Android Systrace 基础知识(5) - SurfaceFlinger 解读
本文是 Android Systrace 系列文章的第五篇,主要是对 Android 系统中的 SurfaceFlinger 进行简单介绍,介绍了 SurfaceFlinger 中几个比较重要的线程,包括 Vsync 信号的解读、应用的 Buffer 展示、卡顿判定等,由于 Vsync 这一块在Systrace 基础知识 - Vsync 解读[1] 和 Android 基于 Choreographer 的渲染机制详解[2] 这两篇文章里面已经介绍过,这里就不再做详细的讲解了。
本系列的目的是通过 Systrace 这个工具,从另外一个角度来看待 Android 系统整体的运行,同时也从另外一个角度来对 Framework 进行学习。也许你看了很多讲 Framework 的文章,但是总是记不住代码,或者不清楚其运行的流程,也许从 Systrace 这个图形化的角度,你可以理解的更深入一些。
系列文章目录
- Systrace 简介[3]
- Systrace 基础知识 - Systrace 预备知识[4]
- Systrace 基础知识 - Why 60 fps ?[5]
- Systrace 基础知识 - SystemServer 解读[6]
- Systrace 基础知识 - SurfaceFlinger 解读[7]
- Systrace 基础知识 - Input 解读[8]
- Systrace 基础知识 - Vsync 解读[9]
- Systrace 基础知识 - Vsync-App :基于 Choreographer 的渲染机制详解[10]
- Systrace 基础知识 - MainThread 和 RenderThread 解读[11]
- Systrace 基础知识 - Binder 和锁竞争解读[12]
- Systrace 基础知识 - Triple Buffer 解读[13]
- Systrace 基础知识 - CPU Info 解读[14]
正文
这里直接上官方对于 SurfaceFlinger 流程的定义[15]
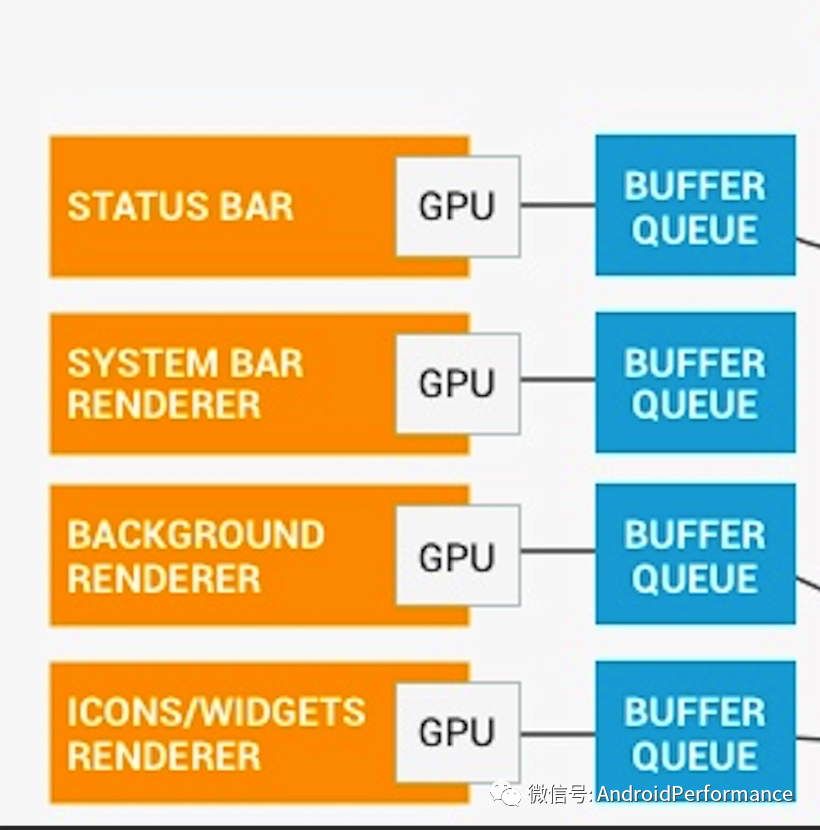
- 大多数应用在屏幕上一次显示三个层:屏幕顶部的状态栏、底部或侧面的导航栏以及应用界面。有些应用会拥有更多或更少的层(例如,默认主屏幕应用有一个单独的壁纸层,而全屏游戏可能会隐藏状态栏)。每个层都可以单独更新。状态栏和导航栏由系统进程渲染,而应用层由应用渲染,两者之间不进行协调。
- 设备显示会按一定速率刷新,在手机和平板电脑上通常为 60 fps。如果显示内容在刷新期间更新,则会出现撕裂现象;因此,请务必只在周期之间更新内容。在可以安全更新内容时,系统便会收到来自显示设备的信号。由于历史原因,我们将该信号称为 VSYNC 信号。
- 刷新率可能会随时间而变化,例如,一些移动设备的帧率范围在 58 fps 到 62 fps 之间,具体要视当前条件而定。对于连接了 HDMI 的电视,刷新率在理论上可以下降到 24 Hz 或 48 Hz,以便与视频相匹配。由于每个刷新周期只能更新屏幕一次,因此以 200 fps 的帧率为显示设备提交缓冲区就是一种资源浪费,因为大多数帧会被舍弃掉。SurfaceFlinger 不会在应用每次提交缓冲区时都执行操作,而是在显示设备准备好接收新的缓冲区时才会唤醒。
- 当 VSYNC 信号到达时,SurfaceFlinger 会遍历它的层列表,以寻找新的缓冲区。如果找到新的缓冲区,它会获取该缓冲区;否则,它会继续使用以前获取的缓冲区。SurfaceFlinger 必须始终显示内容,因此它会保留一个缓冲区。如果在某个层上没有提交缓冲区,则该层会被忽略。
- SurfaceFlinger 在收集可见层的所有缓冲区之后,便会询问 Hardware Composer 应如何进行合成。」
---- 引用自SurfaceFlinger 和 Hardware Composer[16]
下面是上述流程所对应的流程图, 简单地说, SurfaceFlinger 最主要的功能:「SurfaceFlinger 接受来自多个来源的数据缓冲区,对它们进行合成,然后发送到显示设备。」
SurfaceFlinger 的工作流程
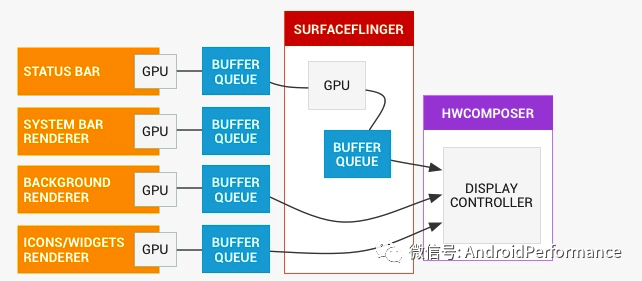
那么 Systrace 中,我们关注的重点就是上面这幅图对应的部分
- App 部分
- BufferQueue 部分
- SurfaceFlinger 部分
- HWComposer 部分
这四部分,在 Systrace 中都有可以对应的地方,以时间发生的顺序排序就是 1、2、3、4,下面我们从 Systrace 的这四部分来看整个渲染的流程
App 部分
关于 App 部分,其实在Systrace 基础知识 - MainThread 和 RenderThread 解读[17]这篇文章里面已经说得比较清楚了,不清楚的可以去这篇文章里面看,其主要的流程如下图:
App 一帧的流程
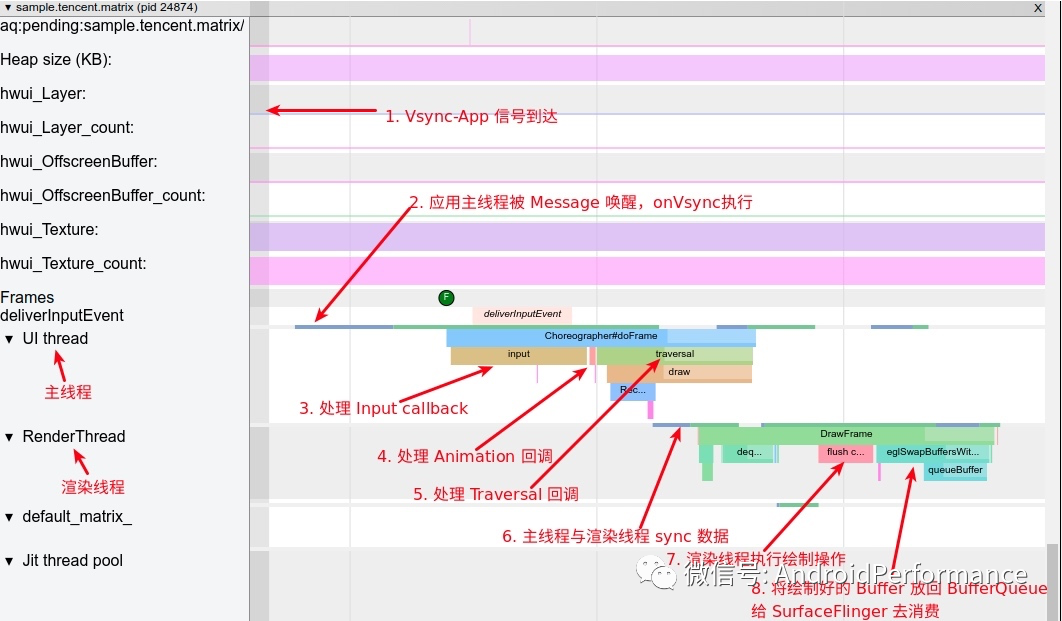
从 SurfaceFlinger 的角度来看,App 部分主要负责生产 SurfaceFlinger 合成所需要的 Surface。
App 与 SurfaceFlinger 的交互主要集中在三点
- Vsync 信号的接收和处理
- RenderThread 的 dequeueBuffer
- RenderThread 的 queueBuffer
Vsync 信号的接收和处理
关于这部分内容可以查看Android 基于 Choreographer 的渲染机制详解[18] 这篇文章,App 和 SurfaceFlinger 的第一个交互点就是 Vsync 信号的请求和接收,如上图中第一条标识,Vsync-App 信号到达,就是指的是 SurfaceFlinger 的 Vsync-App 信号。应用收到这个信号后,开始一帧的渲染准备
Vsync 信号的接收和处理
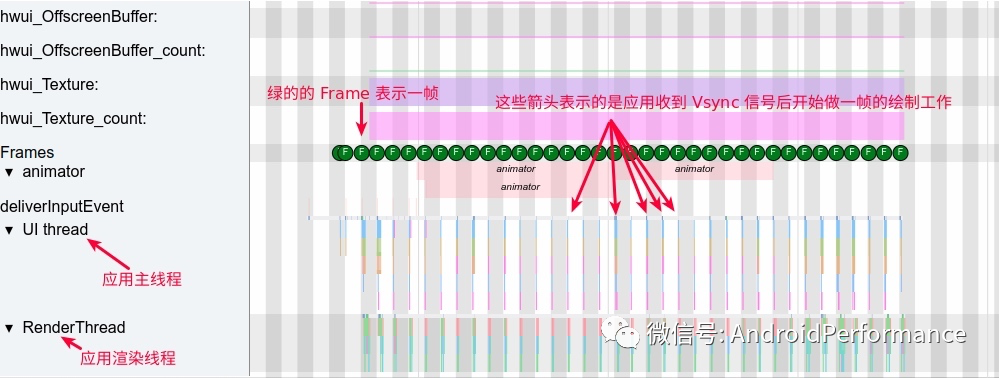
RenderThread 的 dequeueBuffer
dequeue 有出队的意思,dequeueBuffer 顾名思义,就是从队列中拿出一个 Buffer,这个队列就是 SurfaceFlinger 中的 BufferQueue。如下图,应用开始渲染前,首先需要通过 Binder 调用从 SurfaceFlinger 的 BufferQueue 中获取一个 Buffer,其流程如下:
「App 端的 Systrace 如下所示」
App 端的 Buffer 操作
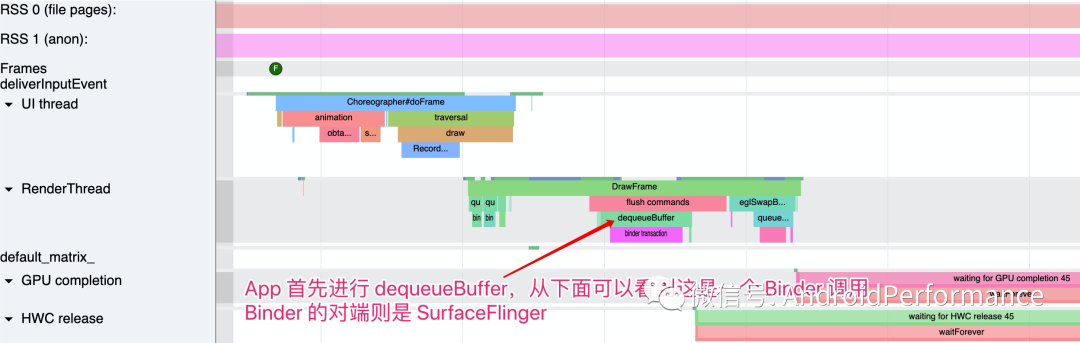
「SurfaceFlinger 端的 Systrace 如下所示」
SurfaceFlinger 端的 Buffer 操作
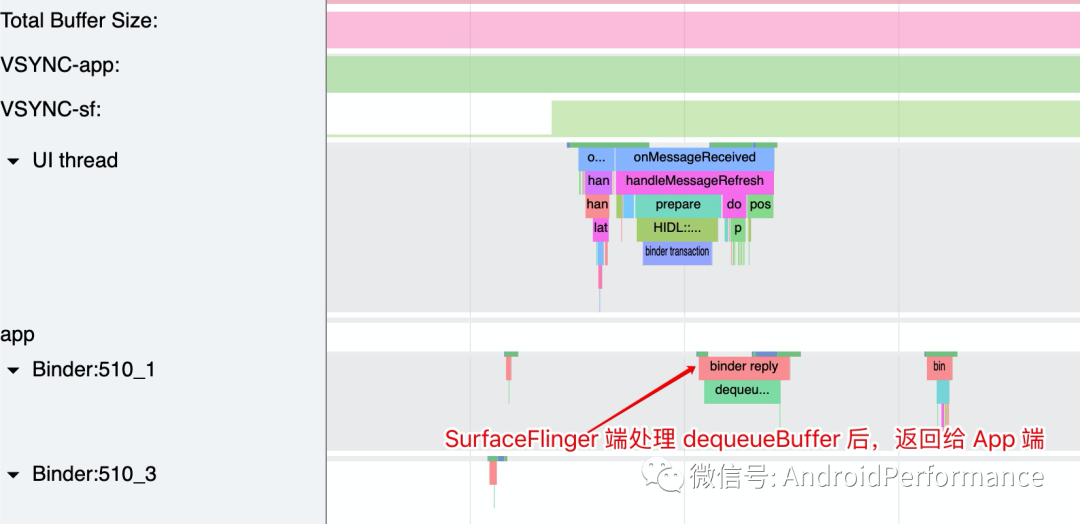
RenderThread 的 queueBuffer
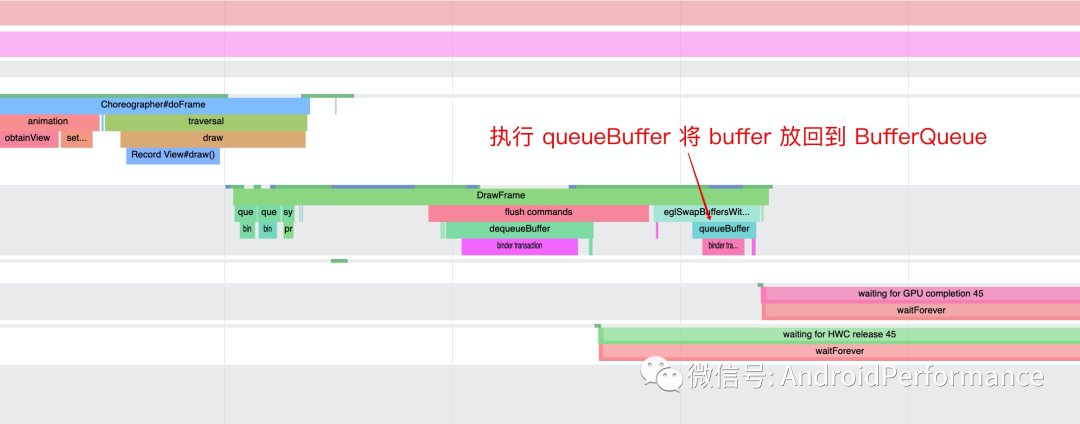
queue 有入队的意思,queueBuffer 顾名思义就是讲 Buffer 放回到 BufferQueue,App 处理完 Buffer 后(写入具体的 drawcall),会把这个 Buffer 通过 eglSwapBuffersWithDamageKHR -> queueBuffer 这个流程,将 Buffer 放回 BufferQueue,其流程如下
「App 端的 Systrace 如下所示」file:///Users/gaojack/blog/source/images/15822960954718.jpg
「SurfaceFlinger 端的 Systrace 如下所示」
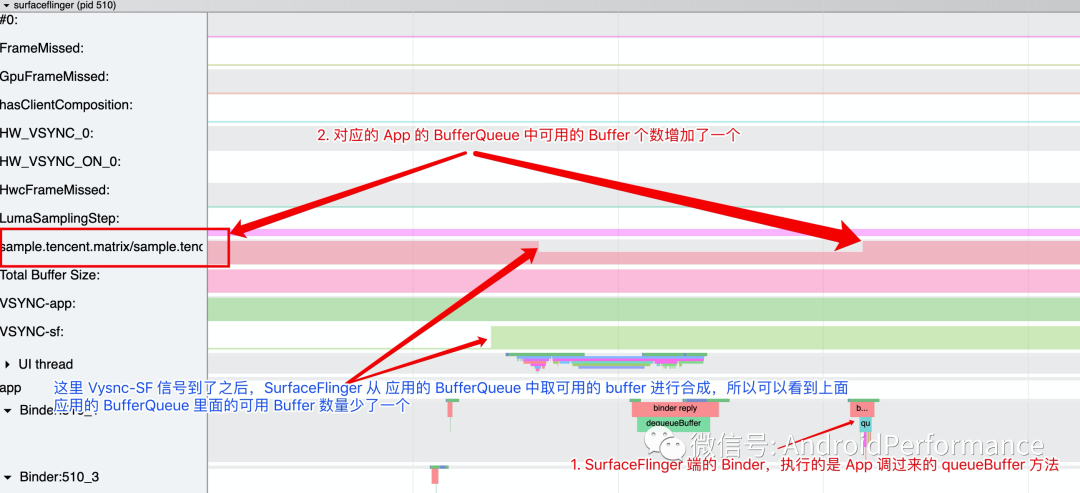
通过上面三部分,大家应该对下图中的流程会有一个比较直观的了解了
BufferQueue 部分
BufferQueue 部分其实在Systrace 基础知识 - Triple Buffer 解读[19] 这里有讲,如下图,结合上面那张图,每个有显示界面的进程对应一个 BufferQueue,使用方创建并拥有 BufferQueue 数据结构,并且可存在于与其生产方不同的进程中,BufferQueue 工作流程如下:
BufferQueue 的工作流程
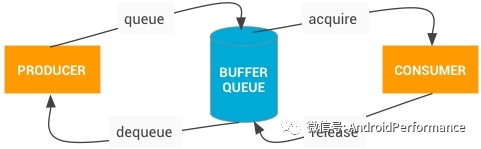
上图主要是 dequeue、queue、acquire、release ,在这个例子里面,App 是「生产者」,负责填充显示缓冲区(Buffer);SurfaceFlinger 是「消费者」,将各个进程的显示缓冲区做合成操作
- dequeue(生产者发起) :当生产者需要缓冲区时,它会通过调用 dequeueBuffer() 从 BufferQueue 请求一个可用的缓冲区,并指定缓冲区的宽度、高度、像素格式和使用标记。
- queue(生产者发起):生产者填充缓冲区并通过调用 queueBuffer() 将缓冲区返回到队列。
- acquire(消费者发起) :消费者通过 acquireBuffer() 获取该缓冲区并使用该缓冲区的内容
- release(消费者发起) :当消费者操作完成后,它会通过调用 releaseBuffer() 将该缓冲区返回到队列
SurfaceFlinger 部分
工作流程
从最前面我们知道 SurfaceFlinger 的主要工作就是合成:
❝当 VSYNC 信号到达时,SurfaceFlinger 会遍历它的层列表,以寻找新的缓冲区。如果找到新的缓冲区,它会获取该缓冲区;否则,它会继续使用以前获取的缓冲区。SurfaceFlinger 必须始终显示内容,因此它会保留一个缓冲区。如果在某个层上没有提交缓冲区,则该层会被忽略。SurfaceFlinger 在收集可见层的所有缓冲区之后,便会询问 Hardware Composer 应如何进行合成。
❞
其 Systrace 主线程可用看到其主要是在收到 Vsync 信号后开始工作
SurfaceFlinger 流程

其对应的代码如下,主要是处理两个 Message
- MessageQueue::INVALIDATE --- 主要是执行 handleMessageTransaction 和 handleMessageInvalidate 这两个方法
- MessageQueue::REFRESH --- 主要是执行 handleMessageRefresh 方法
frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::onMessageReceived(int32_t what) NO_THREAD_SAFETY_ANALYSIS {
ATRACE_CALL();
switch (what) {
case MessageQueue::INVALIDATE: {
......
bool refreshNeeded = handleMessageTransaction();
refreshNeeded |= handleMessageInvalidate();
......
break;
}
case MessageQueue::REFRESH: {
handleMessageRefresh();
break;
}
}
}
//handleMessageInvalidate 实现如下
bool SurfaceFlinger::handleMessageInvalidate() {
ATRACE_CALL();
bool refreshNeeded = handlePageFlip();
if (mVisibleRegionsDirty) {
computeLayerBounds();
if (mTracingEnabled) {
mTracing.notify("visibleRegionsDirty");
}
}
for (auto& layer : mLayersPendingRefresh) {
Region visibleReg;
visibleReg.set(layer->getScreenBounds());
invalidateLayerStack(layer, visibleReg);
}
mLayersPendingRefresh.clear();
return refreshNeeded;
}
//handleMessageRefresh 实现如下, SurfaceFlinger 的大部分工作都是在handleMessageRefresh 中发起的
void SurfaceFlinger::handleMessageRefresh() {
ATRACE_CALL();
mRefreshPending = false;
const bool repaintEverything = mRepaintEverything.exchange(false);
preComposition();
rebuildLayerStacks();
calculateWorkingSet();
for (const auto& [token, display] : mDisplays) {
beginFrame(display);
prepareFrame(display);
doDebugFlashRegions(display, repaintEverything);
doComposition(display, repaintEverything);
}
logLayerStats();
postFrame();
postComposition();
mHadClientComposition = false;
mHadDeviceComposition = false;
for (const auto& [token, displayDevice] : mDisplays) {
auto display = displayDevice->getCompositionDisplay();
const auto displayId = display->getId();
mHadClientComposition =
mHadClientComposition || getHwComposer().hasClientComposition(displayId);
mHadDeviceComposition =
mHadDeviceComposition || getHwComposer().hasDeviceComposition(displayId);
}
mVsyncModulator.onRefreshed(mHadClientComposition);
mLayersWithQueuedFrames.clear();
}handleMessageRefresh 中按照重要性主要有下面几个功能
1 . 准备工作
a . preComposition();
b . rebuildLayerStacks();
c. calculateWorkingSet();
2 . 合成工作
a . begiFrame(display);
b . prepareFrame(display);
c . doDebugFlashRegions(display, repaintEverything);
d . doComposition(display, repaintEverything);
3 . 收尾工作
a . logLayerStats();
b . postFrame();
c . postComposition();
由于显示系统有非常庞大的细节,这里就不一一进行讲解了,如果你的工作在这一部分,那么所有的流程都需要熟悉并掌握,如果只是想熟悉流程,那么不需要太深入,知道 SurfaceFlinger 的主要工作逻辑即可
掉帧
通常我们通过 Systrace 判断应用是否「掉帧」的时候,一般是直接看 SurfaceFlinger 部分,主要是下面几个步骤
1 . SurfaceFlinger 的主线程在每个 Vsync-SF 的时候是否没有合成?
2 . 如果没有合成操作,那么需要看没有合成的原因:
a . 因为 SurfaceFlinger 检查发现没有可用的 Buffer 而没有合成操作?
b . 因为 SurfaceFlinger 被其他的工作占用(比如截图、HWC 等)?
3 . 如果有合成操作,那么需要看对应的 App 的 可用 Buffer 个数是否正常:如果 App 此时可用 Buffer 为 0,那么看 App 端为何没有及时 queueBuffer(这就一般是应用自身的问题了),因为 SurfaceFlinger 合成操作触发可能是其他的进程有可用的 Buffer
关于这一部分的 Systrace 怎么看,在 Systrace 基础知识 - Triple Buffer 解读-掉帧检测[20] 部分已经有比较详细的解读,大家可以过去看这一段
HWComposer 部分
关于 HWComposer 的功能部分我们就直接看官方的介绍[21]即可
1 . Hardware Composer HAL (HWC) 用于确定通过可用硬件来合成缓冲区的最有效方法。作为 HAL,其实现是特定于设备的,而且通常由显示设备硬件原始设备制造商 (OEM) 完成。
2 . 当您考虑使用叠加平面时,很容易发现这种方法的好处,它会在显示硬件(而不是 GPU)中合成多个缓冲区。例如,假设有一部普通 Android 手机,其屏幕方向为纵向,状态栏在顶部,导航栏在底部,其他区域显示应用内容。每个层的内容都在单独的缓冲区中。您可以使用以下任一方法处理合成(后一种方法可以显著提高效率):
a . 将应用内容渲染到暂存缓冲区中,然后在其上渲染状态栏,再在其上渲染导航栏,最后将暂存缓冲区传送到显示硬件。
b . 将三个缓冲区全部传送到显示硬件,并指示它从不同的缓冲区读取屏幕不同部分的数据。
3 . 显示处理器功能差异很大。叠加层的数量(无论层是否可以旋转或混合)以及对定位和叠加的限制很难通过 API 表达。为了适应这些选项,HWC 会执行以下计算(由于硬件供应商可以定制决策代码,因此可以在每台设备上实现最佳性能):
a . SurfaceFlinger 向 HWC 提供一个完整的层列表,并询问“您希望如何处理这些层?”
b . HWC 的响应方式是将每个层标记为叠加层或 GLES 合成。
c . SurfaceFlinger 会处理所有 GLES 合成,将输出缓冲区传送到 HWC,并让 HWC 处理其余部分。
4 . 当屏幕上的内容没有变化时,叠加平面的效率可能会低于 GL 合成。当叠加层内容具有透明像素且叠加层混合在一起时,尤其如此。在此类情况下,HWC 可以选择为部分或全部层请求 GLES 合成,并保留合成的缓冲区。如果 SurfaceFlinger 返回来要求合成同一组缓冲区,HWC 可以继续显示先前合成的暂存缓冲区。这可以延长闲置设备的电池续航时间。
5 . 运行 Android 4.4 或更高版本的设备通常支持 4 个叠加平面。尝试合成的层数多于叠加层数会导致系统对其中一些层使用 GLES 合成,这意味着应用使用的层数会对能耗和性能产生重大影响。
-------- 引用自SurfaceFlinger 和 Hardware Composer[22]
我们继续接着看 SurfaceFlinger 主线程的部分,对应上面步骤中的第三步,下图可以看到 SurfaceFlinger 与 HWC 的通信部分
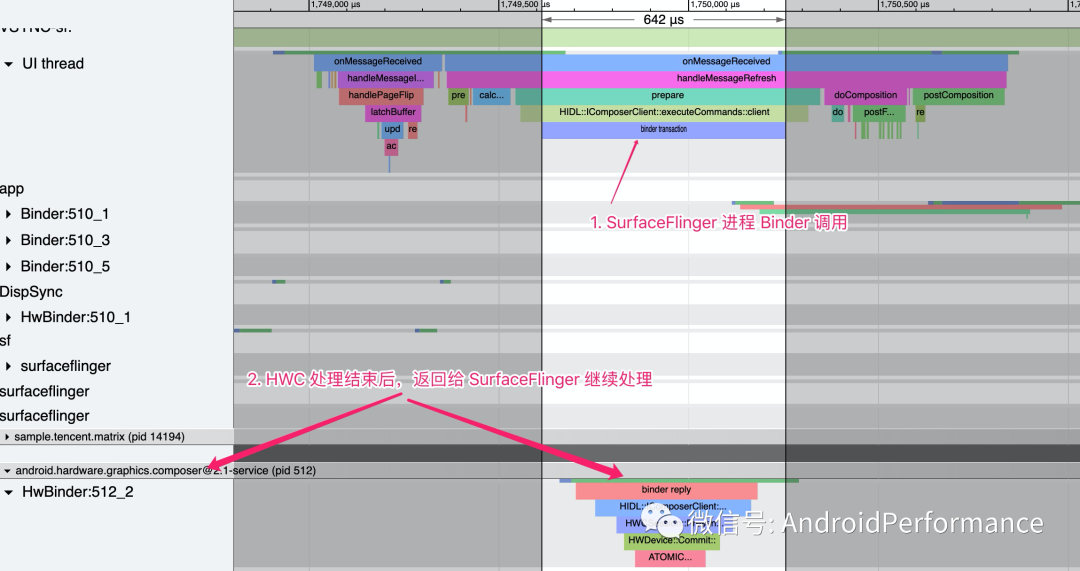
这也对应了最上面那张图的后面部分
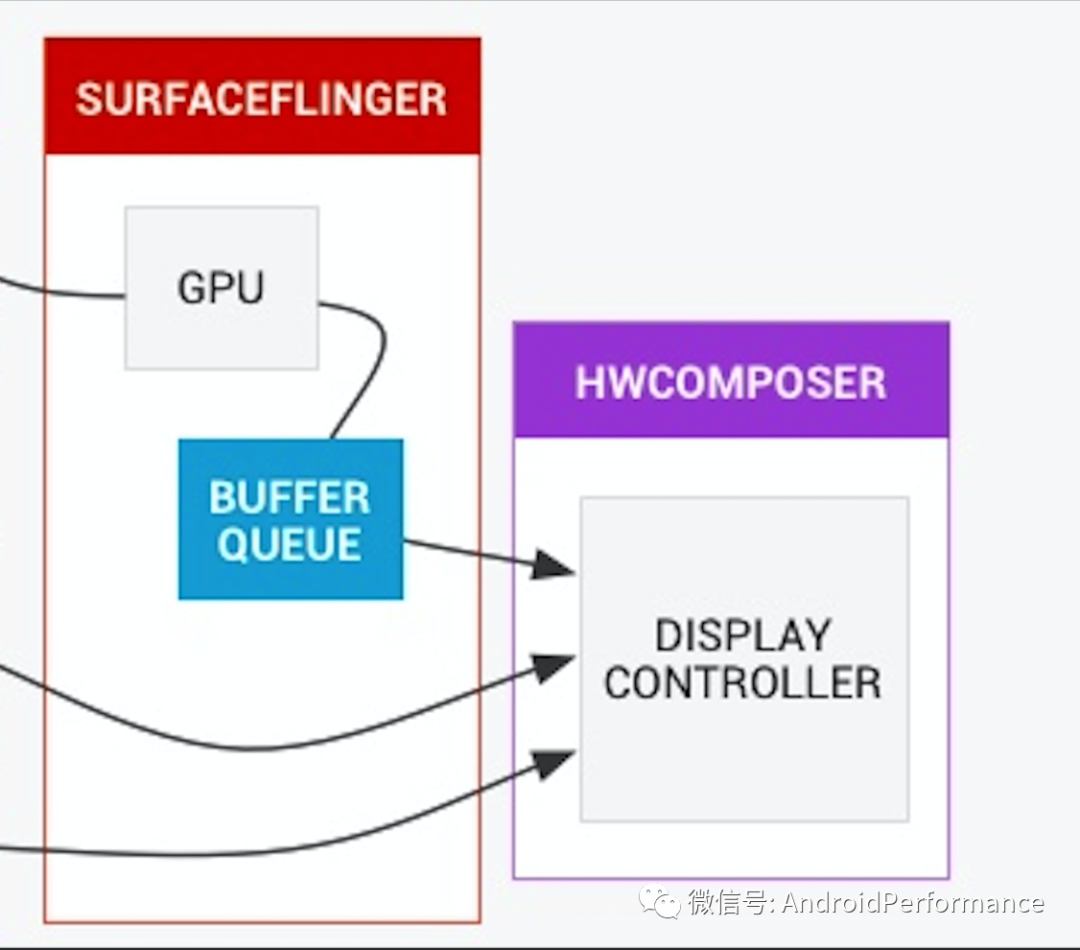
不过这其中的细节非常多,这里就不详细说了。至于为什么要提 HWC,因为 HWC 不仅是渲染链路上重要的一环,其性能也会影响整机的性能,Android 中的卡顿丢帧原因概述 - 系统篇[23] 这篇文章里面就有列有 HWC 导致的卡顿问题(性能不足,中断信号慢等问题)
想了解更多 HWC 的知识,可以参考这篇文章Android P 图形显示系统(一)硬件合成HWC2[24],当然,作者的Android P 图形显示系[25]这个系列大家可以仔细看一下
参考文章
- Android P 图形显示系统(一)硬件合成HWC2[26]
- Android P 图形显示系统[27]
- SurfaceFlinger 的定义[28]
- surfacefliner[29]