventReceiverCallback调用RenderThread类的成员函数drainDisplayEventQueue来处理Vsync信号,后者的实现如下所示:
void RenderThread::drainDisplayEventQueue(bool skipCallbacks) {
......
nsecs_t vsyncEvent = latestVsyncEvent(mDisplayEventReceiver);
if (vsyncEvent > 0) {
mVsyncRequested = false;
mTimeLord.vsyncReceived(vsyncEvent);
if (!skipCallbacks && !mFrameCallbackTaskPending) {
......
mFrameCallbackTaskPending = true;
queueDelayed(mFrameCallbackTask, DISPATCH_FRAME_CALLBACKS_DELAY);
}
}
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
RenderThread类的成员函数drainDisplayEventQueue首先调用另外一个成员函数latestVsyncEvent获得最新发出的Vsync信号的时间。如果这个时间值大于0,那么就表明这是一个有效的Vsync信号。在这种情况下,就将RenderThread类的成员变量mVsyncRequested设置为false,表示上次发出的Vsync信号接收请求已经获得。
最后,如果参数skipCallbacks的值等于false,那么就表示需要将RenderThread类的成员变量mFrameCallbackTask指向的一个类型为DispatchFrameCallbacks的Task添加到Render Thread的Task Queue去处理。但是这时候如果RenderThread类的成员变量mFrameCallbackTaskPending的值也等于true,就表示该Task已经添加到Render Thread的Task Queue去了,因此就不再用重复添加。
RenderThread类的成员变量mFrameCallbackTask描述的Task是用来做什么的呢?原来就是用来显示动画的。当Java层注册一个动画类型的Render Node到Render Thread时,一个类型为IFrameCallback的回调接口就会通过RenderThread类的成员函数postFrameCallback注册到Render Thread的一个Pending Registration Frame Callbacks列表中,如下所示:
void RenderThread::postFrameCallback(IFrameCallback* callback) {
mPendingRegistrationFrameCallbacks.insert(callback);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
Render Thread的Pending Registration Frame Callbacks列表由RenderThread类的成员变量mPendingRegistrationFrameCallbacks描述。
当Pending Registration Frame Callbacks列表不为空时,每次Vsync信号到来时,Render Thread都会通过RenderThread类的成员变量mFrameCallbackTask描述的一个Task来执行它,这样就相当于是将动画的每一帧都同步到Vsync信号来显示。这也是为什么RenderThread类的成员函数drainDisplayEventQueue每次被调用要检查是否需要将成员变量mFrameCallbackTask描述的一个Task添加到Render Thread的Task Queue的原因。
当RenderThread类的成员变量mFrameCallbackTask描述的Task的类型为DispatchFrameCallbacks,当它被调度执行时,它的成员函数run就会被调用,如下所示:
class DispatchFrameCallbacks : public RenderTask {
private:
RenderThread* mRenderThread;
public:
DispatchFrameCallbacks(RenderThread* rt) : mRenderThread(rt) {}
virtual void run() {
mRenderThread->dispatchFrameCallbacks();
}
};这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
DispatchFrameCallbacks类的成员函数run调用了RenderThread类的成员函数dispatchFrameCallbacks来执行注册到Pending Registration Frame Callbacks列表中的IFrameCallback回调接口,如下所示:
void RenderThread::dispatchFrameCallbacks() {
ATRACE_CALL();
mFrameCallbackTaskPending = false;
std::set<IFrameCallback*> callbacks;
mFrameCallbacks.swap(callbacks);
for (std::set<IFrameCallback*>::iterator it = callbacks.begin(); it != callbacks.end(); it++) {
(*it)->doFrame();
}
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderThread.cpp中。
我们回过头来看前面分析的RenderThread类的成员函数threadLoop,每当Render Thread被唤醒时,它都会检查Pending Registration Frame Callbacks列表是否不为空。如果不为空,那么就会将保存在里面的IFrameCallback回调接口转移至由RenderThread类的成员变量mFrameCallbacks描述的另外一个IFrameCallback回调接口列表中,并且调用RenderThread类的另外一个成员函数requestVsync请求SurfaceFlinger服务在下一个Vsync信号到来时通知Render Thread,以便Render Thread可以执行刚才被转移的IFrameCallback回调接口。
现在既然下一个Vsync信号已经到来,因此RenderThread类的成员函数dispatchFrameCallbacks就执行所有转移至保存在成员变量mFrameCallbacks描述的IFrameCallback回调接口列表中的IFrameCallback接口,即调用它们的成员函数doFrame。
总结来说,Render Thread在运行时主要是做以下两件事情:
1. 执行Task Queue的任务,这些Task一般就是由Main Thread发送过来的,例如,Main Thread通过发送一个Draw Frame Task给Render Thread的Task Queue中,请求Render Thread渲染窗口的下一帧。
2. 执行Pending Registration Frame Callbacks列表的IFrameCallback回调接口。每一个IFrameCallback回调接口代表的是一个动画帧,这些动画帧被同步到Vsync信号到来由Render Thread自动执行。具体来说,就是每当Vsync信号到来时,就将一个类型为DispatchFrameCallbacks的Task添加到Render Thread的Task Queue去等待调度。一旦该Task被调度,就可以在Render Thread中执行注册在Pending Registration Frame Callbacks列表中的IFrameCallback回调接口了。
在后面的文章中,我们还会继续分析上述这两件事情的详细执行过程。
了解了Render Thread的创建过程之后,回到RenderProxy类的构造函数中,接下来我们继续分析它的成员变量mContext的初始化过程,也就是画布上下文的初始化过程。这是通过向Render Thread发送一个createContext命令来完成的。为了方便描述,我们将相关的代码列出来,如下所示:
#define ARGS(method) method ## Args
#define CREATE_BRIDGE4(name, a1, a2, a3, a4) CREATE_BRIDGE(name, a1,a2,a3,a4,,,,)
#define CREATE_BRIDGE(name, a1, a2, a3, a4, a5, a6, a7, a8) \
typedef struct { \
a1; a2; a3; a4; a5; a6; a7; a8; \
} ARGS(name); \
static void* Bridge_ ## name(ARGS(name)* args)
#define SETUP_TASK(method) \
.......
MethodInvokeRenderTask* task = new MethodInvokeRenderTask((RunnableMethod) Bridge_ ## method); \
ARGS(method) *args = (ARGS(method) *) task->payload()
CREATE_BRIDGE4(createContext, RenderThread* thread, bool translucent,
RenderNode* rootRenderNode, IContextFactory* contextFactory) {
return new CanvasContext(*args->thread, args->translucent,
args->rootRenderNode, args->contextFactory);
}
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
...... {
SETUP_TASK(createContext);
args->translucent = translucent;
args->rootRenderNode = rootRenderNode;
args->thread = &mRenderThread;
args->contextFactory = contextFactory;
mContext = (CanvasContext*) postAndWait(task);
......
}这些代码片断定义在文件frameworks/base/libs/hwui/renderthread/RenderProxy.cpp。
这是一个典型的Main Thread通过Render Proxy向Render Thread请求执行一个命令的流程,在后面的文章中,碰到类型的代码时,我们就将忽略中间的封装环节,直接分析命令的执行过程。
我们首先看宏SETUP_TASK,它需要一个函数作为参数。这个函数通过CREATE_BRIDGEX来声明,其中X是一个数字,数字的大小就等于函数需要的参数的个数。例如,通过CREATE_BRIDGE4声明的函数有4个参数。在上面的代码段中,我们通过CREATE_BRIDGE4宏声明了一个createContext函数。
宏SETUP_TASK的作用创建一个类型MethodInvokeRenderTask的Task。这个Task关联有一个由CREATE_BRIDGEX宏声明的函数。例如,SETUP_TASK(createContext)创建的MethodInvokeRenderTask关联的函数是由CREATE_BRIDGE4声明的函数createContext。这个Task最终会通过RenderProxy类的成员函数postAndWait添加到Render Thread的Task Queue中,如下所示:
void* RenderProxy::postAndWait(MethodInvokeRenderTask* task) {
void* retval;
task->setReturnPtr(&retval);
SignalingRenderTask syncTask(task, &mSyncMutex, &mSyncCondition);
AutoMutex _lock(mSyncMutex);
mRenderThread.queue(&syncTask);
mSyncCondition.wait(mSyncMutex);
return retval;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderProxy.cpp。
RenderProxy类的成员函数postAndWait除了会将参数task描述MethodInvokeRenderTask描述的Task添加到Render Thread的Task Queue之外,还会等待该Task执行完成之后才返回。也就是说,这是一个从Main Thread到Render Thread的同步调用过程。
当MethodInvokeRenderTask被执行时,它所关联的函数就会被调用。例如,在我们这个情景中,通过CREATE_BRIDGE4声明的函数createContext就会被执行。注意,这时候函数createContext是在Render Thread中执行的,它主要就是创建一个CanvasContext对象,用来描述Render Thread的画布上下文。这个画布上下文接下来在Render Thread中绑定窗口时会用到,到时候我们就可以更清楚地看到它的作用。
回到RenderProxy类的构造函数中,接下来我们继续分析它的成员变量mDrawFrameTask的初始化过程。RenderProxy类的成员变量mDrawFrameTask描述的是一个Draw Frame Task,Main Thread每次都是通过它来向Render Thread发出渲染下一帧的命令的。
对Draw Frame Task的初始化很简单,主要是将前面已经获得的RenderThread对象和CanvasContext对象保存在它内部,以便以后它可以直接使用相关的功能,这是通过调用DrawFrameTask类的成员函数setContext实现的,如下所示:
void DrawFrameTask::setContext(RenderThread* thread, CanvasContext* context) {
mRenderThread = thread;
mContext = context;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp中。
这样,一个RenderProxy对象的创建过程就分析完成了,从中我们也看到Render Thread的创建过程和运行模型,以及Render Proxy与Render Thread的交互模型,总结来说:
-
RenderProxy内部有一个成员变量mRenderThread,它指向的是一个RenderThread对象,通过它可以向Render Thread线程发送命令。
-
RenderProxy内部有一个成员变量mContext,它指向的是一个CanvasContext对象,Render Thread的渲染工作就是通过它来完成的。
- RenderProxy内部有一个成员变量mDrawFrameTask,它指向的是一个DrawFrameTask对象,Main Thread通过它向Render Thread线程发送渲染下一帧的命令。
接下来我们继续分析Android应用程序UI硬件加速渲染环境初始化的另一个主要任务--绑定窗口到Render Thread中。
从前面Android应用程序窗口(Activity)的测量(Measure)、布局(Layout)和绘制(Draw)过程分析这篇文章可以知道,Activity窗口的绘制流程是在ViewRoot(Impl)类的成员函数performTraversals发起的。在绘制之前,首先要获得一个Surface。这个Surface描述的就是一个窗口。因此,一旦获得了对应的Surface,就需要将它绑定到Render Thread中,如下所示:
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, HardwareRenderer.HardwareDrawCallbacks {
......
private void performTraversals() {
......
if (mFirst || windowShouldResize || insetsChanged ||
viewVisibilityChanged || params != null) {
......
try {
......
relayoutResult = relayoutWindow(params, viewVisibility, insetsPending);
......
if (!hadSurface) {
if (mSurface.isValid()) {
......
if (mAttachInfo.mHardwareRenderer != null) {
try {
hwInitialized = mAttachInfo.mHardwareRenderer.initialize(
mSurface);
} catch (OutOfResourcesException e) {
......
}
}
}
}
......
} catch (RemoteException e) {
}
......
}
if (!cancelDraw && !newSurface) {
if (!skipDraw || mReportNextDraw) {
......
performDraw();
}
}
......
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/ViewRootImpl.java中。
当前Activity窗口对应的Surface是通过调用ViewRootImpl类的成员函数relayoutWindow向WindowManagerService服务请求创建和返回的,并且保存在ViewRootImpl类的成员变量mSurface中。如果这个Surface是新创建的,那么就会调用ViewRootImpl类的成员变量mAttachInfo指向的一个AttachInfo对象的成员变量mHardwareRenderer描述的一个HardwareRenderer对象的成员函数initialize将它绑定到Render Thread中。最后,如果需要绘制当前的Activity窗口,那会调用ViewRootImpl类的另外一个成员函数performDraw进行绘制。
这里我们只关注绑定窗口对应的Surface到Render Thread的过程。从前面的分析可以知道,ViewRootImpl类的成员变量mAttachInfo指向的一个AttachInfo对象的成员变量mHardwareRenderer保存的实际上是一个ThreadedRenderer对象,它的成员函数initialize的实现如下所示:
public class ThreadedRenderer extends HardwareRenderer {
......
@Override
boolean initialize(Surface surface) throws OutOfResourcesException {
mInitialized = true;
......
boolean status = nInitialize(mNativeProxy, surface);
......
return status;
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/ThreadedRenderer.java中。
ThreadedRenderer类的成员函数initialize首先将成员变量mInitialized的值设置为true,表明它接下来已经绑定过Surface到Render Thread了,接着再调用另外一个成员函数nInitialize执行真正的绑定工作。
ThreadedRenderer类的成员函数nInitialize是一个JNI函数,由Native层的函数android_view_ThreadedRenderer_initialize实现,如下所示:
static jboolean android_view_ThreadedRenderer_initialize(JNIEnv* env, jobject clazz,
jlong proxyPtr, jobject jsurface) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
sp<ANativeWindow> window = android_view_Surface_getNativeWindow(env, jsurface);
return proxy->initialize(window);
}这个函数定义在文件frameworks/base/core/jni/android_view_ThreadedRenderer.cpp中。
参数proxyPtr描述的就是之前所创建的一个RenderProxy对象,而参数jsurface描述的是要绑定给Render Thread的Java层的Surface。前面提到,Java层的Surface在Native层对应的是一个ANativeWindow。我们可以通过函数android_view_Surface_getNativeWindow来获得一个Java层的Surface在Native层对应的ANativeWindow。
接下来,就可以通过RenderProxy类的成员函数initialize将前面获得的ANativeWindow绑定到Render Thread中,如下所示:
CREATE_BRIDGE2(initialize, CanvasContext* context, ANativeWindow* window) {
return (void*) args->context->initialize(args->window);
}
bool RenderProxy::initialize(const sp<ANativeWindow>& window) {
SETUP_TASK(initialize);
args->context = mContext;
args->window = window.get();
return (bool) postAndWait(task);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderProxy.cpp中。
从前面的分析可以知道,RenderProxy类的成员函数initialize向Render Thread的Task Queue发送了一个Task。当这个Task在Render Thread中执行时,由宏CREATE_BRIDGE2声明的函数initialize就会被执行。
在由宏CREATE_BRIDGE2声明的函数initialize中,参数context指向的是RenderProxy类的成员变量mContext指向的一个CanvasContext对象,而参数window指向的ANativeWindow就是要绑定到Render Thread的ANativeWindow。
由宏CREATE_BRIDGE2声明的函数initialize通过调用参数context指向的CanvasContext对象的成员函数initialize来绑定参数window指向的ANativeWindow,如下所示:
bool CanvasContext::initialize(ANativeWindow* window) {
setSurface(window);
if (mCanvas) return false;
mCanvas = new OpenGLRenderer(mRenderThread.renderState());
......
return true;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/CanvasContext.cpp中。
CanvasContext类的成员函数initialize通过调用另外一个成员函数setSurface来绑定参数window描述的ANativeWindow到Render Thread中。绑定完成之后,如果CanvasContext类的成员变量mCanvas等于NULL,那么就说明负责执行Open GL渲染命令的一个OpenGLRenderer对象还没创建。在这种情况下,就创建一个OpenGLRenderer对象,并且保存在CanvasContext类的成员变量mCanvas中,以便后面可以用来执行Open GL相关操作。
CanvasContext类的成员函数setSurface的实现如下所示:
void CanvasContext::setSurface(ANativeWindow* window) {
mNativeWindow = window;
if (mEglSurface != EGL_NO_SURFACE) {
mEglManager.destroySurface(mEglSurface);
mEglSurface = EGL_NO_SURFACE;
}
if (window) {
mEglSurface = mEglManager.createSurface(window);
}
if (mEglSurface != EGL_NO_SURFACE) {
......
mHaveNewSurface = true;
makeCurrent();
}
......
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/CanvasContext.cpp中。
每一个Open GL渲染上下文都需要关联有一个EGL Surface。这个EGL Surface描述的是一个绘图表面,它封装的实际上是一个ANativeWindow。有了这个EGL Surface之后,我们在执行Open GL命令的时候,才能确定这些命令是作用在哪个窗口上。
CanvasContext类的成员变量mEglManager实际上是指向前面我们分析RenderThread类的成员函数initThreadLocals时创建的一个EglManager对象。通过调用这个EglManager对象的成员函数createSurface就可以将参数window描述的ANativeWindow封装成一个EGL Surface。
EGL Surface创建成功之后,就可以调用CanvasContext类的成员函数makeCurrent将它绑定到Render Thread的Open GL渲染上下文来,如下所示:
void CanvasContext::makeCurrent() {
// TODO: Figure out why this workaround is needed, see b/13913604
// In the meantime this matches the behavior of GLRenderer, so it is not a regression
mHaveNewSurface |= mEglManager.makeCurrent(mEglSurface);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/CanvasContext.cpp中。
从这里就可以看到,将一个EGL Surface绑定到Render Thread的Open GL渲染上下文中是通过CanvasContext类的成员变量mEglManager指向的一个EglManager对象的成员函数makeCurrent来完成的。实际上就是通过EGL函数建立了从Open GL到底层OS图形系统的桥梁。这一点应该怎么理解呢?Open GL是一套与OS无关的规范,不过当它在一个具体的OS实现时,仍然是需要与OS的图形系统打交道的。例如,Open GL需要从底层的OS图形系统中获得图形缓冲区来保存渲染结果,并且也需要将渲染好的图形缓冲区交给底层的OS图形系统来显示到设备屏幕去。Open GL与底层的OS图形系统的这些交互通道都是通过EGL函数来建立的。
至此,将当前窗口绑定到Render Thread的过程就分析完成了,整个Android应用程序UI硬件加速渲染环境的初始化过程也分析完成了。前面在分析ThreadedRenderer对象的创建过程时提到了系统预加载资源地图集的概念,在继续分析Android应用程序UI硬件加速渲染的Display List构建和渲染过程之前,我们有必要先分析这个地图集的概念,因为这是Display List在渲染时涉及到的一个重要优化,敬请关注!更多的信息也可以参考老罗的新浪微博:http://weibo.com/shengyangluo。