提升ChatGPT性能的实用指南:Prompt Engineering的艺术
一起探索 Prompt Engineering 的奥秘,并学习如何用它来让 ChatGPT 发挥出最大的潜力。
什么是提示工程?
提示工程是一门新兴学科,就像是为大语言模型(LLM)设计的"语言游戏"。通过这个"游戏",我们可以更有效地引导 LLM 来处理问题。只有熟悉了这个游戏的规则,我们才能更清楚地认识到 LLM 的能力和局限。
这个"游戏"不仅帮助我们理解 LLM,它也是提升 LLM 能力的途径。有效的提示工程可以提高大语言模型处理复杂问题的能力(比如一些数学推理问题),也可以提高大语言模型的扩展性(比如可以结合专业领域的知识和外部工具,来提升 LLM 的能力)。
提示工程就像是一把钥匙,为我们理解和应用大语言模型打开了新的大门,无论是现在还是未来,它的潜力都是无穷无尽的。
提示工程基础
提示四要素
通常一个 Prompt 会包含以下四个元素中的若干个:
- 指令:希望 LLM 执行什么任务
- 上下文:给 LLM 提供一些额外的信息,比如可以是垂直领域信息,从而引导 LLM 给出更好的回答
- 输入数据:希望从 LLM 得到什么内容的回答
- 输出格式:引导 LLM 给出指定格式的输出
通用技巧
由浅入深
设计提示词经常是一个迭代的过程,需要不断试验才能获得最佳结果。你可以从简单的提示词开始,随着实验深入,逐步添加更多的元素和上下文。在处理复杂任务时,可以将任务分解为简单的子任务,逐步构建并优化。
比如你想让一个语言模型来写一首关于春天的诗。一个简单的提示词可能是:“写一首关于春天的诗。” 随着你对模型输出的观察,你可能发现需要更具体的指示,例如:“写一首四行关于春天的诗,用押韵的方式。”
明确指令
设计有效的提示词,最好是使用明确的命令来指导模型完成你想要的任务,如“写作”,“分类”,“总结”,“翻译”,“排序”等。然后,根据具体任务和应用场景,尝试使用不同的关键词、上下文和数据,找出最佳的组合。
假设你希望模型能够将一段英文翻译成中文。你可以开始使用这样的提示词:“将以下文本翻译成中文”,接着提供你要翻译的英文段落。然而,如果你希望翻译的更具有正式感,你可能需要添加更多上下文:“将以下的正式英文报告翻译成同等正式的中文。”
明确细节
当你需要模型执行特定任务或生成特定风格的内容时,详细且明确的提示词会得到更好的结果。
如果你想要模型生成一段描述美食的文本,你可能会这样指示:“描述一道美味的意大利面。”但是,如果你希望得到关于某个特定菜品的详细描述,你可能需要指示得更具体:“描述一道由新鲜番茄、大蒜、橄榄油和罗勒叶制成的意大利面的味道和口感。”
明确需求
这里的明确类似于给 LLM 限定一些范围,而不是泛泛而谈。
比如你可能希望模型解释一个科学概念,例如:“解释相对论。”但如果你需要用非专业的语言来描述,你可能需要更明确的指示:“用易于理解的非科学语言解释爱因斯坦的相对论。”
正向引导,避免反向限制
设计提示词时,避免指示模型不要做什么,而是明确告诉它应该做什么。这将鼓励更多的确定性,并聚焦于引导模型产生好的回应。
例如,你正在设计一个电影推荐的聊天机器人。一种可能的提示词是:“推荐一部电影,但不要询问任何个人信息。”然而,更有效的提示可能是:“根据全球热门电影推荐一部电影。”
简单提示解析
- 场景:写一个关于自己的介绍
提示:"Reid 的简历:[粘贴完整的简历在这里]。根据以上信息,写一个关于 Reid 的风趣的演讲者简介。"
分析:这个提示直接提供了 LLM 所需的信息,使得 LLM 能够根据给定的信息来编写一段介绍,并明确了简历的风格和用途。
- 场景:用五个要点总结一篇文章
提示:"[在这里粘贴全文]。总结上面文章的内容,用五个要点。" 分析:这个提示明确地指出了任务——对文章进行总结,并指定了输出的形式——五个要点。
- 场景:写一篇关于生产力的博客
提示:"写一篇关于小型企业的生产力重要性的博客文章。"
分析:这个提示提供了明确的上下文,告诉 LLM 所需的内容类型(博客),以及博客文章需要涵盖的具体主题(小型企业的生产力的重要性)。
- 场景:写一首诗
提示:"以李白的风格写一首关于落叶的诗。"
分析:这个提示要求 LLM 以特定的风格(李白的风格)写诗,并给出了诗的主题(落叶)。这让 LLM 知道了应该采用的写作风格和主题。
- 场景:关于如何训练小狗的文章
提示:"作为一名专业的狗训练师,写一封电子邮件给一位刚刚得到一只 3 个月大的柯基的客户,告诉他们应该做哪些活动来训练他们的小狗。"
分析:在这个提示中,我们要求 LLM 扮演一个特定的角色(狗训练师),并提供特定的上下文信息,如狗的年龄和类型。我们也指出了我们想要的内容类型(电子邮件)。
提示工程进阶
零/少样本提示
Zero-Shot Prompting:在这种情况下,模型接收到的提示没有包含任何特定任务的示例。这意味着模型需要基于给定的提示,而没有任何相关任务的先前示例,来推断出应该执行的任务。例如,如果我们向模型提供提示 "Translate the following English text to French: 'Hello, how are you?'",那么模型将要根据这个提示,而没有任何额外的翻译示例,来执行翻译任务。
Few-Shot Prompting:在这种情况下,模型接收到的提示包含了一些(通常是几个)特定任务的示例。这些示例作为上下文,提供了关于期望输出的线索。例如,如果我们想要模型进行文本翻译,我们可能会提供如下的提示:
English: 'Cat'
French: 'Chat'
English: 'Dog'
French: 'Chien'
English: 'Bird'
French: 'Oiseau'
English: 'Elephant'在这个例子中,模型通过前三个英法翻译对的示例,理解了我们希望它将 'Elephant' 从英文翻译成法文。因此,它会输出 'Éléphant'。
思维链提示
思维链的思想其实很简单,就是给 LLM 通提供一些思考的中间过程,可以是用户提供,也可以让模型自己来思考。
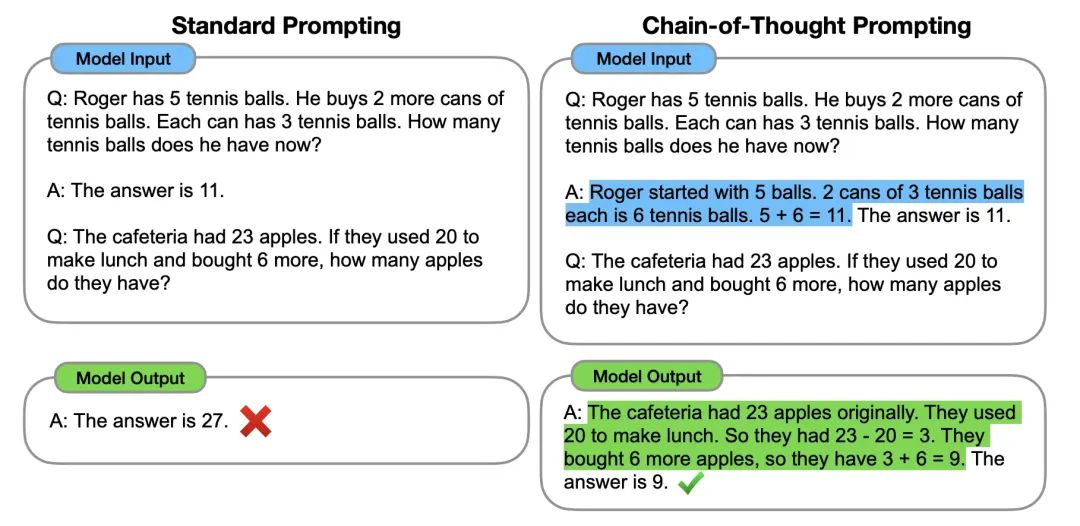
少样本思维链:就是用户提供一些“解题步骤”,比如下图所示,左侧直接让 LLM 回答问题时它给出了错误的答案,但是右侧通过在 prompt 中告诉模型解答步骤,最终给出的答案就是准确的。
零样本思维链:嫌弃提供中间过程太麻烦?偷懒的办法来了,零样本思维链通过一句 magic prompt 实现了这一目标“Let’s think step by step
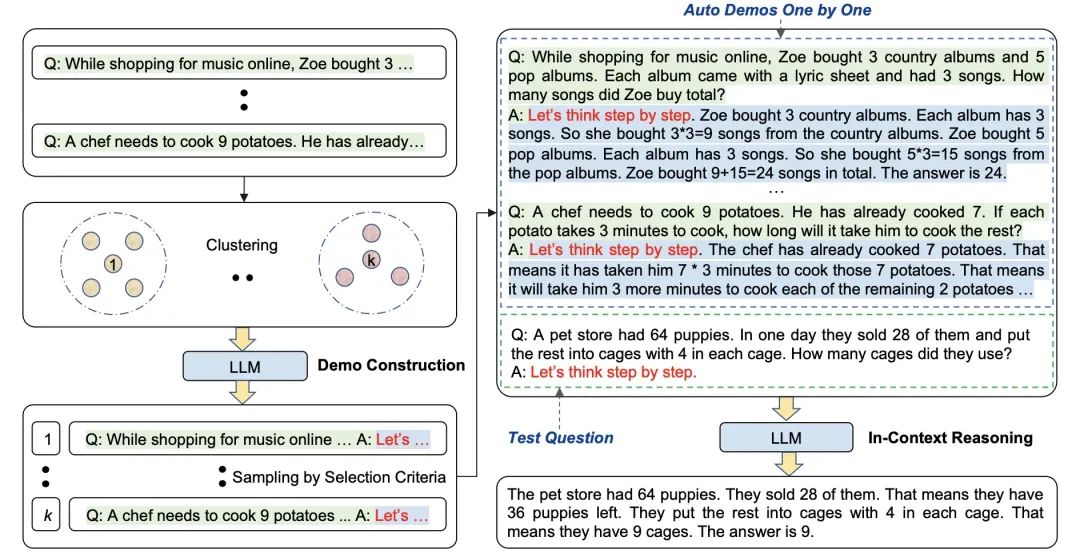
然而过于简化的方法肯定也会存在一定局限性,比如 LLM 可能给出的是错误的思考过程。因此有了自动化思维链,通过采用不同的问题得到一些推理过程让 LLM 参考。它的核心思想分两步

- 首先进行问题聚类,把给定数据集的问题分为几个类型
- 采样参考案例,每个类型问题选择一个代表性问题,然后用零样本思维链来生成推理的中间过程。
Explicit 思维链
这个工作的主要目的是让 LLM 在对话时考虑用户的状态,比如用户的 personality, empathy, 和 psychological,遵循的还是思维链的套路,并且将思维链拆成了多个步骤(LLM 每次回答一点,不是一次性基于思维链全部回答)。这样的好处在于用户还可以修改、删除中间过程的一些回答,原始的上下文和所有中间过程都会用于最终回答的生成。

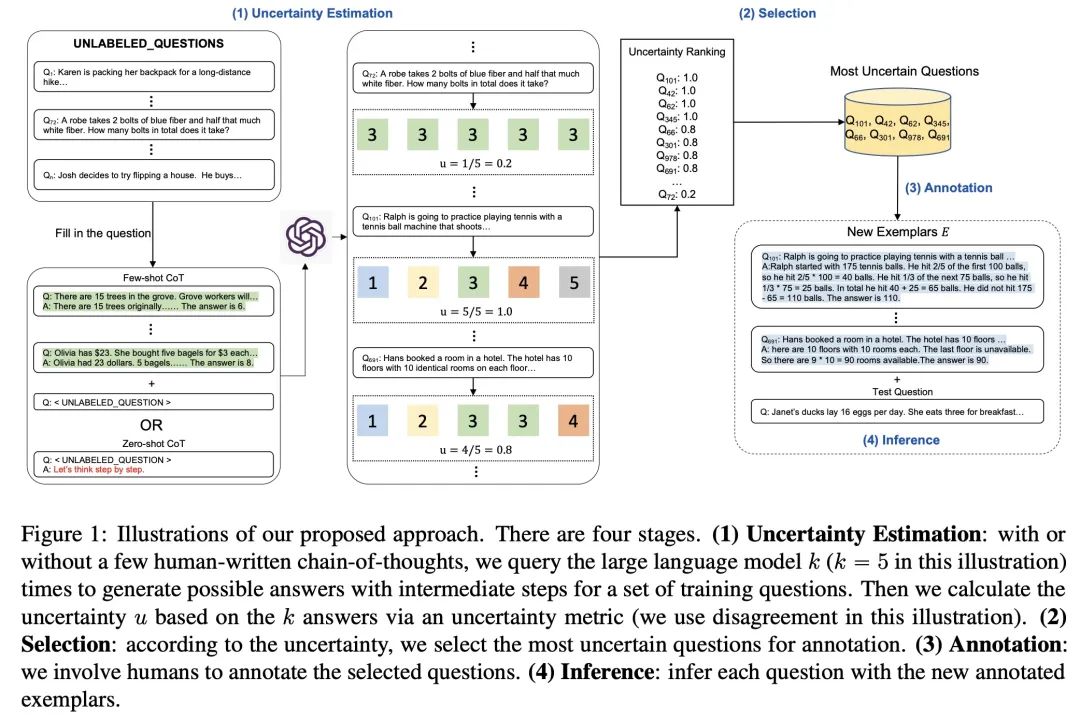
主动提示
本质上还是思维链,由于人工设计的思维链或者自动化思维链的结果也并不一定理想(思维链的设计跟具体任务相关),因此提出了用不确定性来评估思维链的好坏,然后再让人来修正一些不确定性比较大的思维链。
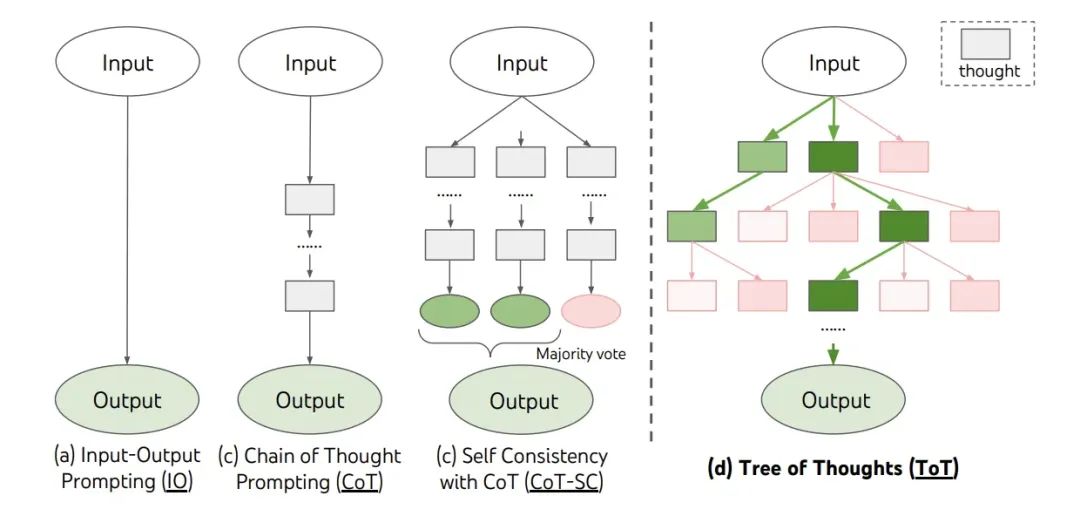
思维树
Tree of Thoughts (ToT)是思维链的进一步拓展,主要想解决 LM 推理过程存在如下两个问题:
- 不会探索不同的可能选择分支
- 无法在节点进行前后向的探索
ToT 将问题建模为树状搜索过程,包括四个步骤:问题分解、想法生成,状态评价以及搜索算法的选择。
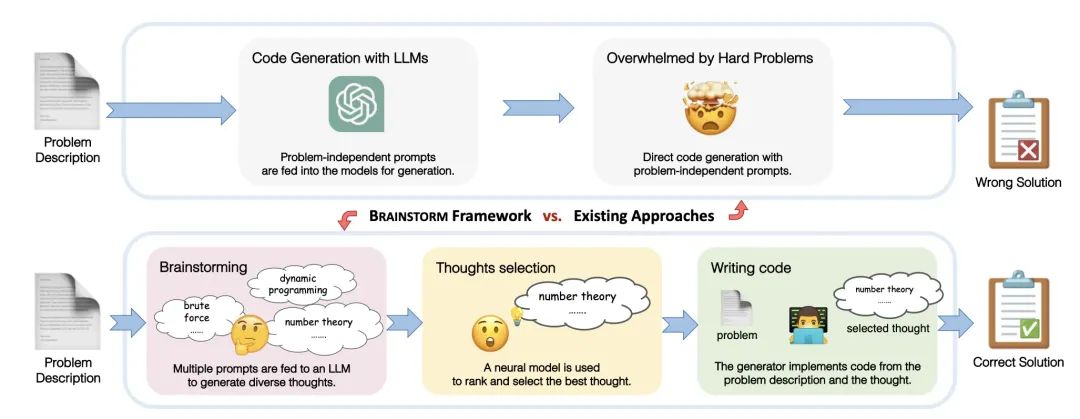
头脑风暴提示
主要考虑的是代码生成方向,不过思想还是可以用在各种领域的提问的。核心思想分为三步
- 头脑风暴:通过多个 prompt 喂给 LLM 得到多样化的“思路”
- 选择最佳思路:这里用了一个神经网络模型来打分,并用最高分的思路来作为最终 prompt
- 代码生成:基于问题和选择出来的最佳思路进行代码生成
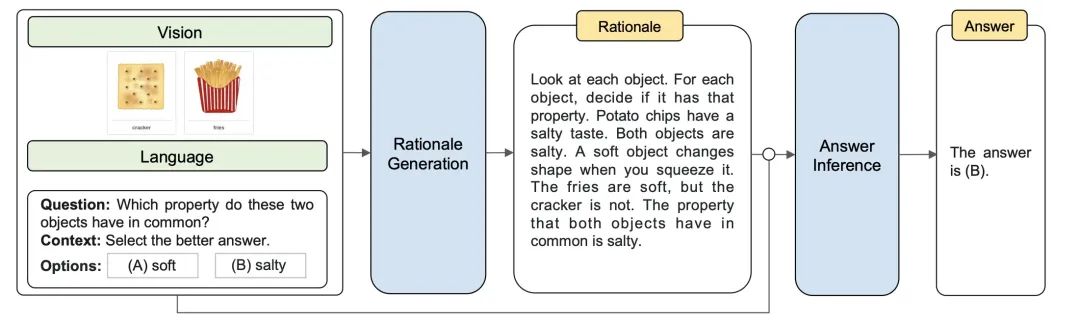
多模态思维链
今年一些需要多模态 LLM 也被提出,自然也有了一些多模态提示工程的尝试,它包括两个阶段:
- 理由生成:在这个阶段,我们将语言和视觉输入提供给模型,以生成推理的理由。这个理由可以看作是解决问题的中间步骤或思考链的一部分。这个过程可以帮助模型理解问题的上下文,并为下一步的答案推断做好准备。
- 答案推断:在这个阶段,我们将从第一阶段生成的理由添加到原始的语言输入中。然后,我们将更新后的语言输入和原始的视觉输入一起提供给模型,以推断出答案。这个过程允许模型利用在理由生成阶段获得的信息来做出更准确的推断。
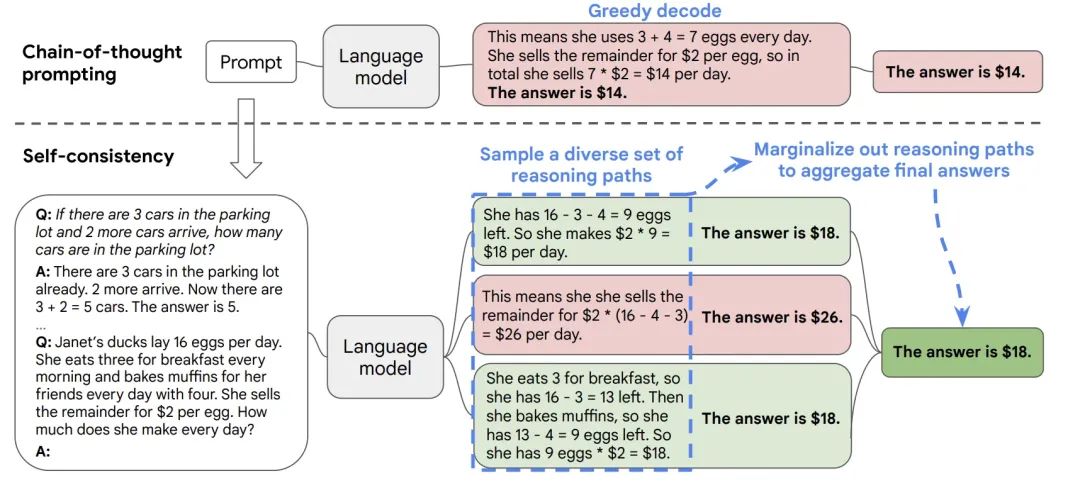
一致性提示
核心思想就是少数服从多数,多让模型回答几次(这里的提问也用到了少样本思维链),然后在 LLM 的多次回答中选择出现多次的答案。
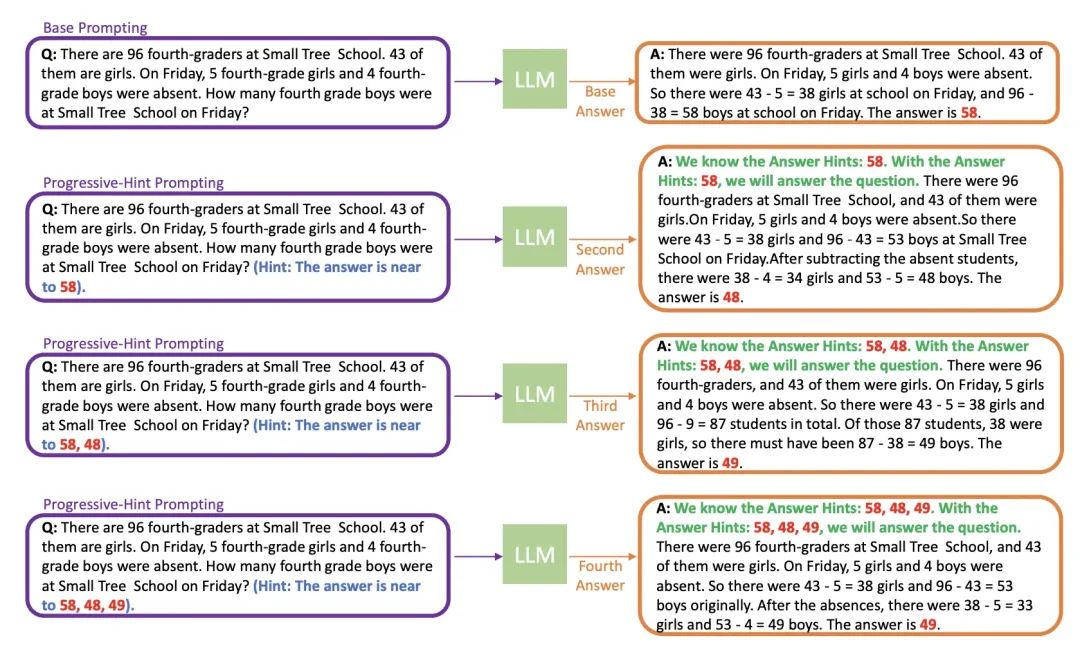
Progressive-Hint 提示
Progressive-Hint Prompting(PHP)类似于一致性提示的进阶,试图模拟人类推理的过程,通过反复检查和修正答案来提高推理的准确性。具体来说,PHP 方法会对上一次的推理过程进行处理,然后将其合并到初始问题中,让模型进行再次推理。当连续两次的推理结果一致时,就认为得出的答案是准确的,并返回最终答案。
在 PHP 方法中,首次与 LLM 交互使用的 prompt 称为基础提示(Base Prompting)。基础提示可以是标准提示、CoT 提示或者其他改进版本的提示。在随后的交互中,将使用 PHP 提示,直到最新的两个答案一致。
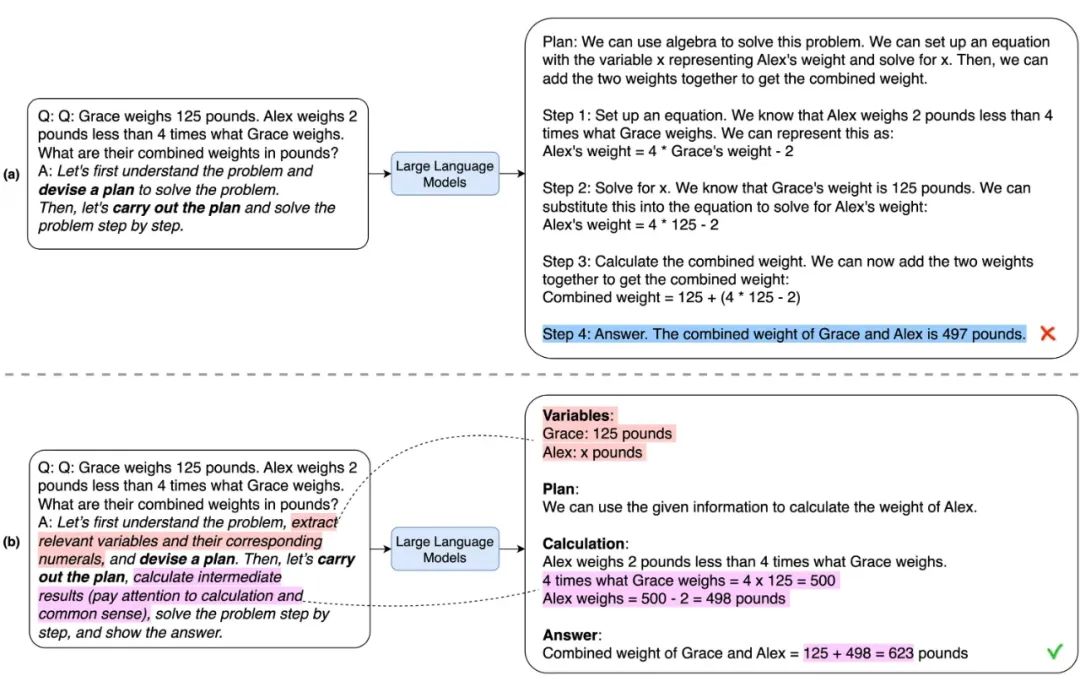
Plan-and-Solve 提示
Plan-and-Solve 提示的设计理念是让模型制定一个解决问题的计划,然后按照这个计划来执行子任务,以此达到明确生成推理步骤的效果。
为了进一步增强 PS 提示的效果,作者扩展了它,形成了一种名为 PS+的新提示方式。PS+提示在 PS 提示的基础上,添加了“pay attention to calculation”这样的引导语句,要求模型在计算过程中更加精确。为了避免模型在处理问题时忽略了关键的变量和数值,PS+提示还增加了“extract relevant variables and their corresponding numerals”这样的引导语句。此外,为了强化模型在推理过程中计算中间结果的能力,PS+提示也加入了“calculate intermediate results”这样的引导语句。通过这种方式,PS+提示进一步提高了模型在处理多步推理任务时的效果。

增强(检索)提示
增强 LLM 本质上在做的事情还是提高提示词的信息,从而更好地引导模型。这里主要可以有两种方式,一种是用自己的私有知识库来扩充 LLM 的知识,一种是借用 LLM 的知识库来提高 prompt 的信息量。
外部知识库
本地知识库
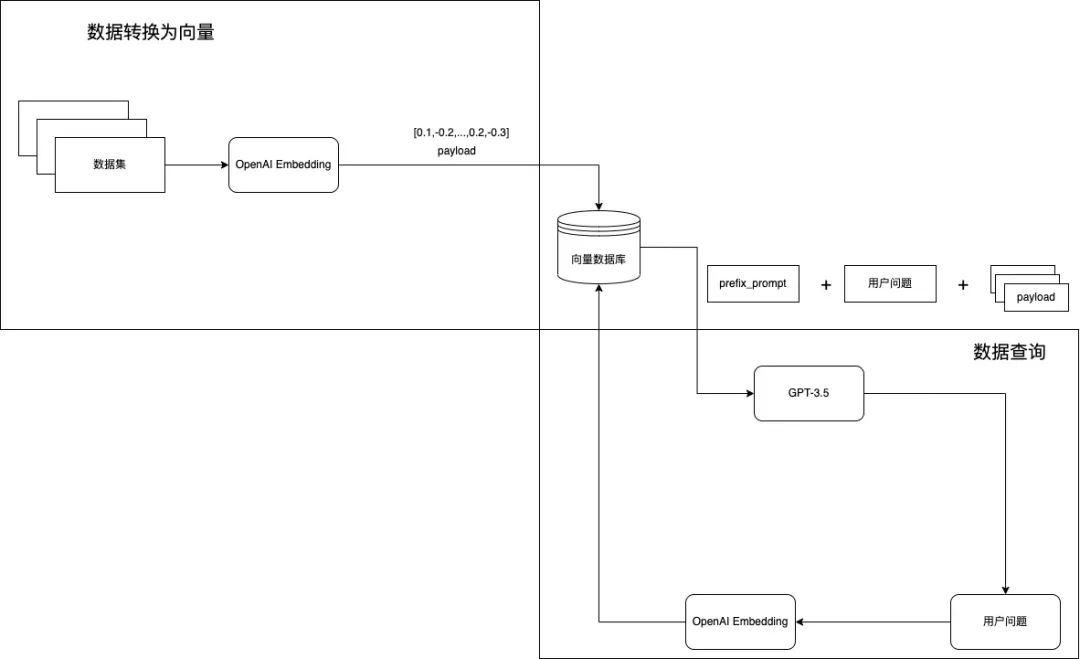
这里可以结合网上的信息或者个人的本地信息,如果是结合网上的信息(比如 newbing),其实就是需要结合一些爬虫工具,捞出一些相关信息一起拼到 prompt 当中(也会需要比如做一些相关性的比较、摘要等)。结合本地知识库也是目前业界内比较关注的方向,主要有以下几步:
- 将本地知识库转为 embedding 保存
- 对于用户提问转为 embedding,然后去数据库查相关的信息
- 检索出本地知识库相关的信息后,比如可以用如下提示拼接上检索出来的信息
<pre data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;border-radius: 5px;box-shadow: rgba(0, 0, 0, 0.55) 0px 2px 10px;"><span style="display: block;background: url("https://mmbiz.qpic.cn/mmbiz_svg/Iic9WLWEQMg0QfpeEMUMoicGn8GF2DZFYjMHCrYSfQGaF5dL3DibVXq0RcBibfQuez1PqBY0ADRvKlIWpRvNaGPqInQicPDhlFGo0/640?wx_fmt=svg") 10px 10px / 40px no-repeat rgb(248, 248, 248);height: 30px;width: 100%;margin-bottom: -7px;border-radius: 5px;">```
Use the following pieces of context<br></br>
这样 LLM 在回答时就能利用上私有的知识了。
#### LLM 知识库
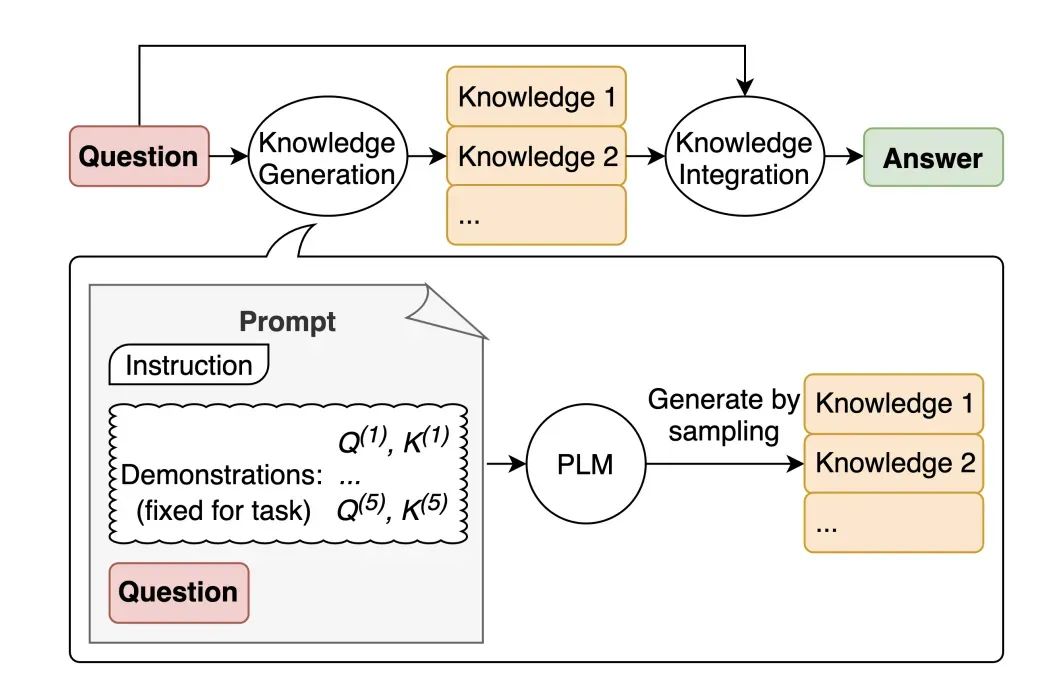
##### 知识生成提示
因为 LLM 本身具有大量的通用知识储备,只是你不提示它一下可能难以在大量知识中找出来给你回答。对于一些问题,我们可以先让 LLM 产生一些相关的知识或事实(比如 Generate some numerical facts about xxx),然后再利用这些辅助信息和原来的问题来提问,Knowledge 处放上 LLM 给出的一些事实信息。
```
Question:
Knowledge:
Explain and Answer:
```
```
前面提到的 Clue And Reasoning 提示其实也属于是在借用 LLM 的知识库。
##### Clue And Reasoning 提示
Clue and Reasoning Prompting (CARP) 是一种用于文本分类的方法,它首先提示大型语言模型(LLMs)寻找表面线索,例如关键词、语调、语义关系、引用等,然后基于这些线索引导出一个诊断推理过程进行最终决策。

(其实也适用于其他场景,让模型帮忙提供点线索再给出最终答案)
##### 知识反刍提示
尽管现有的预训练语言模型(PLMs)在许多任务上表现出色,但它们仍然存在一些问题,比如在处理知识密集型任务时,它们往往不能充分利用模型中的潜在知识。
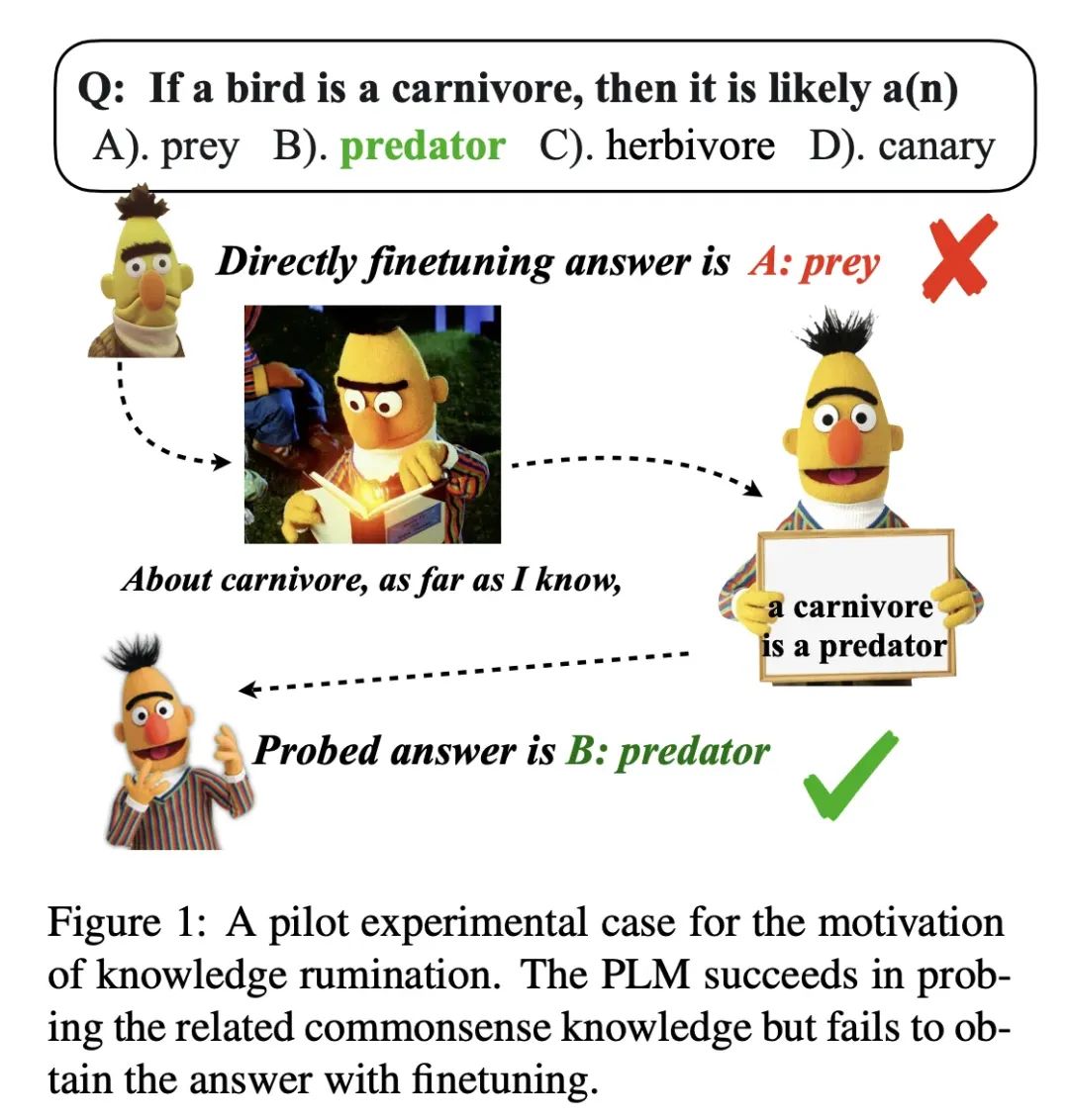
作者们提出了一种名为"Knowledge Rumination"的方法,通过添加像"As far as I know"这样的提示,让模型回顾相关的潜在知识,并将其注入回模型以进行知识巩固。这种方法的灵感来自于动物的反刍过程,即动物会将食物从胃中带回口中再次咀嚼,以便更好地消化和吸收。
文章提出了三种不同类型的提示:
- Background Prompt:这种提示旨在帮助模型思考背景知识。提示的形式是"As far as I know \[MASK\]"。这种提示鼓励模型回顾和思考其已经知道的一般信息或背景知识。
- Mention Prompt:这种提示用于引发模型对提及的记忆。形式是"About \[Mention\], I know \[MASK\]"。这种提示鼓励模型回顾和思考与特定主题或实体(即"\[Mention\]")相关的知识。
- Task Prompt:这种提示旨在帮助模型回忆任务的记忆。例如,对于情感分析,提示是"About sentiment analysis, I know \[MASK\]"。这种提示鼓励模型回顾和思考与特定任务(例如情感分析)相关的知识。
## 懒人万能提示工程
目前网上已经有不少 prompt 优化工具,比如 chatgpt 的插件中就有一个不错的工具 prompt perfect,能够基于用户给的 prompt 进行优化,再喂给 chatgpt 进行提问
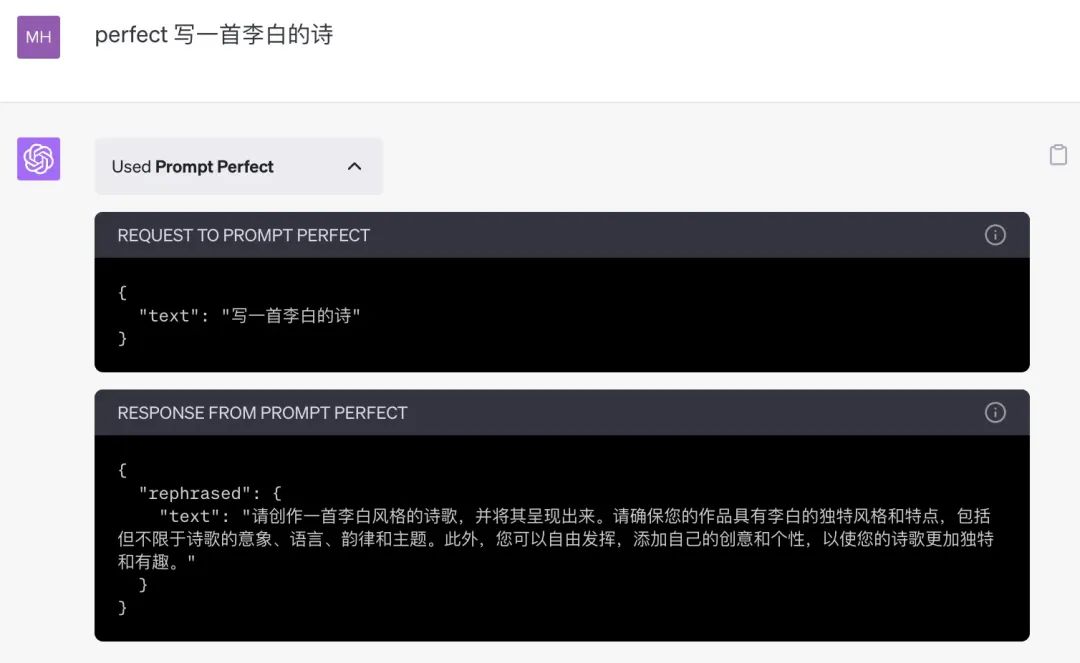
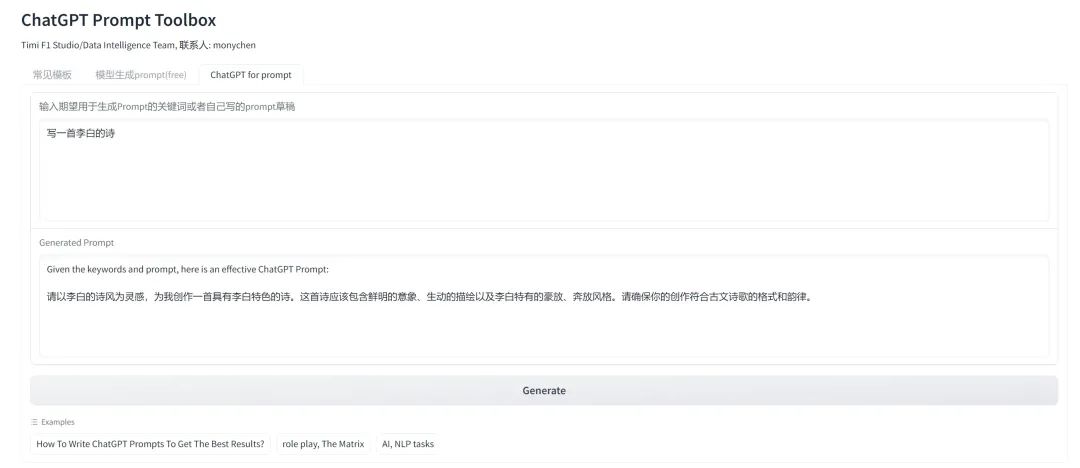
**当然,经过前面那么多提示工程的介绍,大家也可以思考一下,如何用一个提示工程来帮助自己写提示工程**,下面是笔者之前做的一个工具,感兴趣的也可以试试用 chatgpt 来优化自己的 prompt,提示词的效果肉眼可见提升。
## 参考文献
- Prompt Engineering Guide
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Multimodal Chain-of-Thought Reasoning in Language Models
- Automatic Chain of Thought Prompting in Large Language Models
- Self-Consistency Improves Chain of Thought Reasoning in Language Models
- Chain-of-thought prompting for responding to in-depth dialogue questions with LLM
- Think Outside the Code: Brainstorming Boosts Large Language Models in Code Generation
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Active Prompting with Chain-of-Thought for Large Language Models
- Generated Knowledge Prompting for Commonsense Reasoning
- Large Language Models are Zero-Shot Reasoners
- A universal local knowledge base solution based on vector database and GPT3.5
- Text Classification via Large Language Models
- Progressive-Hint Prompting Improves Reasoning in Large Language Models
- Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
- Knowledge Rumination for Pre-trained Language Models