微信图片智能裁剪技术介绍
微信的公众号、视频号等产品每天有大量的图片内容,这些图片的长宽比各异,但是为了展示的美观性,在产品的某些场景需要固定图片长宽比,这就需要算法对图片自动剪裁。我们自研了一款轻量的图片智能裁剪框架,基于艺术美学分析与深度学习技术,自动判断图片主体区域,裁剪图片以适配不同尺寸要求。目前该算法已经在微信公众号的快讯、推荐流、图片落地页等多个场景中落地应用,取得了不错的业务收益。同时该方法也被 AAAI 2024 会议接收录用。
一、 背景介绍
图片裁剪的目的是自动挖掘图片中最具美观的视图,广泛应用于图片美学构图,例如缩略 图生成[1]、摄影辅助[2]和肖像推荐[3]等。其中,图片缩略图或封面裁剪是新兴的 User Generated Content (UGC) 领域的重要应用。

如上图公众号业务所示,需要将原图裁剪为一个 3:4 的尺寸图片作为文章封面展示。而封 面图的美观与完整性决定了用户是否愿意点击进入文章阅读,并直接影响文章或帖子的点击 率。同时,图片裁剪的输出尺寸(如 1:1,16:9,3:4 等)会随着业务的更替变化而进行切换。所以,设计一款轻量并且可以适配不同尺寸要求的通用图片智能裁剪模型是十分必要的。
二、 挑战与困难

由于用户使用不同类型的拍摄设备或不同长宽比的镜头将自己拍摄制作的图片或视频上传 到社交媒体平台,这需要裁剪算法生成固定的长宽比封面图片展示到前端,以实现内容美观和 格式统一 ,如上图所示(每个图片上方都标有 UGC 的原始尺寸。为了直观解释,红色虚线框 表示我们的算法针对固定长宽比生成的裁剪图片)。相对比学术上的数据集图片或者是网络上 一些简单的单一物体图片,UGC 图片裁剪的主要挑战与困难有四个方面:
- UGC 图片五花八门更加复杂,具有不同的多物体前景和混乱的背景,因此有必要挖掘不同 物体之间的关系以找到最具美感的区域。同时,一些基于显著性的裁剪方法[4][5]可能会无 法准确定位图片中的主体,从而导致裁剪内容不美观;
- 除了确保裁剪图片的美观之外,内容的完整性也至关重要,它向观看者传达了主要信息。如图上图(b)所示,对于一些新闻片段或歌词视频封面,裁剪目标应保留图片中除人物外的 主要属性,如新闻标题和完整歌词。对于多人图片,应避免人脸不完整的情况;
- UGC 裁剪通常需要固定宽高比的图片输出显示,如适应上图(a)所示手机端的竖屏显示和图 (b)中 PC 端的横屏展示。因此,一些基于锚点生成的方法[6][7]是不合用于该业务场景,因 为它们模仿目标检测的范式,并没有产生有约束的宽高比的候选视图,这不可避免地大大 降低了它们在实际业务场景中的应用价值;
- 在微信平台下,每天新增的 UGC 图片是非常多的,这要求图片裁剪模型需要有快速的响 应,并且工程部署成本低,以处理每天社交媒体上大量的图片内容。
三、 模型简介
模型结构方面我们重新设计了一款名为 Spatial-Semantic Collaborative Cropping Network (S2CNet),目前此项工作已经被 AAAI 2024 接收并录用。

我们的动机是建立裁剪候选框和所有对象间的组合关系。对于裁剪候选框中的元素,我们 尝试使网络捕获视觉上相互的依赖关系。而对于一些不确定的背景物体,我们学会保留有吸引 力的部分,同时去除多余的部分。为了实现这一目标,我们采用自适应注意力图(AAG)来对 区域内容之间的可扩展连接进行建模,而不是使用普通的 transformer 来对视觉像素进行同等 的建模。具体网络特点如下:
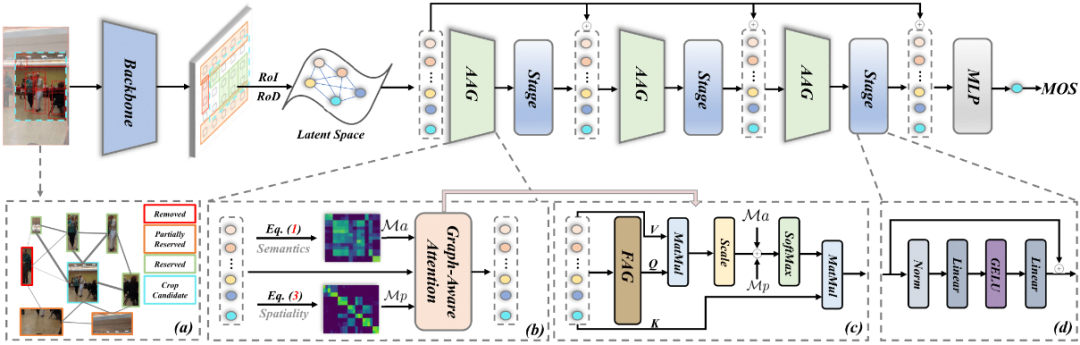
1 Detetction-Head
给定预设定的裁剪框(模仿文献[8][9])以及对应的输入图片作为输入,我们首先利用在 Visual Genome 预训练好的的 Yolov6 检测器来挖掘 Top-K 的潜在视觉对象,如上图(a)所示;
2 Light-weight Backbone
我们通过将图片传递到轻量的卷积主干网络来获得特征图 feature map;
3 RoIAlign + RoDAlign
我们应用 RoIAlign (RoI) 和 RoDAlign (RoD) 进行池化操作,获取每个潜在对象区域以及裁剪框区域的特征,后续视为 node 节点输送给图卷积网络;
4 Adaptive Attention Graph(AGG)
不同的节点特征输入到提出的网络中以捕获高阶信息。最后通过聚合更新的特征来预测美 学分数(MOS)。其中 AAG 模块如上图(b)所示,是一个变种的 transformer 模块。我们综合地 考虑了不同图片节点 feature 之间的外观语义和空间距离关系。具体地,我们构建了两个 Ma 和 Mp 相似度矩阵,分别代表 appearance 和 position similarity。图片节点 token 首先经过一 个 FAG 图卷积模块,其作用是动态生成具有适当重要性的 token 来执行后续的图形理解。随 后,在我们的 AAG 模块中,我们将 Ma 和 Mp 相似度矩阵融入到 self-attention 当中,如下公 式所示:
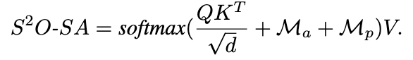
数据集中为每个预定义裁剪框打好了美学分数,我们通过标注数据端到端训练网络,最终 通过排序美学得分便可以输出得分最高的裁剪框。假如在固定尺寸比例约束下,可以首先过滤 预定义的裁剪框,保留符合特定比例的裁剪框输送进入网络进行计算。
四、 模型效果
1、 定量分析
目前我们的网络在学术集最权威的 3 个数据集都获得 SOTA 的成绩:
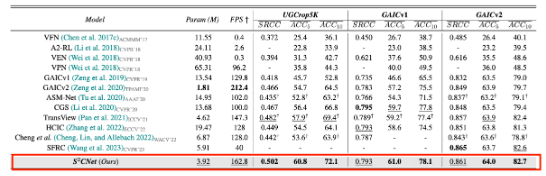
- UGCrop5k 数据集:包含 5k 张高质量的 UGC 封面图,涵盖日常活动、体育、音乐、娱乐、 vlog 等方面;
- GAICv1 数据集:包含 1k 张主要涵盖风景类别的图片,主要偏向摄影类的风格,以衡量构 图美观为主;
- GAICv2 数据集:在上述 GAICv1 数据集基础上额外添加了 2k 张图片,新增更多的人文风景 图片,主要也是偏向摄影构图美观为主;
2、 定性分析:
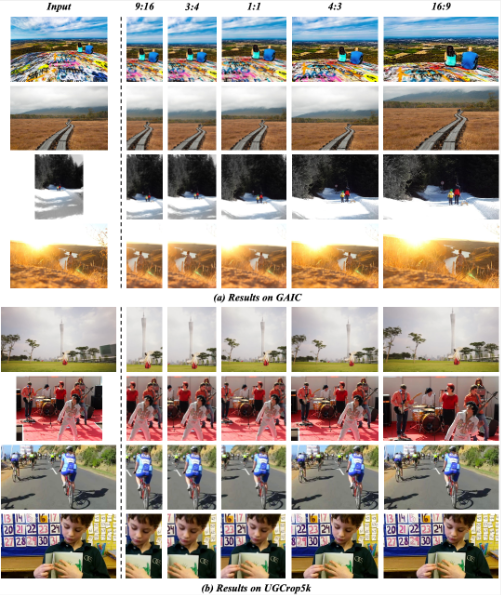
下图展示了定性比较,从中我们可以观察到:

- 我们的方法可以产生更美观的裁剪视图。它们不仅保留了照片的主要前景,而且可以更大程度地有效保留或去除背景的某些区域以进行构图,并且最终的裁剪效果与数据集中的Ground-Truth标注更加吻合;
- 我们的方法可以保持图片内容的完整性。如图最后一行所示,虽然其他方法成功地裁剪了主要人物并获得了相对较好的视图,但它们丢失了图片的一些有用属性,这可能会向用户传递不完整的信息。换句话说,裁剪除了保持图片美观之外,还需要保证内容的完整性,这一点在UGC裁剪中尤为重要。
3、 固定尺寸裁剪
在实际应用中,裁剪通常是在特定约束条件下进行的。基于此,我们使用不同的常见长宽比来可视化裁剪结果。如下图所示,我们的模型可以在不同的约束下找到好的裁剪视图,这证 明了我们的模型的能力能够满足 UGC 裁剪的需求,包括封面图片裁剪、缩略图和图标生成。
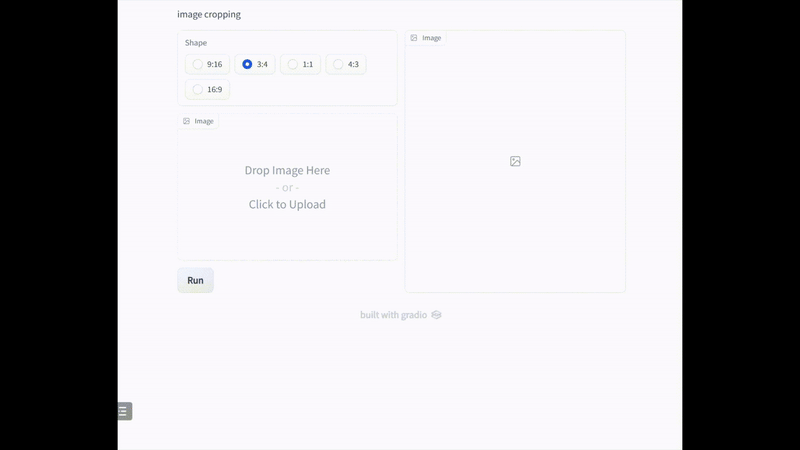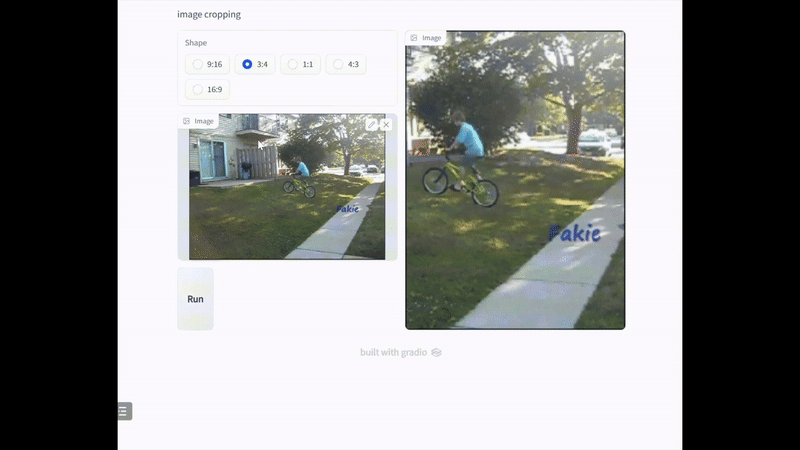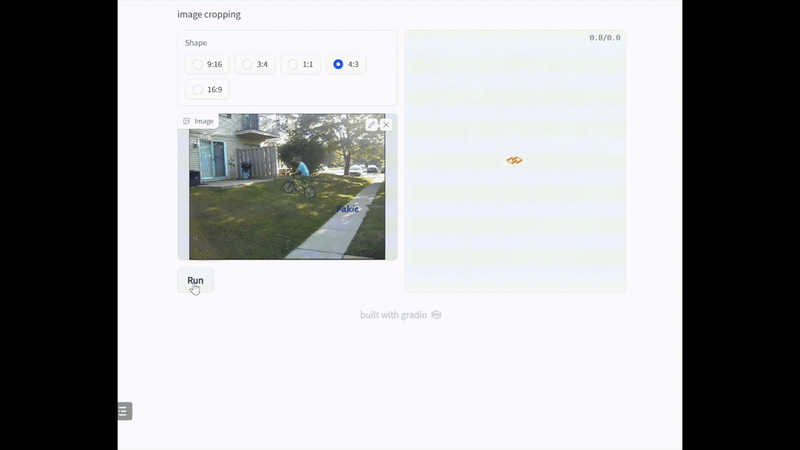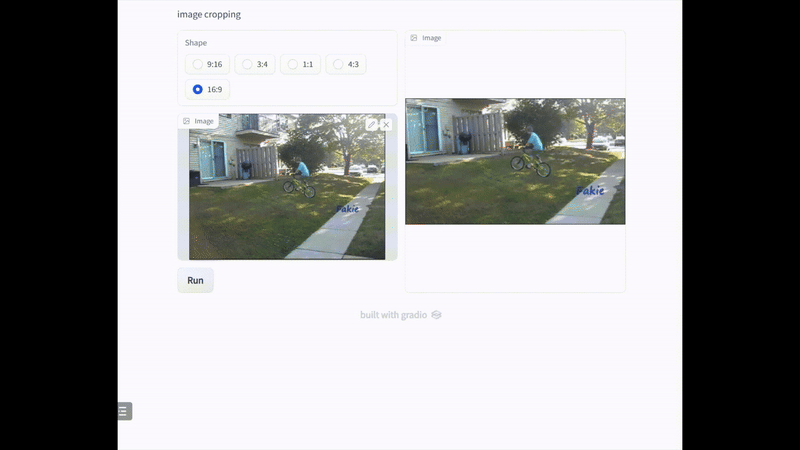
五、 业务应用
目前,我们提出的图片智能裁剪技术已经在微信公众号的快讯、推荐流、图片落地页等多 个场景中落地应用。我们的服务支持任意比例的裁剪,包括常见的 1:1、3:4、4:3、16:9、9:16 等比例,同时也支持定制化的特殊比例要求裁剪。我们服务响应速度可以满足绝大数场景,CPU 单机服务器 QPS 可以达到 100 左右。大盘实验下产品曝光点击率显著提升,线上应用效 果如下图所示。

六、 总结与展望
图片裁剪作为基础的视觉能力已经成为社交内容平台一个必要的功能,用于以更加经济且 更适合布局的方式展示图片。通过在线调整图片的构图,可以辅助实现精准的二次构图。我们 也将持续跟进业界发展,随时适配不同的业务发展,不断迭代优化,也希望和业界的其他同行 进行更加深入的交流学习,一起为社区打造更智能的图片基础服务。
注:文中涉及样本图片均来自公开数据集
参考文献
- [1] Chen, Huarong, et al. "CropNet: Real-time thumbnailing." Proceedings of the 26th ACM international conference on Multimedia. 2018.
- [2] Wei, Zijun, et al. "Good view hunting: Learning photo composition from dense view pairs." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- [3] Zhang, Xiaoyan, et al. "Pose-based composition improvement for portrait photographs." IEEE Transactions on Circuits and Systems for Video Technology 29.3 (2018): 653-668.
- [4] Tu, Yi, et al. "Image cropping with composition and saliency aware aesthetic score map." Proceedings of the AAAI conference on artificial intelligence. Vol. 34. No. 07. 2020.
- [5] Cheng, Yang, Qian Lin, and Jan P. Allebach. "Re-compose the image by evaluating the crop on more than just a score." Proceedings of the IEEE/CVF Winter Conference on Applications ofComputer Vision. 2022.
- [6] Hong, Chaoyi, et al. "Composing photos like a photographer." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
- [7] Jia, Gengyun, et al. "Rethinking image cropping: Exploring diverse compositions from global views." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- [8] Zeng, Hui, et al. "Reliable and efficient image cropping: A grid anchor based approach." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
- [9] Zeng, Hui, et al. "Grid anchor based image cropping: A new benchmark and an efficient model." IEEE Transactions on Pattern Analysis and Machine Intelligence 44.3 (2020): 1304-1319.