Flutter Worker —— 闲鱼这样实现“逻辑跨平台”
闲鱼社区主要页面采用Native实现,部分使用Flutter和Weex承接。帖子、话题等固定数据结构的处理,点赞、评论等用户交互和状态同步,这些数据逻辑大部分是重复的,而且在多技术栈实现性价极低。由此我们想,能否在端上实现这样的一套工具,解放劳动力的同时,摆脱对服务端BFF层的依赖,保证研发效能。
抽象地看,实际上我们需要的正是一个逻辑跨平台工具。逻辑跨平台概念由来已久,也有一些很优秀的方案可以参考:
- C++语言在Objective-C/Java等Native语言都有成熟接口可以调用,这使得C++有天然的跨平台优势。同时不可否认的,C++入门门槛会比较高,导致后期维护成本大。
- KMM是JetBrains推出的用于跨平台移动开发SDK,提供了一个语言级别的逻辑跨平台解决方案,可以将直接代码编译为与目标平台完全相同的格式。
结合团队内现有的一些技术基建,最终我们使用Dart完成了这一设计,在不同平台保证数据和逻辑处理的一致性,节约人力资源的同时保证用户体验。取名Flutter Worker。
整体架构设计
在进行整体的设计之前,首先限定worker的业务场景:目标是提供一个多端可复用的逻辑处理中心,端上发起数据请求,所有的逻辑处理在FlutterWorker收口,执行完成返回回调给端上。设想中,在worker写Handler只需要关注逻辑处理,对于数据的传入和在端上的接收,开发者只需要指定类型,worker会自动把数据转化成该类型。
由此,在整体的架构设计中,我们主要考虑以下几个方面:
- FlutterWorker需要一个稳定的运行环境,由于涉及到数据处理等可能会比较耗时的操作,需要保证不影响UI界面的绘制。
- 处理后的数据要供给多端使用,数据结构必须对齐。
- 提供足够的切面,方便接入方拓展。
- 为了保证运行时稳定可靠,需要添加监控及时发现问题,并且在上线前时,对性能进行测试评估。
整体的架构图如下:

- 运行容器层:容器是worker运行的基础,在保证性能的前提下,要尽可能的利用闲鱼现有的技术基建。
- 状态管理层:worker在这里完成数据的存储和状态的同步。端上存储状态数据,通过订阅状态消息来接收数据的变动。考虑到状态管理层在目前没有业务的强需求,这部分仅停留在Demo阶段还未落地,后面不再进行阐述。
- 数据处理层:包含了worker所有的中间层数据处理部分,主要包括Model对象同步、数据转换和数据类型同步。基础数据类型在Dart语言中天然支持,在iOS端Androiddr端都有对应的类型,因此,worker工作主要在后两者。
- 监控层:worker在线上运行,需要有监控来保障,及时发现问题及时响应。
下面对各个模块进行详细的介绍。
运行容器层
FlutterWorker的运行环境强依赖FlutterEngine和Isolate,从这个角度来考虑,对以下三种方案做了梳理和对比。
值得一提的是,随着Flutter2.0推出,我们在更新日志中注意到有一项对多开Flutter Engine实例内存消耗的优化。据官方文档称,额外Flutter引擎的静态内存占用量降低了约 99%,使每个实例的占用量大约为180KB。结合源码来看,这里是新提供了FlutterEngineGroup类来创建Flutter Engine。
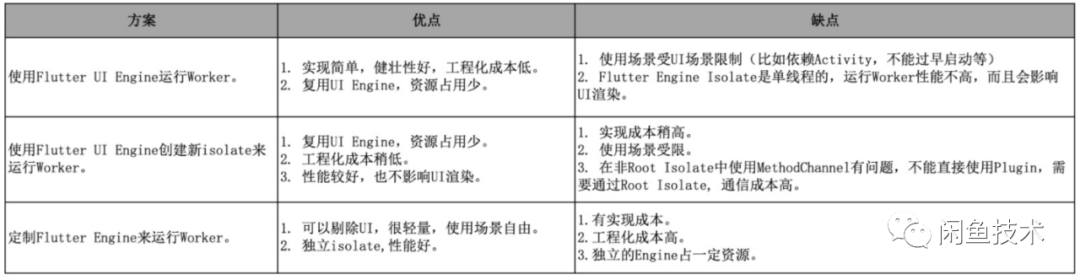

相较于原来的API,FlutterEngineGroup 生成的FlutterEngine具有常用共享资源(例如 GPU 上下文、字体度量和隔离线程的快照)的性能优势,从而加快首次渲染的速度、降低延迟并降低内存占用。
同时 EngineGroup 本身和其生成的 FlutterEngine不需要持续保活,只要有 1 个可用的FlutterEngine,就可以随时在各个 FlutterEngine 之间共享资源。EngineGroup销毁后,已生成的FlutterEngine也不受影响,只是无法继续在现有共享的基础上创建新引擎。
虽然现在FlutterEngineGroup还不是一个稳定API,但是这为FlutterWorker提供了另一种可能。综合考虑,目前实现选择了方案3来实现。
数据处理层
从用户调用开始,worker的数据流图如下图所示:

数据在三端的流通,是通过调用NatiaveWorker,执行到对应的WorkerHandler,处理完成后再以异步的方式回调到Native方法。中间主要涉及Model对象同步和数据转换过程,worker对这里分别实现了处理库。
Model对象同步
worker首先要实现的是,是OringinDataModel ==> TargetDataModel。TargetDataModel的定义在 iOS/Android/Flutter 三端的表现形式要保持一致,直接用代码生成是最好的选择。这里参考一些硬件协议,指定IDL格式来生成三端Model并导入工程。封装的dartGen库可以解析这些yaml节点,生成我们需要的胖Model。

方便开发者使用,dartGen打包成了cli工具。模仿GsonFormat插件,json数据在IDE中可以方便转成对应的dartGen可以解析的yaml协议。对于其他生成Model的需求,可以以很小的代价修改模板,定制化高。
数据转换
通过Flutter的MethodChannel向Native传输数据,需要经过一层messager编码,而且编码数据为基础类型。所以在BinaryMessager的基础上,封装了WorkerBinaryMessenger方便做定制化处理。
iOS端和Android端有成熟的model转换库(YYModel和FastJson)。在Dart这里,基于fish_serializable同样做了一些定制处理,在生成的Model里提供toJson和fromJson方法等,保证各种类型数据,包括Map和List等内包泛型类,能够很方便地进行转换。
监控方案设计
每个监控方案都有其业务场景的局限性,在目前阶段,主要考虑逻辑一致性。worker内单次的逻辑闭环类似tcp握手和挥手的过程,应用内的数据流转类似消息队列,其传递过程如图:

由此我们确定workerMonitor运行的流程图如下:

性能监控
在该模式下的主流监控方案,会根据时间切片来观察 发起方/接收方的队列数据情况,时间切片有两种方式,第一种是设置定时器,第二种是在每次有数据调用时处理。
另外上报的方式也分为实时上报和聚合上报。考虑到目前worker的使用场景有闲时和忙时的明显区分,并且端上的长驻的频繁的定时上报任务对ui绘制会有一定影响,最终采用每次数据调用时统计队列内数据,同时在每次调用后增加超时定时器,如果有下次调用则取消超时定时器。

指标
在线上监控指标建设方面,参考rabbitmq监控,先定义初期需要观测的指标。初期核心关注消息丢失的情况和消息时延长的情况。由此我们确定指标如下:

Exception监控
参考ui引擎对crash的监控,会在入口函数处统一接受异常信息以及异常堆栈,然后统一上报处理。这里在闲鱼公众号Flutter高可用相关文章中有详细介绍。
可行性验证
最后实现完成,调用代码及对应的Handler示例如下:
•iOS端:

•Android端:

•Handler:

为了测试我们的方案能否达到上线标准,在会玩首页场景下做暴力测试来验证。对比正常Native代码和worker处理数据,测试多次并发访问/有序访问条件下CPU、内存以及时延等表现。
通过多次对比试验,FlutterWorker方案在常见和高压的请求场景下短期内存和cpu水位增量少于30M,长期内存和cpu水位增量小于5M,并且时延低于原有方案的5%。
三端接入后,数据处理只需要投入一个人力就可供多端使用,大量减少了重复工作,提升了研发效能。
总结和展望
当前跨平台是移动开发的趋势之一,各个公司、团队各有建树,百家争鸣。究其根本目的都是想提升研发效率,降低维护成本。各个方案都各有自己的独特优势,应该理性分析团队和业务的现状,选择适合的方案。
Flutter Worker从逻辑跨平台的视角切入,取得了一些不错的效果。不过我们目前只完成了小部分的工作,仍有很多未完善的地方,在未来主要会从下面几个方面继续深入研究:
- MethodChannel优化。数据通道的通信强依赖MethodChannel,从目前测试结果来其性能表现可以cover目前的业务场景,但长远来看,通道会成为worker性能瓶颈。从dart_native库得到启发,以类型映射指针的方式来替代原生的通道是一条可行的路。
- 单元测试。逻辑处理函数有明确的输入和输出,写单测的效率很高。而且快速迭代的产品,很多是在原有的逻辑基础上添加新的逻辑,写单测的性价比较高。
- 前端容器支持。先行版本只支持了iOS、Android和Flutter,对于Weex和H5前端页面并没有很好的支持,未来期望能够提供优雅的方式接入前端容器。
这是闲鱼在Flutter探索道路上做的一点小尝试,欢迎大家保持关注。