大麦 Android 选座场景性能优化全解析
通常情况下移动端APP由于受到设备性能所限一般较少有场景会处理超量数据,更多的是将复杂数据处理交付给服务端。本质上降低终端强数据处理是很有必要的,降低CPU使用率、减少内存抖动可以大幅提升APP使用体验。但是有时移动端也不得不处理超量数据,大麦选座就是这样一个强数据处理场景。
那么选座场景具体面对的是怎样的超量数据呢? 上图是测试过程中使用的“奥运体育场”在大麦APP选座场景下绘制的UI,这个体育场包含了140+个看台,6万+个可售座位。我们需要建立数据模型来描述一个座位,它的基本要素会包含座位id、价格id、坐标、座位角度、座位位置、座位状态 等等。结合业务场景,在购票流程中的变与不变,我们可以将座位拆分成2套数据:
- 座位静态数据,它包含座位相对不变的部分,比如:座位id、价格id、坐标、座位角度、座位位置。
- 座位动态数据,即座位状态。它是变化最为频繁的,比如:用户下单时座位从可售状态变更为已售状态,用户取消时座位会从已售状态回归到可售状态。
假设我们使用XML来描述座位静态数据,使用JSON来描述座位动态数据,那么上述体育场6万+个座位对应的座位静态数据的文件大小为9.6M,座位动态数据的文件大小为1.8M。
想象一个场景:拥有6万+座位的超大体育场、偶像级歌手、售前几十万人关注、实时在线选座分钟级别售罄,静态数据的下载、动态数据的刷新、数据的解析与合成,不管对于服务端还是客户端都会是一场考验。当然选座场景自然是不会直接传输这样未经过压缩的数据,但这也从侧面说明了选座场景的数据量级,也就是说选座移动端必须要有能力快速、高效处理数以万计座位的解析、合成、渲染,以保障超级场馆实时在线抢票。
下面我总结了一些核心的提升选座场景用户体验和支撑超大场馆实时在线选座的方案和策略。
接口预加载策略
选座场景相对于其他大麦业务使用到了更多的网络接口及CDN下载,从SKU页进入一个选座页最少要使用5次网络请求才能最终合并成选座UI。
- 渲染时:
- Areainfo 网络接口 ,选座引导接口主要描述静态看台信息、静态文件cdn信息、开关信息等;
- StaticSeat CDN下载,静态座位文件网络下载;
- StaticSvg CDN下载,静态SVG文件网络下载;
- DynamicInfo 网络接口,场次信息、票档实时信息;
-
Seatstatus 网络接口,座位实时状态信息。
- 刷新时:
- DynamicInfo 网络接口,场次信息、票档实时信息;
-
Seatstatus 网络接口,座位实时状态信息。
- 选座中:
- Precheck 网络接口,预锁座功能;
- CalcPrice 网络接口,实时算价功能。
已知渲染需要至少使用到”渲染时“标出的5个请求,正如木桶效应一样,选座场景的页面加载时长取决于最后一个接口的返回,而通常接口RT取决于网络繁忙程度、网络状况、服务端处理能力等,客户端要做的是尽可能将这些网络请求分类、前置化处理,降低网络请求并发对CPU瞬时负载。
静态数据预加载
这里的静态主要主要是指"Areainfo"引导数据、”静态座位文件“、”静态SVG文件“的预加载策略,特点:他们通常在一个项目上线后很少发生变化,存储于CDN服务器中。静态数据预加载策略 就是在进入选座场景之前的链路如SKU(场次与票档选择页)进行闲时下载。这样可以前置 ”Areainfo“、”StaticSeat“、”StaticSvg“ 请求。
网络接口预加载
一般在Android App开发过程中我们会在Activity.onCreate()方法中触发网络请求,完成页面渲染。在测试的过程中我们发现像选座Activity这样的页面,从startActivity()方法调用到目标activity.onCreate()之间存在50-60ms的调度、创建时间。所以我们将”DynamicInfo“、”Seatstatus“前置到startActivity(),即启动选座场景时立即发出以上2个请求。
这样就可以将需要并发的请求打散、按其特点进行分类、分阶段执行。即可利用静态数据不易变更的特性进行前置下载,也兼顾到动态数据的实时性获取。
静态数据缓存
正如上述提及的”奥运体育场“,其包含了数以万计的座位信息、复杂的SVG文件。解析合成都是较为耗时的操作,如果只是使用一次随即丢弃肯定是非常浪费资源的。在选座场景抢票过程中,用户可能会在”售前“、”售中“反复进入”商品详情“、”SKU“、”选座“页面,为这类静态数据做缓存策略是非常有必要的,这可以大幅降低CDN下载压力,提升SVG、座位结构对象的复用率,降低CPU内存抖动程度。
选座场景提供了BaseLoader、策略性Cache对全场景进行数据预加载、内存缓存管理,通过对软引用的使用,即保持了静态数据高效可复用,也避免由于内存紧张而出现强未使用态的强引用静态数据无法及时释放的情况。
- ImageLoader,支持SVG、JPG加载、缓存
- Seat3DVrImageDataLoader,支持VR图像下载、解密等
- Seat3DVrDataLoader,支持VR结构化数据下载、解密等
- SeatLoader,支持多种静态座位数据的下载、解密、缓存等
静态数据压缩
静态座位数据压缩
静态座位数据压缩方案,内部代号“Quantum”是大麦自研的一套针对选座静态座位数据进行压缩解压的一套解决方案,其主要组成部分包含了核心解压缩算法、加密解密方案、数据完整性校验等。
观察静态座位数据的结构,可以总结出一些特点:包含大量的数值型字段如Long型的座位id、Int型的座位编号、Int型的座位角度、Long型的价格id、Int型的坐标 以及批量重复的看台号、排号等。数值型字段非常适合使用差值法组合Ziazag整数算法进行压缩,批量重复性的看台、排号等信息非常适合字典方式简化存储。Zigzag的核心思想就是通过位运算、原码及补码的转换移除数值型内存二进制中“无意义的0”,仅存储从1开始的“有效数据”,从而达成对数据的压缩,数值绝对值越小压缩比率越高。
以下是关于“Quantum”方案与原大麦选座场景静态数据方案的对比。
压缩效率:相比于”XML+GZIP",“Quantum+GZIP”压缩后的静态文件缩减了70%以上。
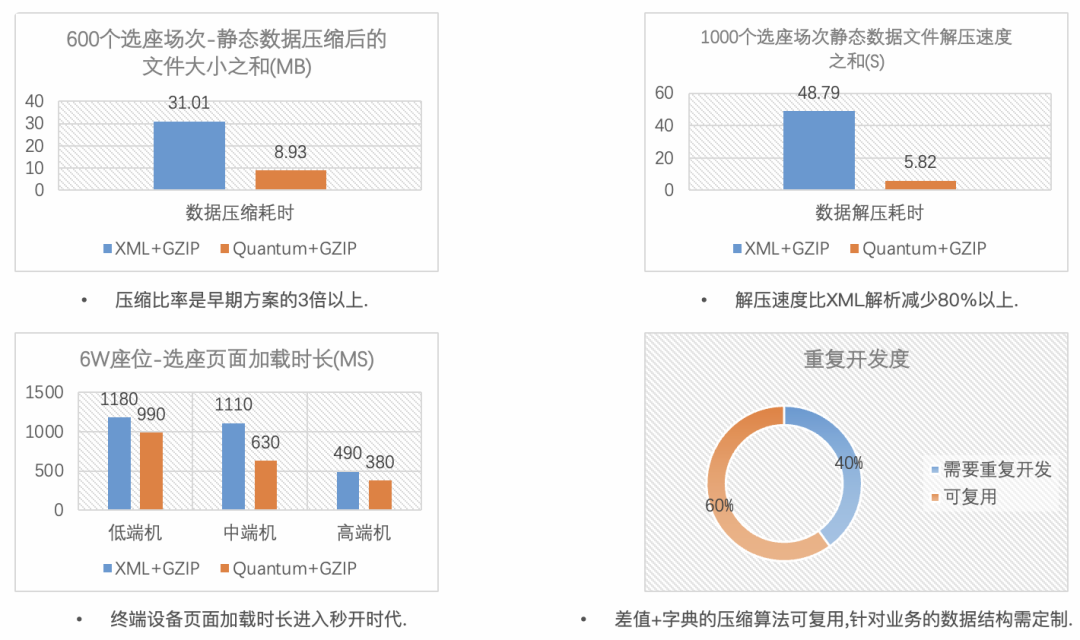
解析速度:相比于"XML Pull"解析方案,“Quantum”座位解析时长总体缩减了80%以上。
静态VR数据压缩
静态VR数据指的是一套描述看台-座位-关联的VR数据信息的一套数据,大麦选座场景使用了Google Protocol Buffers 来存储VR结构化数据,以”北京某剧院“ 的VR数据为例 使用JSON文件来描述 VR结构数据的文件大约为 640KB,当使用Protocol Buffers时 文件的大小约为250KB,而经过GZIP压缩后仅有8KB大小。
压缩效率:相比于使用JSON描述VR结构化数据,使用Protocol Buffers文件大小缩减了35%以上。实际上Protocol Buffers内部使用了Ziazag整数压缩算法,VR结构化数据中存在座位id属于Long型,Protocol 虽然可以进行一定程度的压缩,但由于其算法对整型绝对值越小压缩比率越高的特点,我们仍然可以通过差值法进一步缩减Protocol 压缩比率,但从GZIP压缩后的结果来看已经足够小了。暂时未启动进一步优化。
相关链接:Google Developers | Protocol Buffers[1]
座位动态数据压缩
座位的动态数据,这里指的就是座位的状态。假设使用 2代表可售、8代表已售,早期大麦选座场景使用JSON来描述”座位id“与”状态“的映射关系。假定我们使用JSON格式以文本文件来存储“奥运体育场”座位状态,6万+个座位对应的状态文件的大小为1.8M。
1.8M看起来并不算很大,但对于先前提到的超级火爆的项目来说,开抢瞬间会出现庞大的目标用户在秒级区间涌入选座场景,服务器要想在极短时间处理如此高并发和数据分发所面临的压力是可想而知的,即便传输过程中使用了压缩方案。
因此早期使用JSON数据来表达座位状态的选座场景不得不从缓解服务端压力的角度改变请求策略:即“座位状态分组请求”,进入选座页按服务端给定的看台分组依次、延时进行请求,比如:把6万+个座位 按5000左右一组,每隔50ms请求一批,直到所有座位更新完毕。这意味着一个6万+座位的场馆仅其状态的请求就可能长达600ms以上,加之其他请求、视图渲染,这类超大型场馆的选座场景很难在1s以内完整加载并渲染完毕。
因此我们必须找到新的方案,它应该具备以下特征:一次请求可以获得全部座位状态、请求的数据量要足够的小、客户端设备解析的性能要足够的快。
座位动态压缩策略
所以选座场景推出了动态压缩方案,它本质上并不复杂,观察原始1.8M JSON文件,它的"大"主要是因为大量sid(座位id)的存在,JSON本身包含了一下冗余结构。如果移除这些sid呢? 假定座位如果在“静态座位文件”中是有序的,那么服务端就可以按照座位顺序堆积2、8状态(2代表可售、8代表已售)。比如一个看台编号为“3538263” 它有7个座位,座位状态依次是 “2222228”,那么它就可以由“繁复”的JSON的一部分转变为 :“3538263”:“2222228”
而一旦某个状态连续出现6个及以上时就可以缩写为 (x,s),上述case即可以缩写为 “3538263”:“(6,2)8”。字符的数量是浮动的,因此我们叫它动态压缩方案。
对比原JSON方案,我们考虑一个最为复杂的场景“奥运体育场”场馆座位,相邻的座位总是一个可售一个不可售,动态压缩无法进行缩写优化,那么使用JSON来返回6万+座位的文本文件大小约0.9M (即1.8M的二分之一,因为仅需要返回可售的即可)。如果使用动态压缩方案文本的大小约67KB,我们可以简化的认为这个文件中存储了6万+个连续"2"和"8",额外附加一下看台id信息。不难看出即便是最复杂的场景动态压缩方案描述状态的数据量也是非常小的。

那什么场景会触发极简压缩呢? 想象如下一个选座场景,刚刚开售,所有座位均未被售出,那么动态压缩方案就会处于极简压缩状态,举个例子: {"3538263":"5000,2"} 即代表"3538263"看台下的5000个座位均为可售~ 以测试使用的“奥运体育场”最复杂场景下估算:
压缩效率:座位状态动态压缩文件相比于JSON文本缩减了90%以上数据传输量。
解析速度:在该场景下使用一加7Pro:FastJson还原6万+座位耗时200ms,使用动态解压缩方案仅耗时5ms,解析时长缩短了95%以上。
视图层级优化
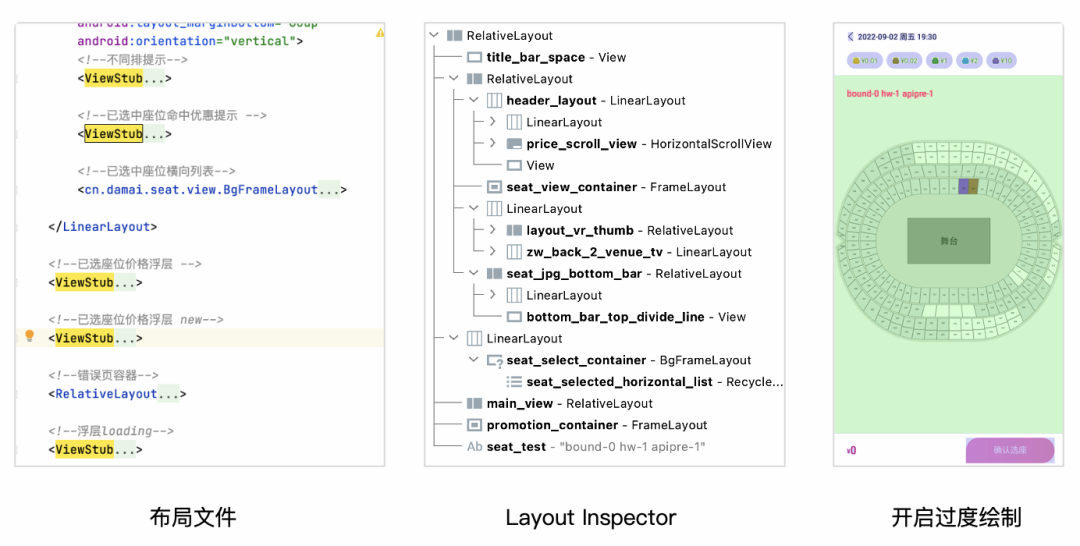
ViewStub
从上图"布局文件"中,选座场景是大麦中使用ViewStub最多的地方,一般可以被懒加载的视图均被转换成ViewStub,相比于复杂的”暂不可见“视图 ,ViewStub及其简洁,减少初始化渲染时View对象的创建和排版。
视图层级
从"Layout Inspector"可以看到选座场景的布局是相对简洁的,自上而下。”开启过度绘制“全屏处于浅绿色。为了减少视图层级,选座场景把App共用基类Activity多出用于Title、错误页等工具性布局都移除掉了,自身提供了非通用,但更简洁的布局,以减少视图层级结构。
绘制性能优化
座位位图复用
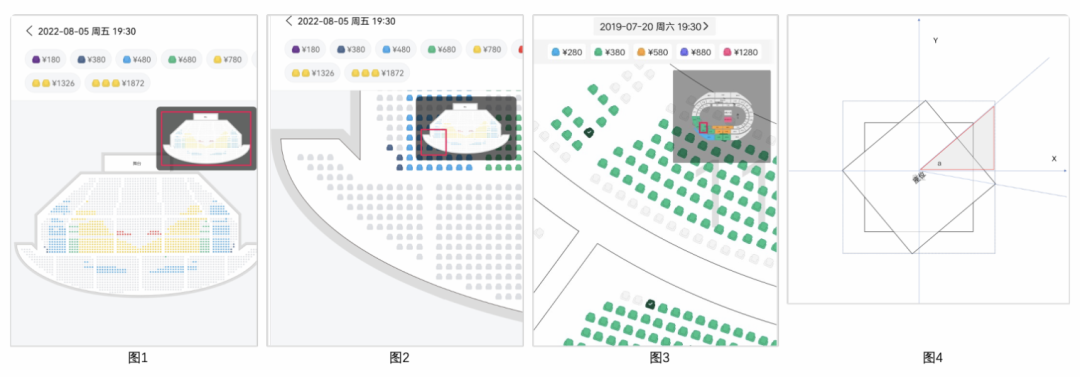
图1 为北京某场馆,座位近3000个。我们可以看到一个选座场景一般会包含多个票档,座位的颜色与其票档的颜色一致,一个座位最终如何展示是由:color (座位颜色)、angle(座位角度)、type(座位类型:已售、可售、锁定)、addAlpha(是否已选中)共同决定的,座位的位图是在绘制时根据上面4个要素实时通过SVG绘制出来的,相同4要素的座位会复用已经创建的同一位图。
原始方案把座位4要素组成一个字符串作为Key,通过HashMap进行座位位图复用,伪代码如下:
private final HashMap<String, Bitmap> mSeatPool = new HashMap();
public Bitmap get(int color, float angel, int type, boolean addAlpha) {
int angelInt = (int) angel;
String key = "key_" + color + "_" + angelInt + "_" + addAlpha + "_" + type;
Bitmap seat = mSeatPool.get(key);
if (seat == null) {
seat = newBitmap(color, angel, type, addAlpha);
mSeatPool.put(key, seat);
}
return seat;
}位图复用的思路是正确的,但是原方案使用的字符串作为Key带来2个问题,1是字符串拼接的本质是StringBuilder对象的创建;2是字符串拼接的字符数量>16个会触发StringBuilder的ensureCapacityInternal方法;以上述场馆为例每次touch事件导致的绘制都会创建近3000个StringBuilder对象、并触发其扩充API。反复滑动时必然会导致内存快速增长、GC的频繁发生。
我首先想到类似的场景就是Android 视图测量中使用到的View.MeasureSpec,MeasureSpec将int值高2位存储为Mode,低30位存储为size。利用相同的思路作用于位图复用是非常适用的,优化后选座使用Long值作为Key存储座位4要素,高8位存储位图addAlpha(是否选中),9-16位存储type(座位类型:已售、可售、锁定),17-32位存储angle(座位角度),最后32位存储color(座位颜色),并且使用Android系统优化过的LongSparseArray替代HashMap。这有几个好处,Key值的计算全程使用位运算,运算速度足够的快,反复滚动时不会再触发StringBuilder对象的创建和扩充,内存不会出现激增现象,视图滑动平均帧率提升了4帧以上。
利用Android Studio Profiler性能分析工具,对位图复用前后进行对比:
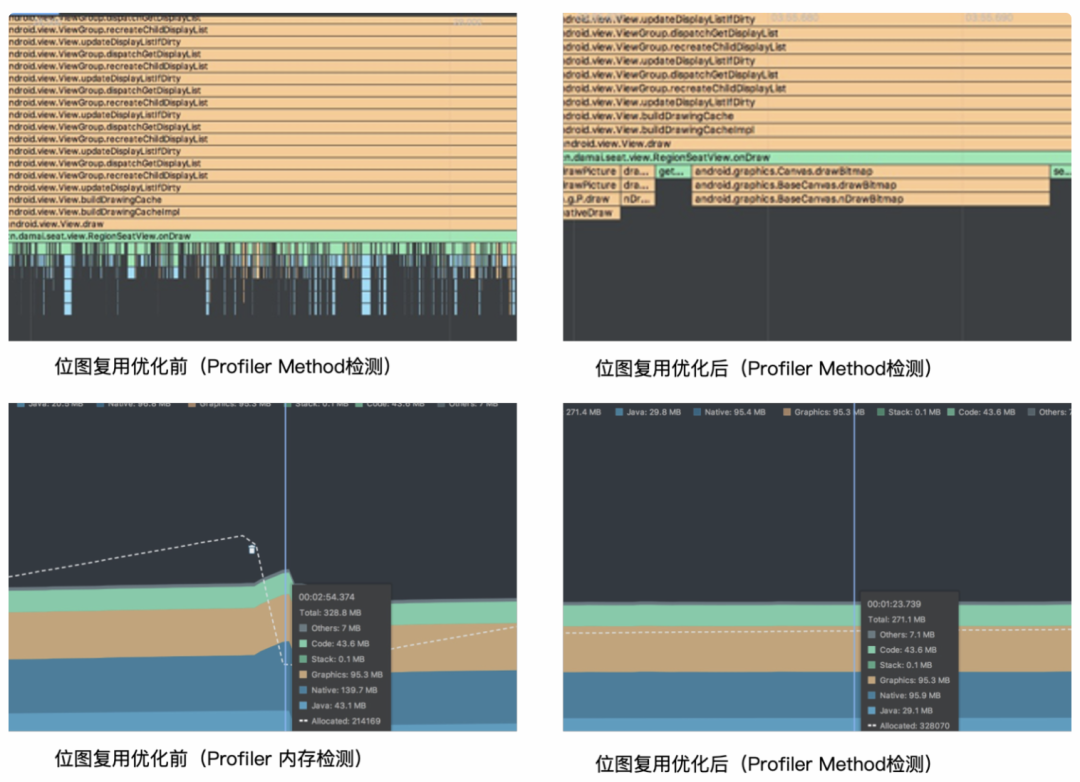
- 优化前的方案在选座视图滑动时存在了大量的StringBuilder对象创建,导致Profiler Method视图存在大量锯齿。优化后不会在出现大量锯齿,onDraw()中不会在出现对象创建场景。
- 从内存的角度上看,优化前滑动时会导致内存快速增长,从图中可以看到很快即有270M增长到328M,并触发一轮GC,而这样的事情会在反复滑动、缩放动画中一直出现,这种内存的抖动势必会影响到绘制性能,虽然GC几经Google优化,但仍然避免不了”stop the world“。优化后我们可以看到不管如何滑动内存始终保持在270M左右。
绘制提效优化
如果只是一张座位的位图,其绘制成本是非常低的。但是当量级足够大时,绘制的性能将受到影响,以图1北京某场馆为例,一次onDraw()就需要绘制近3000次座位位图,这对于客户端设备是有一定挑战的。因此选座场景针对大场馆,初始化展示时仅展示看台图,当用户选中某个看台时会自动放大适配屏幕,将处于屏幕中的看台下的座位及其周边可见的座位实时绘制出来。针对小场馆,仅出现在屏幕中的座位会被绘制。这种小技巧对提升绘制效率非常有效。
角度计算优化
图3所示,可以看到座位可能存在角度,其一般指向舞台中心。端设备在实时绘制座位时,需要实时计算放大缩小比率结合座位偏转角度才能最终计算出座位的大小。
早期选座场景使用Matrix来计算角度问题,平时的绘制我们也可能使用Matrix进行相关计算,但无疑在这个地方Matrix矩阵计算是浪费性能的。相反优化后使用Math三角函数进行计算大幅度提升了带角度的座位大小计算性能。
浮点数据计算优化
当座位大小实时计算完毕,我们发现在使用Canvas进行绘制时,如果将float转换成int时,会带来非常好的性能提升。但这也会带来一定的体验问题,为什么呢?如果不做任何处理即将浮点转成整型,实时滑动时就可能会出现座位由于精度问题而产生抖动。因此选座场景在这里做了近似处理,在合理阈值内进行int转换,即利用整型值计算优势同时将抖动降低到不明显可接受程度。
硬件加速
早期的选座场景并未开启硬件加速,你可能会惊讶于视图为什么没有开启硬件加速,因为绝大多数场景我们并没有主动关心过硬件加速,因为系统默认的View和一般的自定义View默认就是开启的。为什么早期的选座场景要主动关闭硬件加速呢?
从选座场景上看我们使用了大量的SVG,无论是场馆底图、场馆图、座位位图都使用了SVG进行绘制,我们可以简单的把一个SVG看成一个有序的、可绘制的指令集合,在Android中我们需要一个简单的可被复用的绘制“容器”,而这个“容器”就是android.graphics.Picture。查看Picture的类描述我们会发现它真的很适合用来记录可绘制指令,但它仍然存在一些问题,以下是类官方描述:
A Picture records drawing calls (via the canvas returned by beginRecording) and can then play them back into Canvas (via draw(Canvas) or Canvas.drawPicture(Picture)).For most content (e.g. text, lines, rectangles), drawing a sequence from a picture can be faster than the equivalent API calls, since the picture performs its playback without incurring any method-call overhead.
Note: Prior to API level 23 a picture cannot be replayed on a hardware accelerated canvas.
从类描述中的“Note”可以看到在API Level 23以下的设备无法使用硬件加速,查阅Google开发者文档也可以看到,下方图片是Google对可支持硬件加速绘制指令、以及第一个支持的Api Level进行了一段描述。可以发现在API 28是一个分水岭,绝大多数指令在28及以上得到了支持。
硬件加速方案:
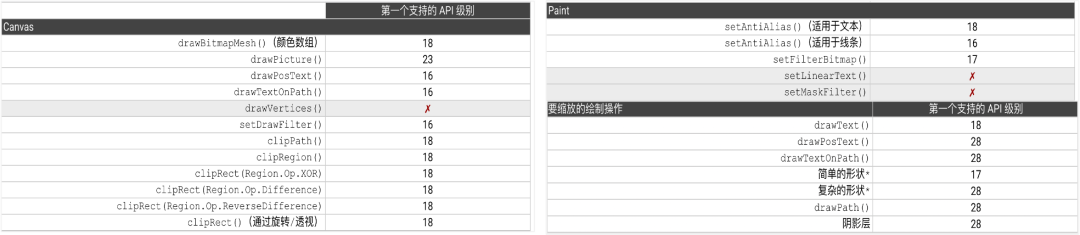
优化方案对API Level进行区分即可,28以下的设备仍然保持早期的使用软件层进行绘制的方案,对始终不支持硬件加速的绘制指令进行了评估确保我们的生产SVG工具中不会出现这些指令,并添加了远程开关以确保遇到问题可实时关闭硬件加速功能,当设备API LEVEL >=28时开启硬件加速。此后选座Android场景的滑动平均帧率终于在这个阶段突破了50FPS。
相关链接:Android开发者 | 硬件加速[2]
线程任务处理
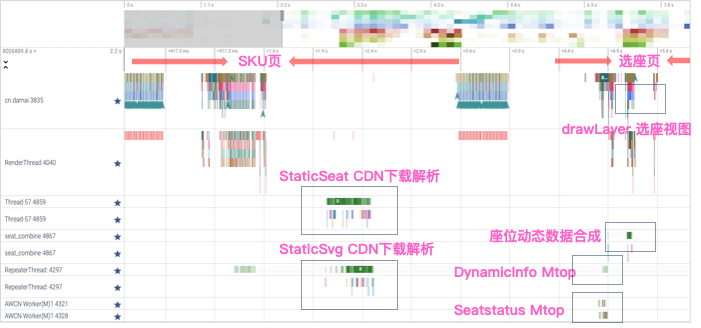
在接口的预加载策略中有提到选座场景对选座”渲染时“使用到的请求根据其请求的数据特点、时效要求进行了分阶段、策略性前置。使得渲染时不会在选座页面的onCreate()同时并发5个以上的网络请求。从性能分析工具Perfetto我们可以看到主线程、静态座位数据下载解析线程、静态SVG下载解析线程等的时间轴即任务处理情况。
- 从Perfetto中我可以观察到分散的策略是生效的,静态座位、SVG在SKU页闲时触发了下载并完成了解析、内存缓存。
- 从Perfetto中关键的渲染任务相关线程无明显的阻塞现象发生。
- 在进入选座页的同时DynamicInfo 请求、SeatStatus 请求很快被发起。
- 座位动态解压缩方案在座位合成过程中非常快速的完成了座位状态合成。
相关工具链接:Perfetto工具[3]
总结
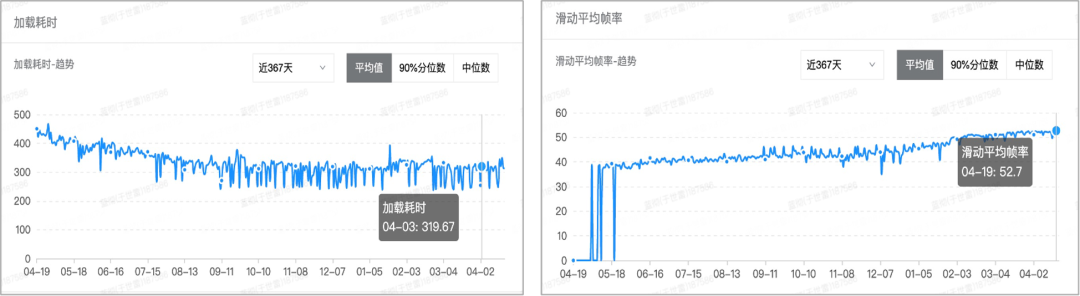
下图是21年选座场景在性能监控工具上页面加载时长、滑动平均帧率。可以看到页面加载时长呈现明显的下降趋势,而滑动平均帧率呈现明显的上升趋势。实际上大麦选座场景的页面加载速度超过了APP自身 80%以上的核心页面,而选座场景同时也是这些核心页面中网络使用、数据处理最为复杂的页面之一。
截止2022年6月份 ,页面平均加载时长由20年的850ms下降到当前的320ms,页面滑动平均帧率由20年的38帧上升到54帧。选座场景的优化并不是一蹴而就的,而是经历了长期的、持续的性能优化~
以此篇文章,整理记录一下选座场景在持续提升用户体验过程中做过的一些努力 ~
参考资料
[1]Google Developers | Protocol Buffers: https://developers.google.com/protocol-buffers/
[2]Android开发者 | 硬件加速: https://developer.android.google.cn/guide/topics/graphics/hardware-accel
[3]Perfetto工具: https://ui.perfetto.dev/#