Android 图形显示系统汇总
简介
本文将从整体上分析Android图形显示系统的结构,不深入分析每一层内部的代码实现,更多的是使用流程图和结构图来让大家理解Android是如何绘制、合成图形并显示到屏幕上。
本文将从三个层次进行讲解,大致如下图:
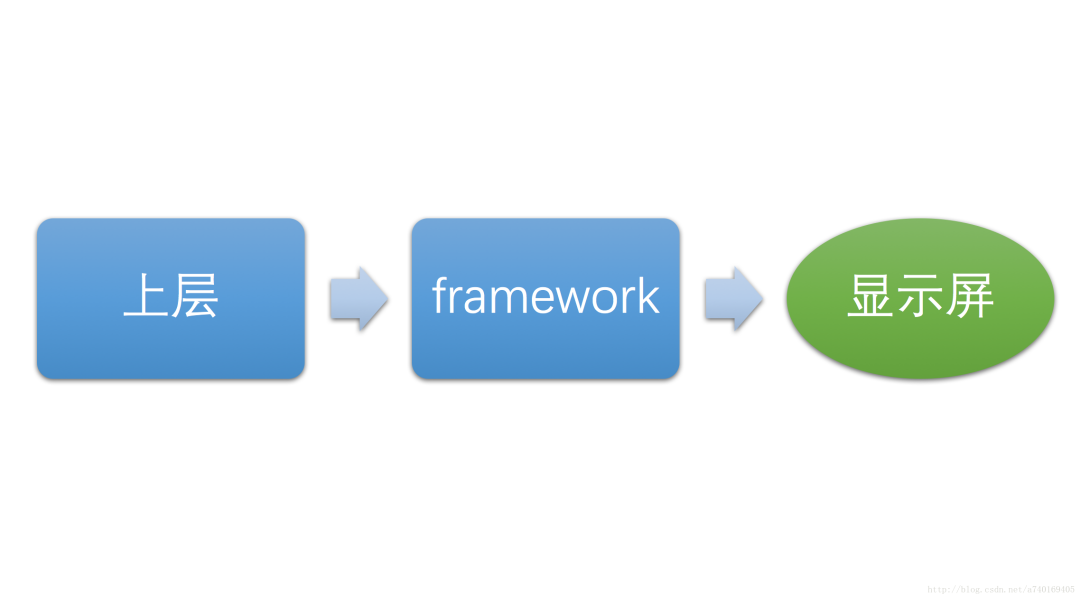
可以理解为上层生产,下层消费模型。
其中每一层之间的数据传递是使用Buffer(图形缓冲区)作为载体:
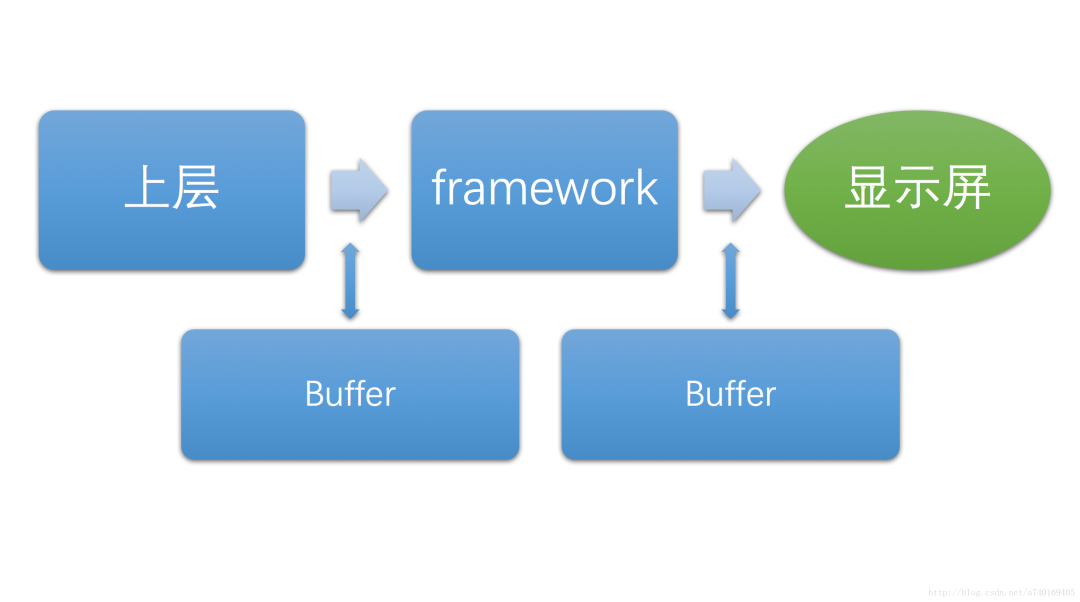
这里的缓冲区,大家可以理解为带有宽高和像素密度的内存区块。
-
从下层往上层理解
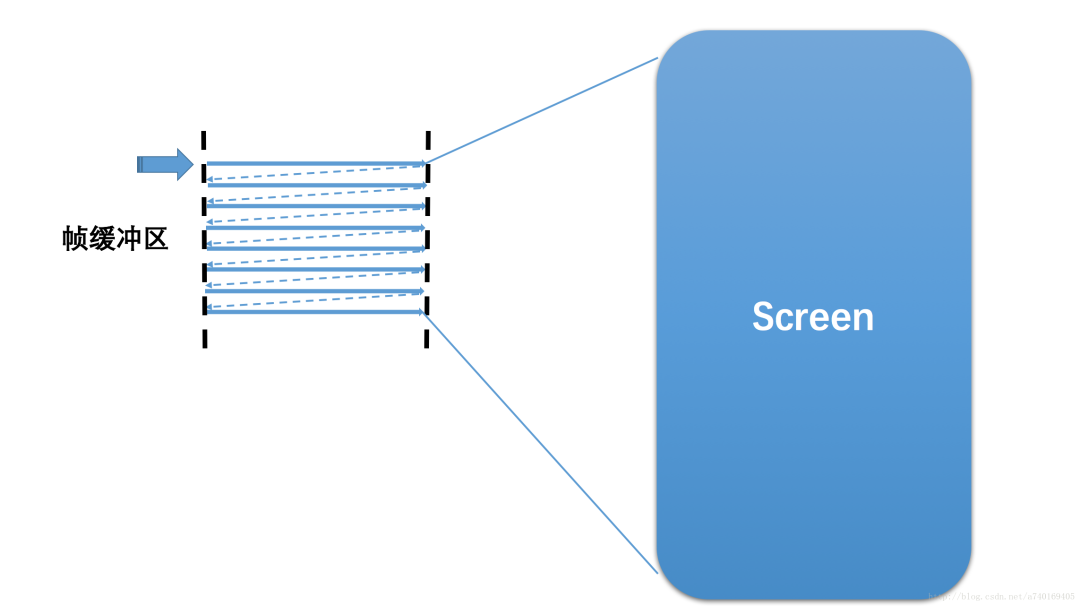
1.1 显示屏
显示屏上的内容,是从硬件帧缓冲区读取的,大致读取过程为:从Buffer的起始地址开始,从上往下,从左往右扫描整个Buffer,将内容映射到显示屏上:
当然,屏幕上的内容需要需要不断的更新,如果在同一个Buffer进行读取和写入(合成)操作,将会导致屏幕显示多帧内容。所以硬件层除了提供一个Buffer用于屏幕显示,还提供了一个Buffer用于后台的图形合成,也就是我们常说的双缓冲:
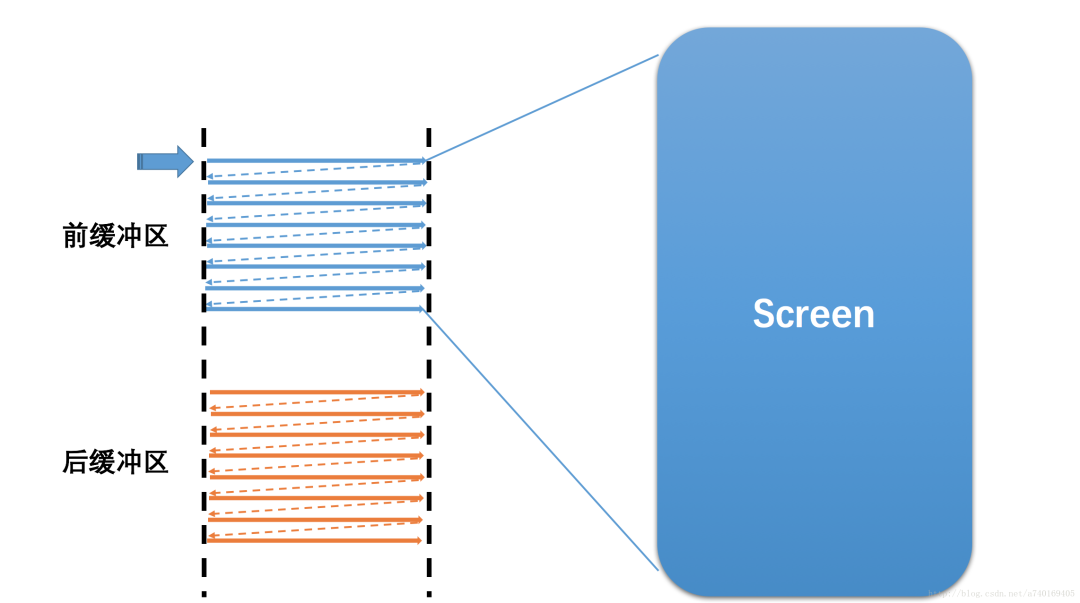
上图中包含两个缓冲区:
前缓冲区:用来显示内容到屏幕的帧缓冲区
后缓冲区:用于后台合成下一帧图形的帧缓冲区
假设前一帧显示完毕,后一帧准备好了,屏幕将会开始读取下一帧的内容,也就是开始读取上图中的后缓冲区的内容:
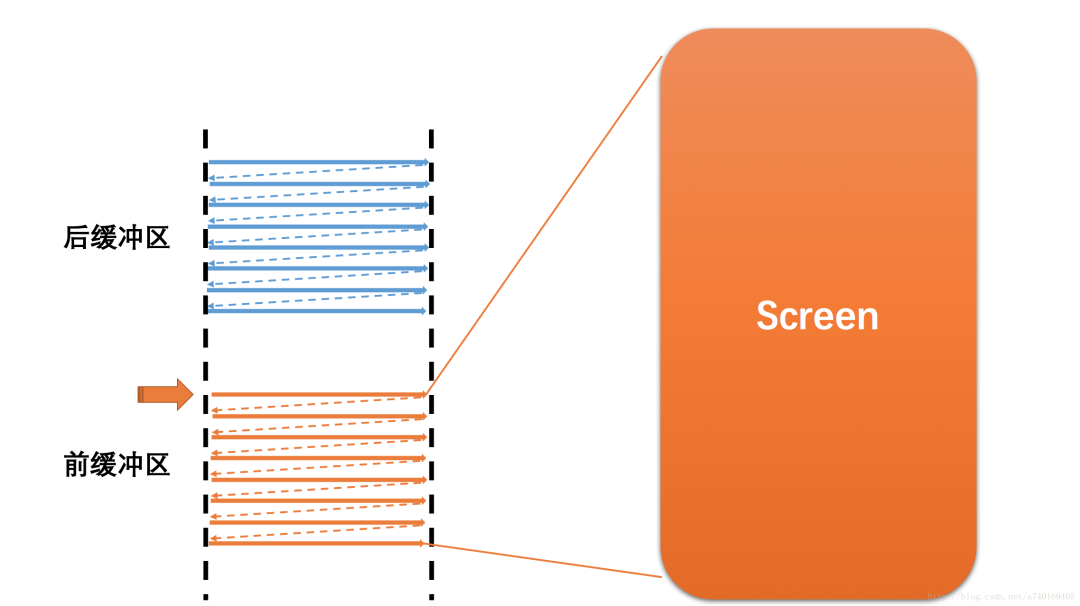
此时,前后缓冲区进行一次角色互换,之前的后缓冲区变为前缓冲区,进行图形的显示,之前的前缓冲区则变为后缓冲区,进行图形的合成。
然而,理想很丰满,现实很骨感,上面假设“当前一帧显示完毕,后一帧准备好了”的情况,在现实中这两个事件并非同时完成。那么,屏幕扫描缓冲区的速度和系统合成帧的速度之间有什么关系呢,带着这个疑惑我们看看下面两个概念:
屏幕刷新率(HZ):代表屏幕在一秒内刷新屏幕的次数,Android手机一般为60HZ(也就是1秒刷新60帧,大约16.67毫秒刷新1帧)
系统帧速率(FPS):代表了系统在一秒内合成的帧数,该值的大小由系统算法和硬件决定。
我们用以下两个假设来分析两者的关系:
① 屏幕刷新速率比系统帧速率快
此时,在前缓冲区内容全部映射到屏幕上之后,后缓冲区尚未准备好下一帧,屏幕将无法读取下一帧,所以只能继续显示当前一帧的图形,「造成一帧显示多次,也就是卡顿。」
② 系统帧速率比屏幕刷新率快
此时,屏幕未完全把前缓冲区的一帧映射到屏幕,而系统已经在后缓冲区准备好了下一帧,并要求读取下一帧到屏幕,将会导致屏幕上半部分是上一帧的图形,而下半部分是下一帧的图形,「造成屏幕上显示多帧,也就是屏幕撕裂。」
上面两种情况,都会导致问题,根本原因就是两个缓冲区的操作速率不一致,解决办法就是让屏幕控制前后缓冲区的切换,让系统帧速率配合屏幕刷新率的节奏。
那么屏幕是如何控制这个节奏的呢?
垂直同步(VSync):当屏幕从缓冲区扫描完一帧到屏幕上之后,开始扫描下一帧之前,发出的一个同步信号,该信号用来切换前缓冲区和后缓冲区。
通过上面的分析可以看出,屏幕的显示节奏是固定的,操作系统需要配合屏幕的显示,在固定的时间内准备好下一帧,以供屏幕进行显示。两者通过VSync信号来实现同步。
关于屏幕这一块的知识点讲解到这,不再深入分析,接下来我们将会了解后缓冲区的图形合成者。
1.2 SurfaceFlinger-图形合成者
如果说屏幕是消费者,那么SurfaceFlinger相对屏幕来说就是生产者,其具有如下特性:- 作为上层应用的消费者,硬件层的生产者。
- 负责图形的合成
- 和ActivityManagerService一样,是一个系统服务
为了更好的理解SurfaceFlinger这个服务的工作内容,以及他是如何做到一个承上启下的作用,我们通过下面的这个界面分析:
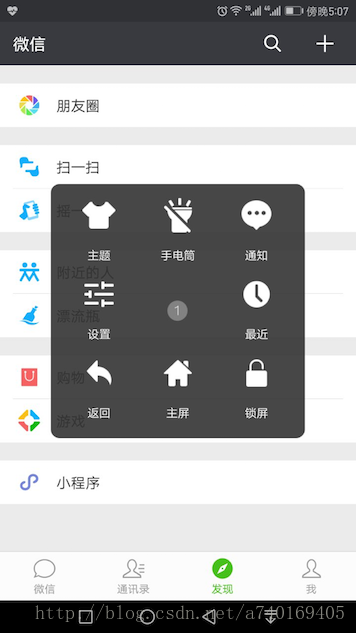
界面很简单,拆开来看,包含微信、悬浮工具箱、通知栏、底部虚拟按键栏:
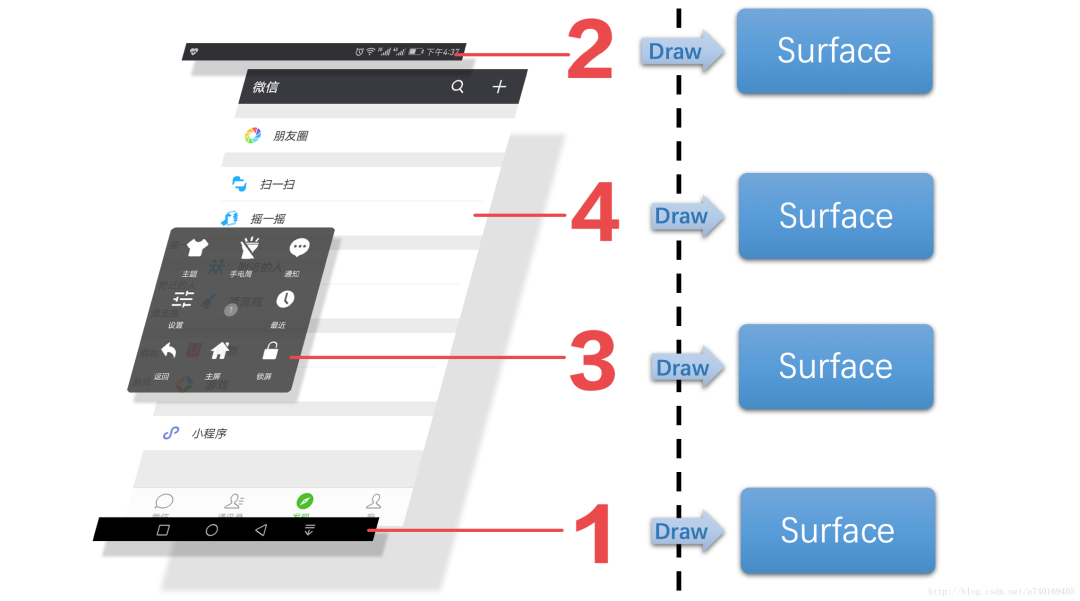
我们可以先这样理解上面这幅图,上层每一个界面,其实都对应SufaceFlinger里的一个Surface对象,上层将自己的内容绘制在对应的Surface内,接着,SufaceFlinger需要将所有上层对应的Surface内的图形进行合成,具体看下图:
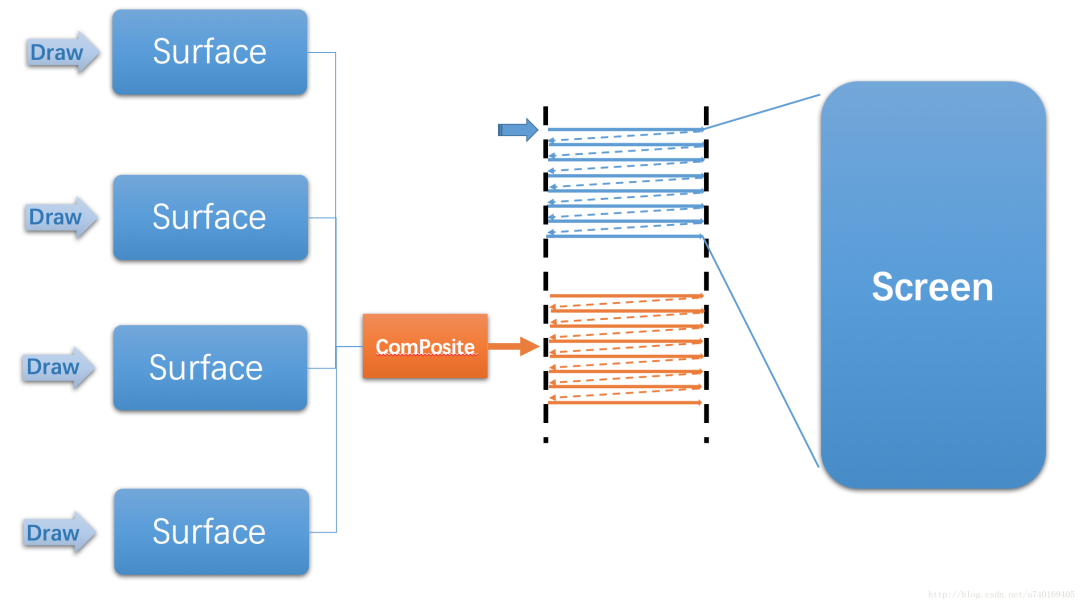
没错,SurfaceFlinger就是将多个Surface里的内容进行合成,最后提交到屏幕的后缓冲区,等待屏幕的下一个垂直同步信号的到来,再显示到屏幕上。
我们会发现SufaceFlinger通过屏幕后缓冲区与屏幕建立联系。同时通过Surface与上层建立联系。从而起到一个承上启下的作用,是Android图形系统结构中的关键组成部分。
为了继续往上层讲,我们需要了解什么是Surface:
- 对应上层的一个Window(对话框、Activity、状态栏)
- 作为上层图形绘制的「画板」
- Canvas是「画笔」,上层通过调用Canvas的API向Surface上绘制图形
- Surface内部存在多个缓冲区,形成一个BufferQueue
如果说SurfaceFinger是图形的合成者,那么图形的提供者就是上层。文章一开始就提到,图形的传递是通过Buffer作为载体,Surface是对Buffer的进一步封装,也就是说Surface内部具有多个Buffer供上层使用,如何管理这些Buffer呢?请看下面这个模型:
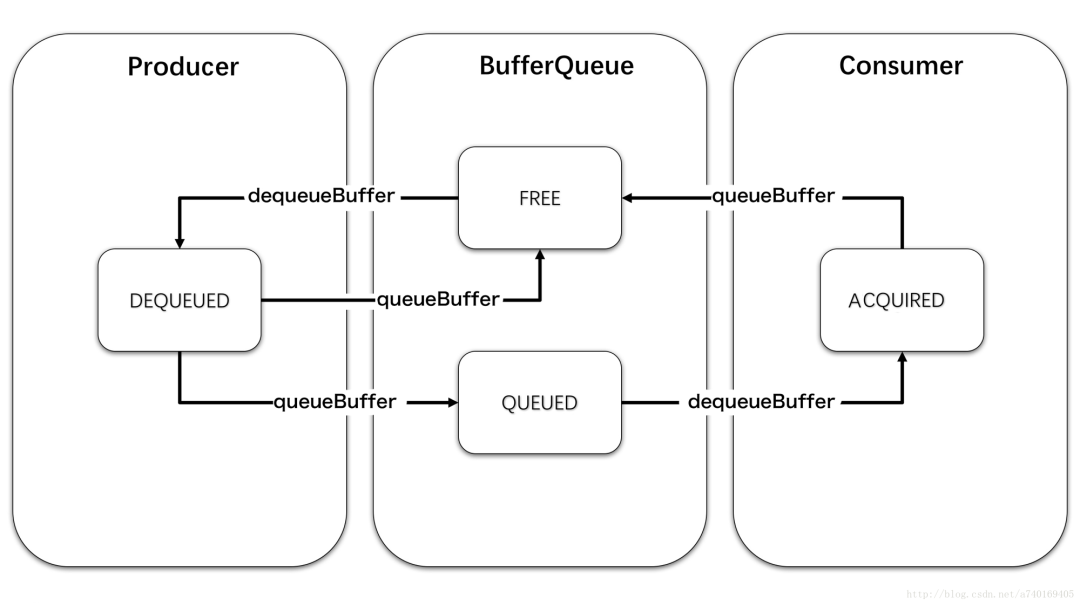
Surface内部提供一个BufferQueue,与上层和SurfaceFlinger形成一个生产者消费者模型,上层对应Producer,SurfaceFlinger对应Consumer。三者通过Buffer产生联系,每个Buffer都有四种状态:
- Free:可被上层使用
- Dequeued:出列,正在被上层使用
- Queued:入列,已完成上层绘制,等待SurfaceFlinger合成
- Acquired:被获取,SurfaceFlinger正持有该Buffer进行合成
Buffer的一次转移过程大致为:
- 从BufferQueue转移到上层
- 上层绘制完成再放回BufferQueue
- 接着SurfaceFlinger再拿去合成
- 最后又放回BufferQueue
如此循环,形成一个Buffer被循环使用的过程。关于SurfaceFlinger以及SurfaceFlinger与上层建立联系的Surface讲解完了,接下来看看上层是如何将图形绘制到Surface的Buffer中。
1.3 上层绘图
上层绘图的大体流程见下图:
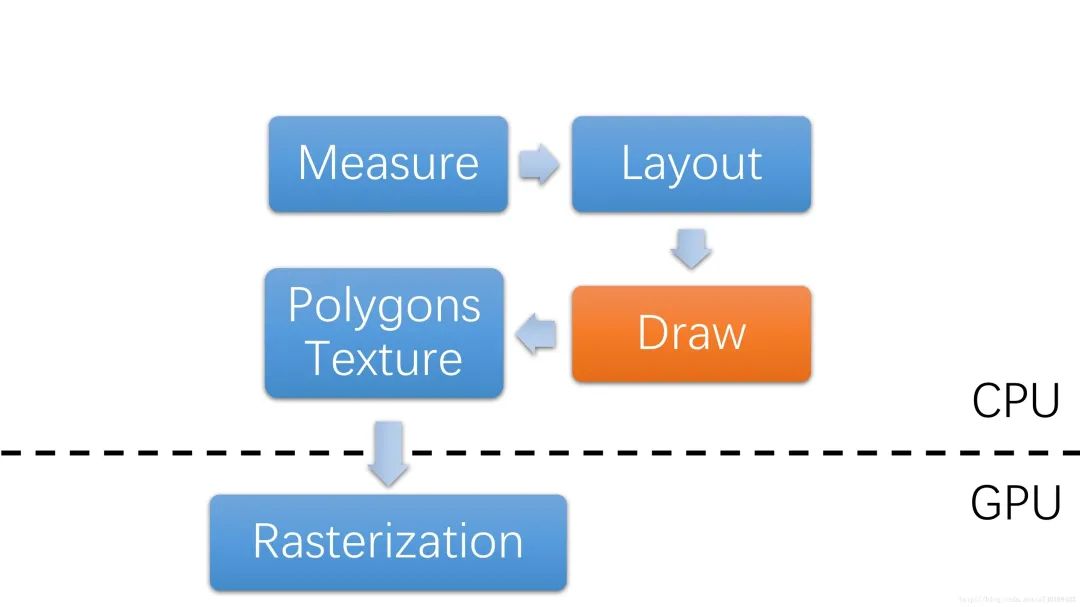
之前有说到,Surface里的Buffer作为上层的画板,Canvas作为画笔,通过调用Canvas的API完成图形的绘制,上层通过调用draw方法来调用Canvas的API,当然这里的draw方法并没有真正的将图形绘制到缓冲区,而是记录了一下绘制命令,具体需要了解DisplayList相关只是,后面会对其进行分析。
从流程上看:
- 测量View的宽高(Measure)
- 设置View的宽高位置(Layout)
- 创建显示列表,并执行绘制(Draw)
- 生成多边形和纹理
- 对多边形和纹理进行栅格化操作
从执行者的角度看:
- CPU:Measure,Layout,纹理和多边形生成,发送纹理和多边形到GPU
- GPU:将CPU生成的纹理和多边形进行栅格化以及合成
上面说的的纹理和多边形还有栅格化以及合成,这里不做具体的讲解,需要了解的是图形的绘制流程需要经过这些操作。从上面的分析可以看出,上层绘制图形时需要经过CPU计算,再经过GPU计算。
经过上面的分析,整个Android的图形绘制大体流程已经分析完成,接下来将会分析一些流程的具体实现,分析的内容包括:
- Android 4.1 加入的VSync信号同步到上层以及三缓冲
- 从上层往下层具体分析每一步流程
-
VSync以及三缓冲
2.1 Drawing Without VSync
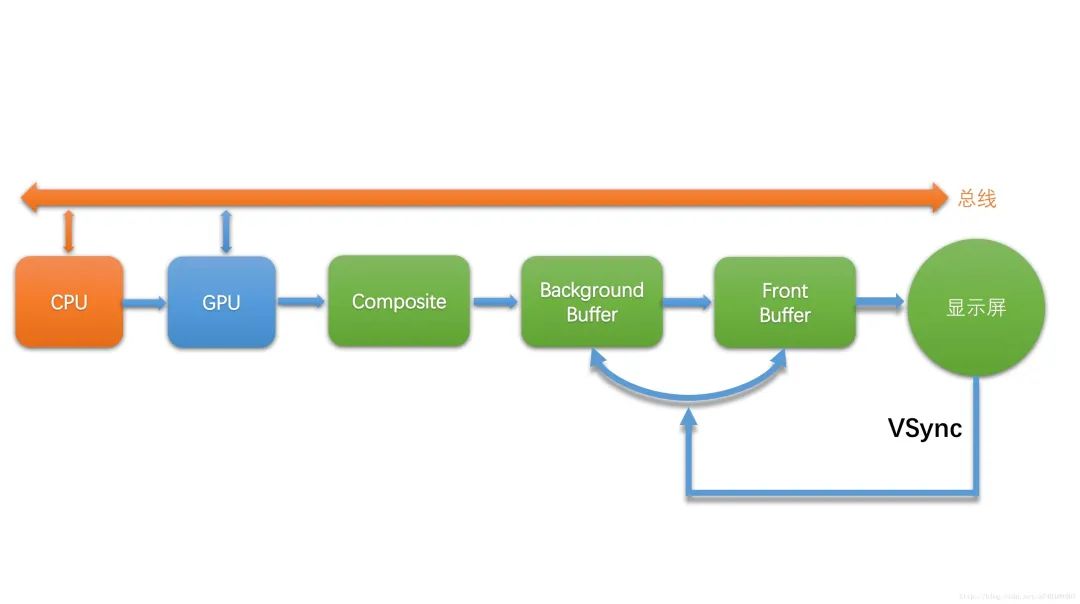
从上面的讲解可以看出,整个绘制流程的节奏,分成两个生产者消费者模型,一个由屏幕和SurfaceFlinger构成,另一个由SurfaceFlinger和上层应用构成,具体流程可以用下图来描述:
其中:
- CPU和GPU代表上层的绘制执行者
- Composite代表的是SurfaceFlinger对多个Surface的合成
- Background Buffer和Front Buffer分别代表的是硬件帧缓冲区中的前缓冲和后缓冲
- 显示屏扫描完一帧之后,会发出VSync信号来切换并显示下一帧
上面的流程中,存在一个问题,屏幕的VSync信号只是用来控制帧缓冲区的切换,并未控制上层的绘制节奏,也就是说上层的生产节奏和屏幕的显示节奏是脱离的:
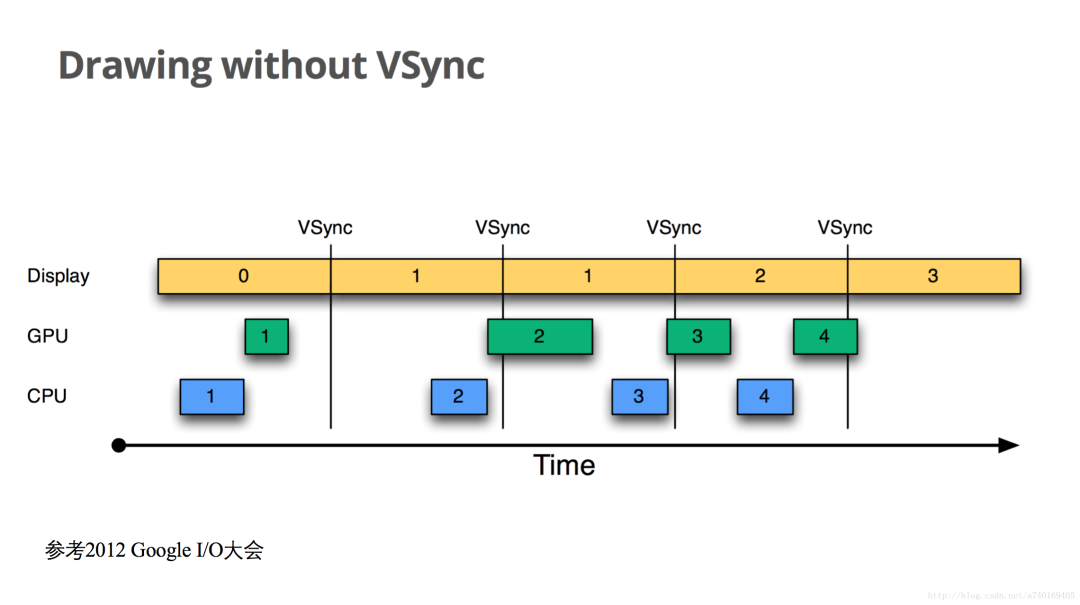
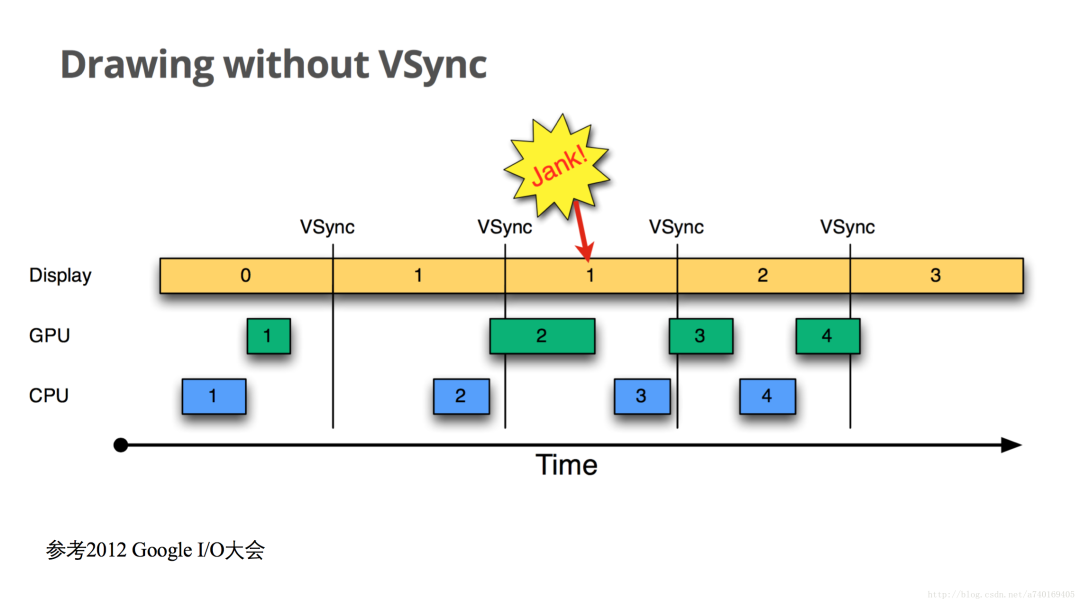
上图中,横轴表示时间,纵轴表示Buffer的使用者,每个长方形表示Buffer的使用,长方形的宽度代表使用时长,VSync代表垂直同步信号,两个VSync信号之间间隔16.6ms。此图描述了Android在4.1系统版本之前,上层的绘图流程在没有VSync信号的时候,出现的绘制问题。
我们从时间为0开始看,当前屏幕显示第0帧,上层CPU开始计算第1帧的纹理,计算完成后,交由GPU进行栅格化。当下一个垂直同步信号到来,屏幕显示下一帧,这时候,上层CPU并未马上开始准备下一帧,而当CPU开始准备下一帧的时候已经太晚了,下一个VSync信号来临的时候,GPU未能绘制完第二帧的处理,导致屏幕再次显示上一帧,造成卡顿:
2.2 Drawing With VSync
因为上层不知道VSync信号已经发出,导致上层未能开始CPU的计算。google在Android 4.1系统中加入了上层接收垂直同步信号的逻辑,大致流程如下:
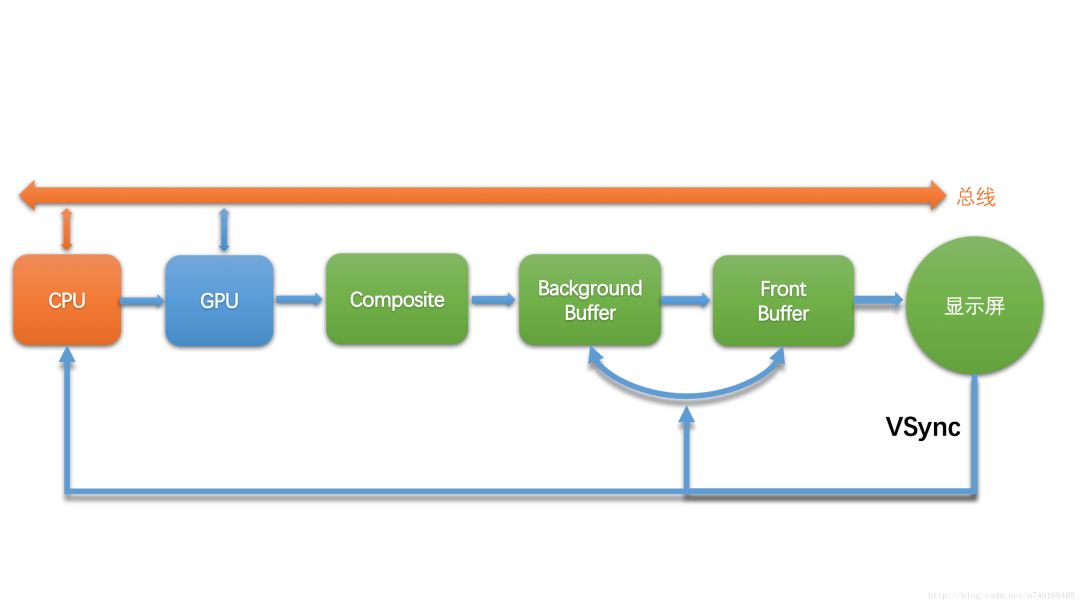
也就是说,屏幕在显示完一帧后,发出的垂直同步除了通知帧缓冲区的切换之外,该消息还会发送到上层,通知上层开始绘制下一帧。
那么,上层是如何接受这个VSync消息的呢?
2.2.1 Choreographer VSync信号的上层接收者
Google为上层设计了一个Choreographer类,翻译成中文是“编舞者”,是希望通过它来控制上层的绘制(舞蹈)节奏。首先看看Choreographer的类图:
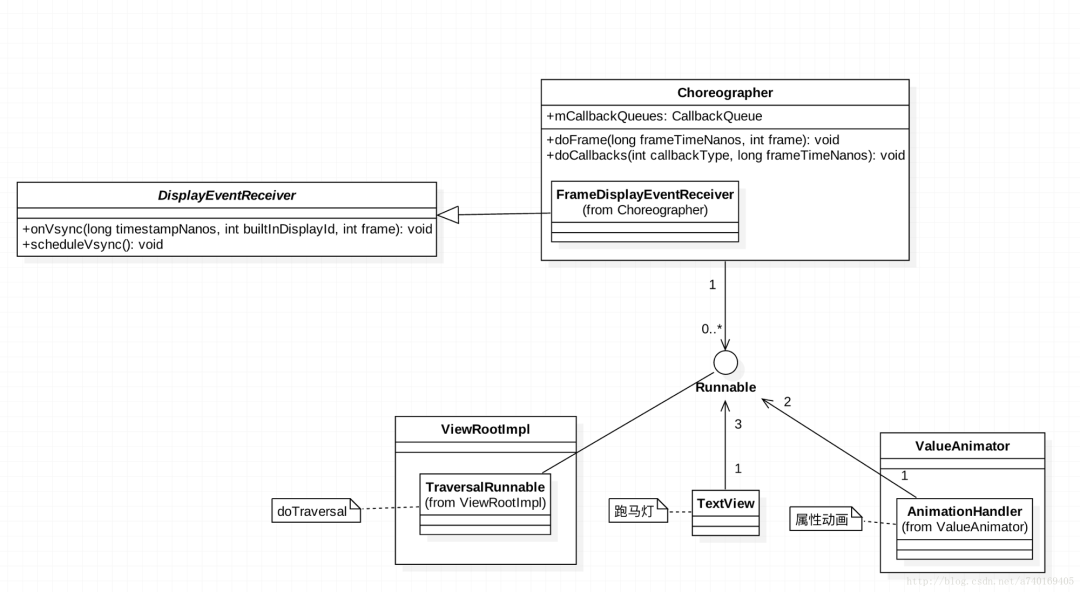
可以发现,Choreographer需要向SurfaceFlinger来注册一个VSync信号的接收器DisplayEventReceiver。同时在Choreographer的内部维护了一个CallbackQueue,用来保存上层关心VSync信号的组件,包括ViewRootImpl,TextView,ValueAnimator等。
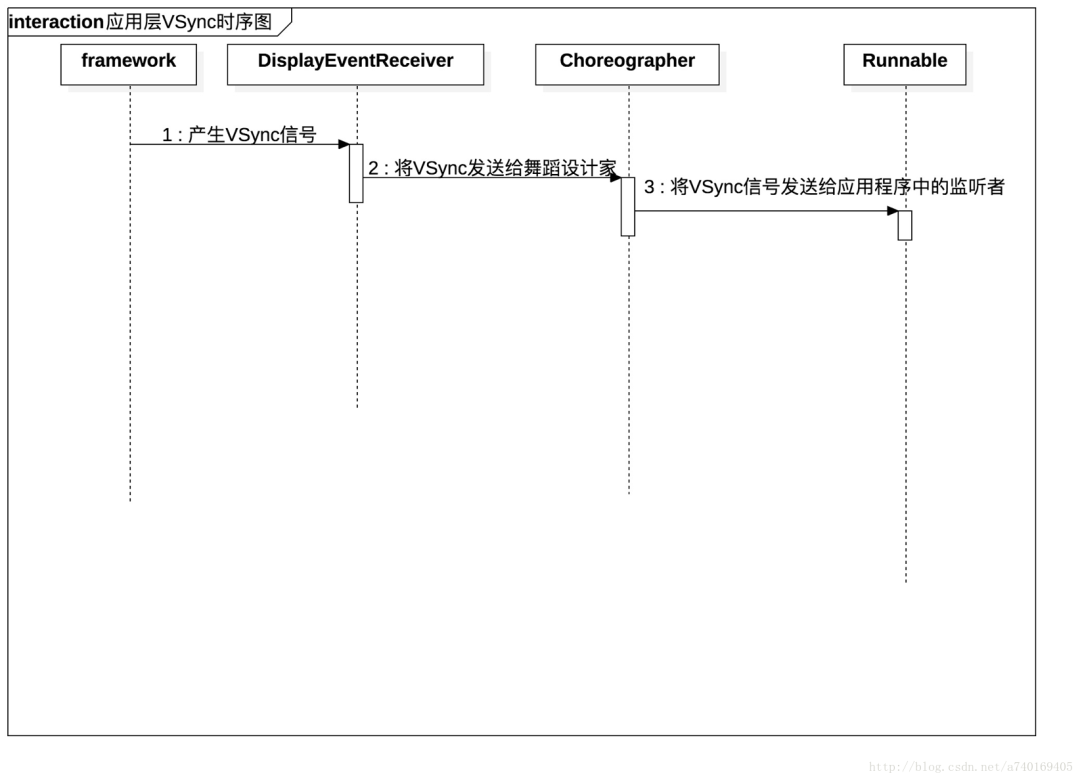
再看看上层接收VSync的时序图:
知道了Choreographer是上层用来接收VSync的角色之后,我们需要进一步了解VSync信号是如何控制上层的绘制的:
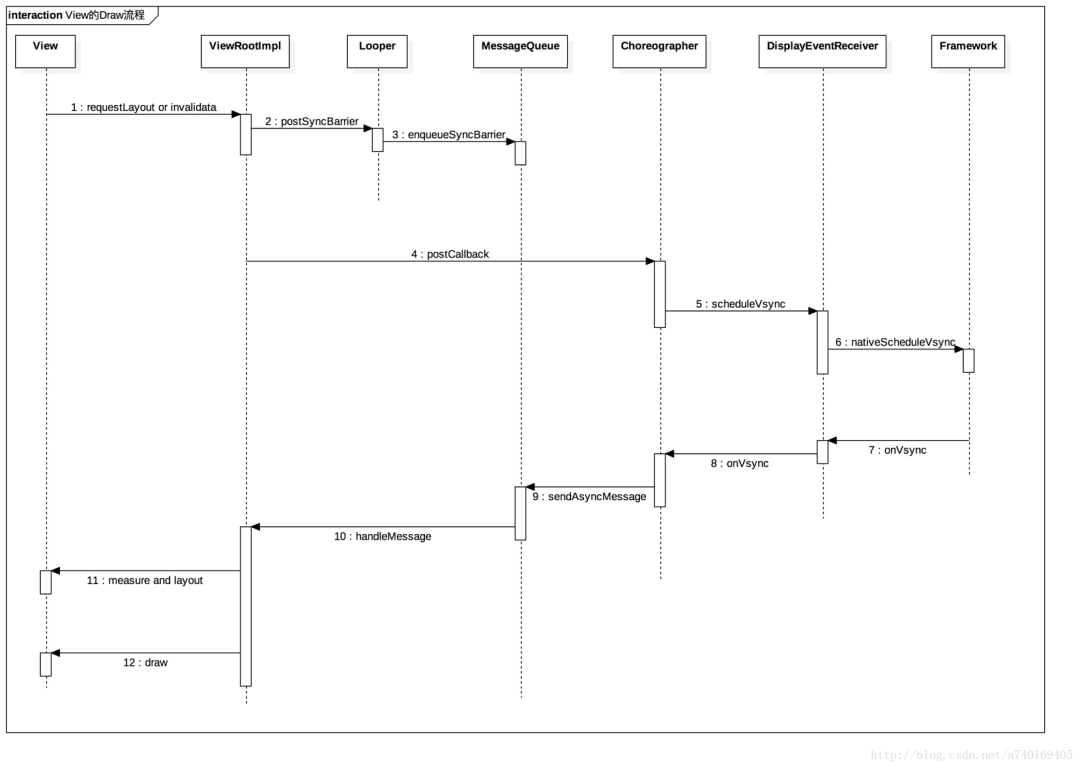
一般,上层需要绘制新的UI都是因为View的requestLayout或者是invalidate方法被调用触发的,我们以这个为起点,跟踪上层View的绘制流程:
- requestLayout或者invalidate触发更新视图请求
- 更新请求传递到ViewRootImpl中,ViewRootImpl向主线程MessageQueue中加入一个阻塞器,该阻塞器将会拦截所有同步消息,也就是说此时,我们再通过Handler向主线程MessageQueue发送的所有Message都将无法被执行。
- ViewRootImpl向Choreographer注册下一个VSync信号
- Choreographer通过DisplayEventReceiver向framework层注册下一个VSync信号
- 当底层产生下一个VSync消息时,该信号将会发送给DisplayEventReceiver,最后传递给Choreographer
- Choreographer收到VSync信号之后,向主线程MessageQueue发送了一个异步消息,我们在第二步提到,ViewRootImpl向MessageQueue发送了一个同步消息阻塞器。这里Choreographer发送的异步消息,是不会被阻塞器拦截的。
- 最后,异步消息的执行者是ViewRootImpl,也就是真正开始绘制下一帧了
至此,底层的VSync控制上层的逻辑就解释完了,此时上层绘制图形的流程与VSync信号的关系可以用下图表示:
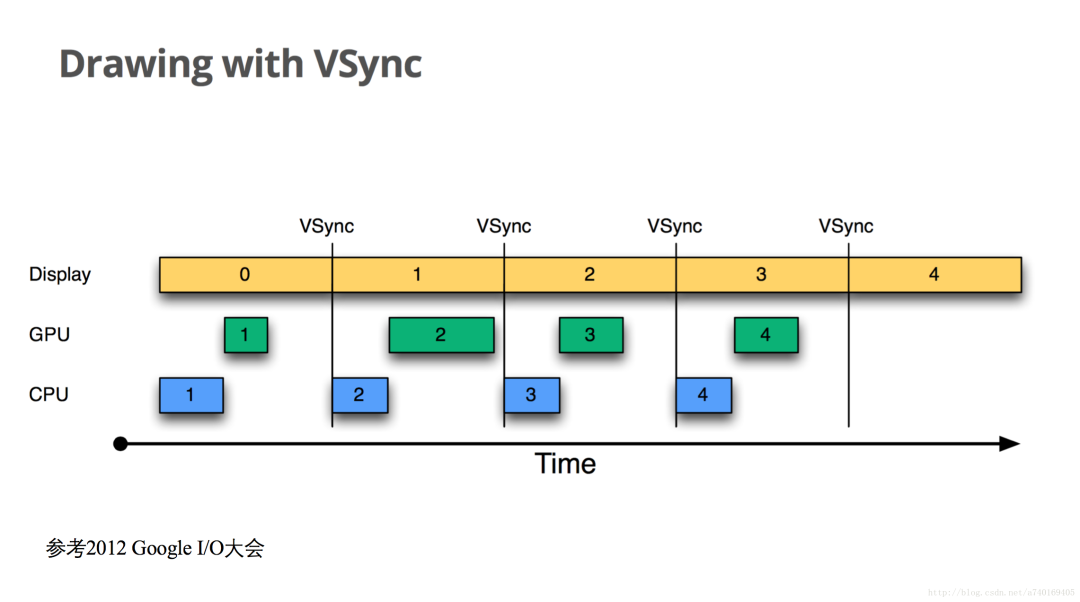
时间从屏幕显示第0帧开始,CPU开始准备第1帧图形的处理,好了之后交给GPU进行处理,在上层收到下一个VSync之后,CPU立马开始第2帧的处理,上层绘图的节奏就和VSync信号保持一致了,整个绘图非常流畅。
然而,理想很丰满,现实很骨感,如果CPU和GPU没能在下一个VSync信号到来之前完成下一帧的绘制工作,又会是怎么样的呢?
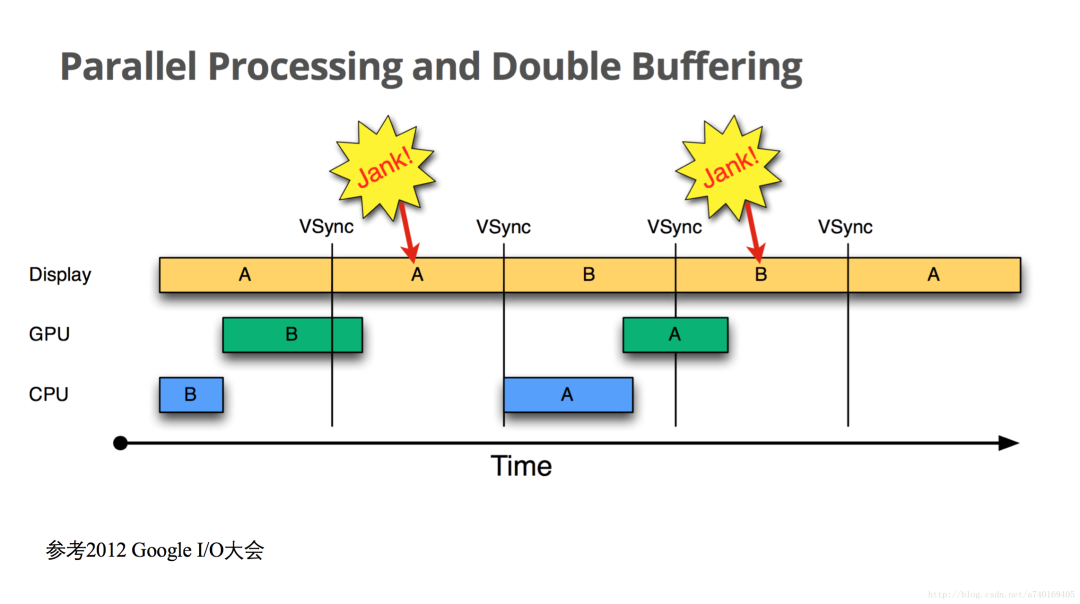
还是从屏幕显示第A帧开始,时间进入第一个16.6ms,CPU和GPU合成第B帧,当下一个VSync信号到来的时候,GPU未能及时完成第B帧的绘制,此时,GPU占有一个Surface里的Buffer,而同时SurfaceFlinger又持有一个Buffer用于合成显示下一帧到屏幕,这样的话,就导致Surface里的两个缓冲区都被占用了。此时SurfaceFlinger只能使用第A帧已经准备好的Buffer来合成,GPU继续在另一个缓冲区中合成第B帧,此时CPU无法开始下一帧的合成,因为缓冲区用完了。另外一个不好的事情是CPU只有在VSync信号来的时候才开始绘制下一帧,也是就是说在第二个16.6ms时间内,CPU一直处于空闲状态,未进行下一帧的计算。
只有等到第二个VSync信号来了之后,CPU才开始在绘制下一帧。如果CPU和GPU需要合成的图形太多,将会导致连续性的卡顿,如果CPU和GPU大部分时候都无法在16.6ms完成一帧的绘制,将会导致连续的卡顿现象。别着急,请看看Google的决绝方案。
2.3 parallel processing and triple buffering
没错,就是加入第三个Buffer,CPU和GPU还有SurfaceFlinger各占一个Buffer,并行处理图形:

从上图可以看出,在第一个VSync到来时,尽管SurfaceFlinger占了一个Buffer,GPU又占了一个Buffer,CPU仍然可以在第三个Buffer中开始下一帧的计算,整个显示过程就开始时卡顿了一帧,之后都是流畅的。
当然系统并非一直开启三个Buffer,因为Buffer是需要消耗资源的,并且,我们会发现,上图中,GPU处理好的图形,需要跨越两个VSync信号,才能显示。这样的话,给用户的影响是一个延迟的现象。
为了解决该问题,我们需要再次从上层往下层了解Android绘制图形的各个细节,并进行优化。对于应用程序开发人员来说,重点还是上层的优化,对自己的应用程序的内存,UI,数据等进行优化。
总结:
- Android通过Buffer来保存图形信息,为了让图形显示的更加流程,在提供一一个Buffer用于显示的同时,开辟一个或者多个Buffer用于后台图形的合成。
- Android4.1之前,VSync信号并未传递给上层,导致生产与消费节奏不统一
- Android4.1之后,上层开始绘制时机都放到了VSync信号的到来时候
- 除了在上层引入VSync机制,Anroid在4.1还加入了三缓冲,用来减少卡顿的产生
- 每个Surface都有自己的绘制流程,需要先经过CPU处理,再经过GPU处理,之后经过SurfaceFlinger与其他Surface绘制好的图形和合成在一起,供屏幕显示
- VSync信号贯穿整个绘制流程,控制着整个Android图形系统的节奏
以上内容可能有不对的地方,希望各路大神指教!