一文搞懂Android JetPack组件原理之Lifecycle、LiveData、ViewModel与源码分析技巧
Lifecycle、LiveData和ViewModel作为AAC架构的核心,常常被用在Android业务架构中。在京东商城Android应用中,为了事件传递等个性化需求,比如ViewModel间通信、ViewModel访问Activity等等,以及为了架构的扩展性,我们封装了BaseLiveData和BaseViewModel等基础组件,也对Activity、Fragement和ViewHolder进行了封装,以JDLifecycleBaseActivity、LifecycleBaseFragment和LifecycleBaseViewHolder等组件强化了View层功能,构建出了各业务线统一规范架构的基石。
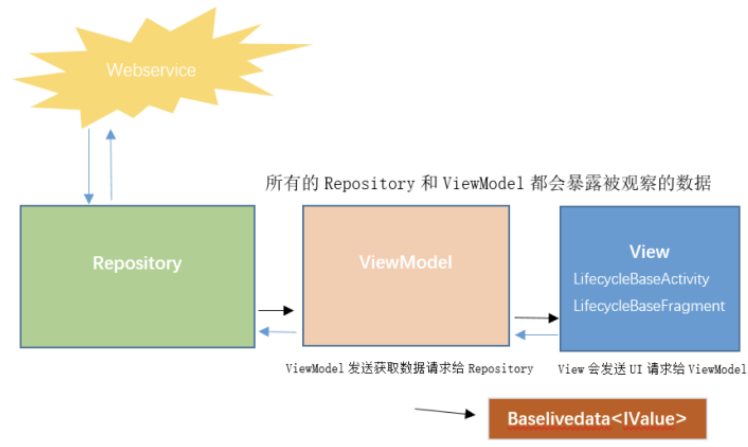
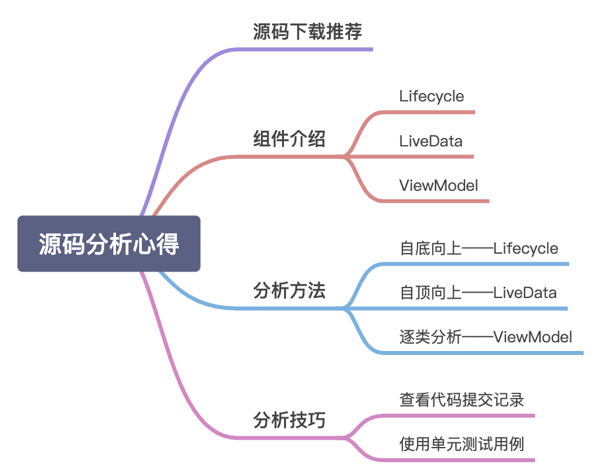
在开发过程中,我们有时还会对它们的原理细节有些疑惑,比如会有Lifecycle会不会对性能造成影响、LiveData为什么是粘性事件的、ViewModel的生命周期是什么样的等等问题,这些问题或多或少会对我们的日常开发和协作造成影响,所以对这些组件的源码分析就变得很有必要,而掌握一些分析方法更能提高效率。本文就以Lifecycle、LiveData和ViewModel三大组件的源码分析为例,探讨一下分析方法和技巧,整体目录如下图所示,希望能给大家带来收获。
源码下载
官方地址: https://android.googlesource.com/platform/frameworks/support/或Github: https://github.com/androidx/androidx,以上都列出了比较详细的下载步骤和编译方法,按步骤操作一般没多大问题,如果已经安装过repo工具,可以跳过第一步。
1. 安装repo
mkdir ~/bin
PATH=~/bin:$PATH
curl https://storage.googleapis.com/git-repo-downloads/repo > ~/bin/repo
chmod a+x ~/bin/repo2. 配置git中的姓名和邮箱,已配置可忽略
git config --global user.name "Your Name"
git config --global user.email "you@example.com"pet__string">"you@example.com"3. 创建一个文件夹存放要下载的源码
mkdir androidx-master-dev
cd androidx-master-dev4. 使用repo命令下载源码仓库
repo init -u https://android.googlesource.com/platform/manifest -b androidx-master-dev
repo sync -j8 -c5. 使用命令以Android Studio打开源码库
cd androidx-master-dev/frameworks/support/
./studiow第一次打开可能会自动下载一个最新的Android Studio,稍等一会儿,就可以看到熟悉的界面了。
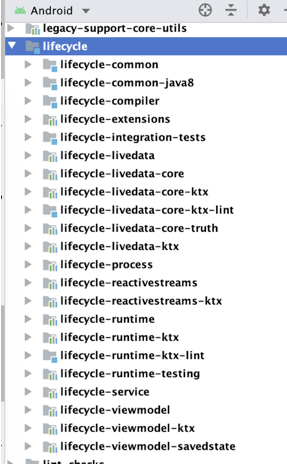
如图,Lifecycle、LiveData和ViewModel三大组件的代码都在lifecycle包下。
组件介绍
为了对分析工作有个感性认识,先过一下各个组件的作用和简单用法。
Lifecycle
Lifecycle可以方便我们处理Activity和Fragment的生命周期,可以将一些逻辑更加内聚和解耦,比如把资源的释放操作从Activity的回调代码中解耦出来,放到资源管理类中自动进行。该组件是后两个组件的基石,理解它的原理也有助于我们理解LiveData是如何保证不会造成内存泄漏的。
下面是一个简单的使用示例,在自定义LifecycleObserver的实现接口上,用注解的方式声明与生命周期相关联的方法。最后通过lifecycleOwner的getLifecycle()接口拿到Lifecycle管理类,并将定义LifecycleObserver的实现接口注册进去。LifecycleOwner通常是一个Activity或Fragment的实例。
MyObserver implements LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_RESUME)
public void connectListener() {
...
}
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
public void disconnectListener() {
...
}
}
lifecycleOwner.getLifecycle().addObserver(new MyObserver());LiveData
LiveData是一个数据持有组件,主要用来通知数据观察者数据发生了更新,它通过与LifecycleOwner组件绑定,实现可以只在页面活跃状态下发起通知,并在页面销毁时自动取消订阅,防止内存泄漏。
下面的简单示例中,直接创建了一个MutableLiveData对象,他持有String类型的数据,通过它的observe()方法,将LifecycleOwner和监听者传入,实现感知生命周期并观察数据的功能。
MutableLiveData<String> liveString = new MutableLiveData<>();
liveString.observe(mOwner, new Observer<String>() {
@Override
public void onChanged(@Nullable final String s) {
Log.d(TAG, "onChanged() called with: s = [" + s + "]");
}
});
liveString.setValue("LiveData使用案例");ViewModel
ViewModel是MVVM中的VM,被设计用来管理View依赖的数据,通常是持有LiveData和相关的处理逻辑。ViewModel管理的数据有一个特点,就是不会随着页面配置改变而销毁,但在页面销毁时则会正常跟着销毁。
下面的例子中,自定义了一个ViewModel,管理users这组数据,并且封装了加载users的处理逻辑。而View只需要监听users,在回调中根据users处理界面就好,这样就做到了界面和数据的分离。
public class MyViewModel extends ViewModel {
private MutableLiveData<List<User>> users;
public LiveData<List<User>> getUsers() {
if (users == null) {
users = new MutableLiveData<List<User>>();
loadUsers();
}
return users;
}
private void loadUsers() {
// Do an asynchronous operation to fetch users.
}
}组件关系
在实际的MVVM场景中,最常使用的是ViewModel和LiveData的API,比较通用的方式是ViewModel持有一个或多个LiveData,也就是需要我们开发者设计出这两个组件的聚合关系。而Lifecycle组件,则是在调用LiveData的addOberver()方法时用到的,这个方法需要传入一个LifecycleOwner对象,LifecycleOwner作为一个接口,是Lifecycle组件的重要组成部分。
通过分析组件的源码,可以从设计角度发现,Lifecycle组件的能力是LiveData和ViewModel实现的根本,LiveData的页面活跃状态下才发起通知、页面销毁时自动取消订阅,以及ViewModel销毁所管理的数据的特性,都是通过直接使用Lifecycle实现的,可以说Lifecycle是LiveData和ViewModel的重要组成部分。
源码分析方法
01自底向上
该方法是从使用细节出发,提出问题,再进入源码中探究答案,最后汇总出组件关系图,获得上层视角。在这里以自下向上的方法,分析一下LifeCycle的源码。
提出问题
首先,还是看这个使用示例:
MyObserver implements LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_RESUME)
public void connectListener() {
...
}
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
public void disconnectListener() {
...
}
}
lifecycleOwner.getLifecycle().addObserver(new MyObserver());针对该示例所实现的作用,可以从输入、处理和输出这三个软件过程角度提出问题:1、Activity/Fragment的生命周期如何转化为不同类型的Lifecycle.Event?2、Lifecycle.Event经过哪些处理?3、如何分发到特定的LifecycleObserver实现?
探究答案
Activity/Fragment的生命周期如何转化为不同类型的Lifecycle.Event
先来看看第一个问题怎么在源码中找到答案,不过在这以前,不妨先简单猜测一下,最直接的想法是:直接在生命周期回调方法中创建对应类型的Event。在接下来的分析中,便可以着重于是不是这么实现的,如果更复杂,那么还有哪些是需要被特别考虑到的。
ComponentActiivty相关代码
public class ComponentActivity extends Activity implements LifecycleOwner, Component {
private LifecycleRegistry mLifecycleRegistry = new LifecycleRegistry(this);
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
ReportFragment.injectIfNeededIn(this);
}
@CallSuper
protected void onSaveInstanceState(Bundle outState) {
Lifecycle lifecycle = this.getLifecycle();
if (lifecycle instanceof LifecycleRegistry) {
((LifecycleRegistry)lifecycle).setCurrentState(State.CREATED);
}
super.onSaveInstanceState(outState);
}
public Lifecycle getLifecycle() {
return this.mLifecycleRegistry;
}
}从ComponentActiivty这个类中,可以看到它实现了LifecycleOwner接口,该类的子类也就有了提供Lifecycle的能力,除了LifecycleOwner的getLifecycle接口的实现,另外比较重要的就是ReportFragment.injectIfNeededIn(this)这条语句,以及它持有了一个Lifecycle的主要实现类LifecycleRegistry的示例。
ReportFragment的主要实现
public class ReportFragment extends Fragment {
private static final String REPORT_FRAGMENT_TAG = "android.arch.lifecycle"
+ ".LifecycleDispatcher.report_fragment_tag";
public static void injectIfNeededIn(Activity activity) {
if (Build.VERSION.SDK_INT >= 29) {
// On API 29+, we can register for the correct Lifecycle callbacks directly
activity.registerActivityLifecycleCallbacks(
new LifecycleCallbacks());
}
// Prior to API 29 and to maintain compatibility with older versions of
// ProcessLifecycleOwner (which may not be updated when lifecycle-runtime is updated and
// need to support activities that don't extend from FragmentActivity from support lib),
// use a framework fragment to get the correct timing of Lifecycle events
android.app.FragmentManager manager = activity.getFragmentManager();
if (manager.findFragmentByTag(REPORT_FRAGMENT_TAG) == null) {
manager.beginTransaction().add(new ReportFragment(), REPORT_FRAGMENT_TAG).commit();
// Hopefully, we are the first to make a transaction.
manager.executePendingTransactions();
}
}
//...
@Override
public void onStart() {
super.onStart();
dispatchStart(mProcessListener);
dispatch(Lifecycle.Event.ON_START);
}
private void dispatch(@NonNull Lifecycle.Event event) {
if (Build.VERSION.SDK_INT < 29) {
// Only dispatch events from ReportFragment on API levels prior
// to API 29. On API 29+, this is handled by the ActivityLifecycleCallbacks
// added in ReportFragment.injectIfNeededIn
dispatch(getActivity(), event);
}
}
static void dispatch(@NonNull Activity activity, @NonNull Lifecycle.Event event) {
if (activity instanceof LifecycleRegistryOwner) {
((LifecycleRegistryOwner) activity).getLifecycle().handleLifecycleEvent(event);
return;
}
if (activity instanceof LifecycleOwner) {
Lifecycle lifecycle = ((LifecycleOwner) activity).getLifecycle();
if (lifecycle instanceof LifecycleRegistry) {
((LifecycleRegistry) lifecycle).handleLifecycleEvent(event);
}
}
}
//...
}静态方法injectIfNeededIn的主要作用就是为Activity提供Lifecycle能力,这里分成了两种情况,在Android 10及以上,Activity的源码修改成自己可以注册进LifecycleCallbacks监听器。而为了兼容旧版本,则需要Fragment的生命周期回调中进行分发,这也就是与最初推测相比特殊的地方,可以更加留意。不过这两种情况都是根据生命周期创建了Event枚举型,并最终都经过静态方法dispatch,调用了Lifecyce的handleLifecycleEvent方法。
Lifecycle.Event经过哪些处理
LifecycRegistry
public class LifecycleRegistry extends Lifecycle {
/**
* Custom list that keeps observers and can handle removals / additions during traversal.
*
* Invariant: at any moment of time for observer1 & observer2:
* if addition_order(observer1) < addition_order(observer2), then
* state(observer1) >= state(observer2),
*/
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap = new FastSafeIterableMap<>();
private State mState;
private final WeakReference<LifecycleOwner> mLifecycleOwner;
public LifecycleRegistry(@NonNull LifecycleOwner provider) {
mLifecycleOwner = new WeakReference<>(provider);
mState = INITIALIZED;
}
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
State next = getStateAfter(event);
moveToState(next);
}
private void moveToState(State next) {
if (mState == next) {
return;
}
mState = next;
......
sync();
......
}
...
}跟着源码可以定位到Lifecycle的实现类LifecycRegistry中,它主要是封装了对Lifecycle.Event的操作,包括了Lifecycle.Event与Lifecycle.State的同步,以及Lifecycle.State变化后通知观察者。
先来看handleLifecycleEnvent的实现,通过传进来的event获取一个state枚举值,具体的实现代码如下:
static State getStateAfter(Event event) {
switch(event) {
case ON_CREATE:
case ON_STOP:
return State.CREATED;
case ON_START:
case ON_PAUSE:
return State.STARTED;
case ON_RESUME:
return State.RESUMED;
case ON_DESTROY:
return State.DESTROYED;
case ON_ANY:
default:
throw new IllegalArgumentException("Unexpected event value " + event);
}
}官网中有一张图用来解释Event和State的对应关系
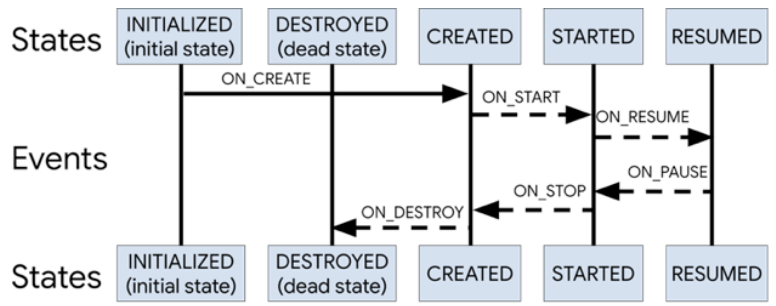
getStateAfter()方法既是获取Event事件之后的状态,可以从图中的箭头方向可知具体的状态值,比如ON_START和ON_PAUSE的箭头都指向了STARTED状态,也就是这俩个事件后Lifecycle处于STARTED状态。
回到handleLifecycleEvent()方法,获取新状态后,就调用了moveToState()方法,该方法主要是判断新状态与当前状态相比是否发生改变,如果已改变,则调用sync()同步方法继续处理。
在进一步跟踪方法调用前,不妨先看看LifecycleRegistry有哪些属性,除了上面提到的mState来表示当前Lifecycle的状态外,还有一个比较特殊和重要的属性是mObserverMap。
/**
* Custom list that keeps observers and can handle removals / additions during traversal.
*
* Invariant: at any moment of time for observer1 & observer2:
* if addition_order(observer1) < addition_order(observer2), then
* state(observer1) >= state(observer2),
*/
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap = new FastSafeIterableMap<>();该属性可看作是一个自定义的Map,是一个可遍历的集合,也就是说其中的元素是有序的,封装了监听者LifecycleObserver和监听者的封装ObserverWithState之间的映射关系,根据注释可以知道,在遍历操作其中的监听者时,会保证其中监听者的状态是从大到小排序的。
监听者的封装ObserverWithState则是维护了每一个监听者和其状态,该状态主要是为了给调用事件分发前的判断,另外,在分发Event事件后会同步更新自己的状态。
static class ObserverWithState {
State mState;
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
mState = initialState;
}
void dispatchEvent(LifecycleOwner owner, Event event) {
State newState = getStateAfter(event);
mState = min(mState, newState);
mLifecycleObserver.onStateChanged(owner, event);
mState = newState;
}
}接下来继续跟踪方法调用,来看看sync()做了哪些处理。
private void sync() {
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
throw new IllegalStateException("LifecycleOwner of this LifecycleRegistry is already"
+ "garbage collected. It is too late to change lifecycle state.");
}
while (!isSynced()) {
mNewEventOccurred = false;
// no need to check eldest for nullability, because isSynced does it for us.
if (mState.compareTo(mObserverMap.eldest().getValue().mState) < 0) {
backwardPass(lifecycleOwner);
}
Entry<LifecycleObserver, ObserverWithState> newest = mObserverMap.newest();
if (!mNewEventOccurred && newest != null
&& mState.compareTo(newest.getValue().mState) > 0) {
forwardPass(lifecycleOwner);
}
}
mNewEventOccurred = false;
}该方法通过比较当前状态和mObserverMap元素的枚举值来确定是否分发事件,由于mObserverMap里元素是按状态的大到小排序的,所以这里只需要拿第一位和最后一位元素的状态与当前状态比较,就可以判断是否需要分发事件,以及是分发降级事件,还是分发升级事件。再具体一点说,如果mObserverMap里最大状态比当前状态大,那就需要调用backwardPass(),遍历mObserverMap,同步其中每一个observer状态的同时,分发降级事件,反之,如果mObserverMap里最小状态比当前状态小,就调用forwardPass()分发升级事件。
private void backwardPass(LifecycleOwner lifecycleOwner) {
Iterator<Entry<LifecycleObserver, ObserverWithState>> descendingIterator =
mObserverMap.descendingIterator();
while (descendingIterator.hasNext() && !mNewEventOccurred) {
Entry<LifecycleObserver, ObserverWithState> entry = descendingIterator.next();
ObserverWithState observer = entry.getValue();
while ((observer.mState.compareTo(mState) > 0 && !mNewEventOccurred
&& mObserverMap.contains(entry.getKey()))) {
Event event = downEvent(observer.mState);
pushParentState(getStateAfter(event));
observer.dispatchEvent(lifecycleOwner, event);
popParentState();
}
}
}
private void forwardPass(LifecycleOwner lifecycleOwner) {
Iterator<Entry<LifecycleObserver, ObserverWithState>> ascendingIterator =
mObserverMap.iteratorWithAdditions();
while (ascendingIterator.hasNext() && !mNewEventOccurred) {
Entry<LifecycleObserver, ObserverWithState> entry = ascendingIterator.next();
ObserverWithState observer = entry.getValue();
while ((observer.mState.compareTo(mState) < 0 && !mNewEventOccurred
&& mObserverMap.contains(entry.getKey()))) {
pushParentState(observer.mState);
observer.dispatchEvent(lifecycleOwner, upEvent(observer.mState));
popParentState();
}
}
}backwardPass()和forwardPass()类似,分别是以降序和升序的方式遍历mObserverMap中的observer,再以内部循环通过downEvent()和upEvent()获取下一步的Event事件,并通过observer.dispatchEvent()分发事件和同步状态。直到mObserverMap中的每一个observer的状态都与当前状态一致为止。
private static Event downEvent(State state) {
switch (state) {
case INITIALIZED:
throw new IllegalArgumentException();
case CREATED:
return ON_DESTROY;
case STARTED:
return ON_STOP;
case RESUMED:
return ON_PAUSE;
case DESTROYED:
throw new IllegalArgumentException();
}
throw new IllegalArgumentException("Unexpected state value " + state);
}
private static Event upEvent(State state) {
switch (state) {
case INITIALIZED:
case DESTROYED:
return ON_CREATE;
case CREATED:
return ON_START;
case STARTED:
return ON_RESUME;
case RESUMED:
throw new IllegalArgumentException();
}
throw new IllegalArgumentException("Unexpected state value " + state);
}downEvent()和upEvent()的实现同样可以从官网给的Event与State的关系图中找到对应关系。下面再放一下这张图。
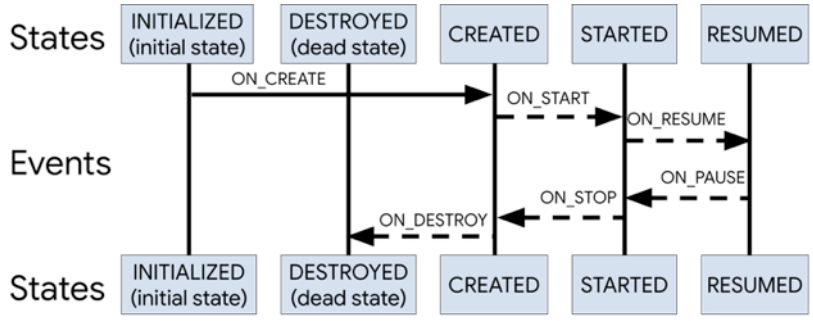
downEvent()降级事件就是状态向后箭头对应的事件,而upEvent()升级事件则是状态向前箭头对应的事件。比如说CREATED的升级事件是ON_START,通过ON_START,CREATED升级为STARTED。CREATED的降级事件是ON_DESTROY,通过ON_DESTROY,CREATED降级为DESTROY。
方法调用流转到这里,已经分析完Event从创建到分发的处理过程,接下来就来解决刚开始提出的第三个问题。
如何分发到特定的LifecycleObserver实现
通过ObserverWithState,可以发现dispatchEvent()方法是直接调用mLifecycleObserver接口的onStateChanged()进行的事件分发,那么mLifecycleObserver的具体实现是怎样的呢?通过 mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer)可以知道静态方法Lifecycling.lifecycleEventObserver()对传入的监听者进行了处理,接下来就来看看该方法是怎么实现的。
static LifecycleEventObserver lifecycleEventObserver(Object object) {
boolean isLifecycleEventObserver = object instanceof LifecycleEventObserver;
boolean isFullLifecycleObserver = object instanceof FullLifecycleObserver;
if (isLifecycleEventObserver && isFullLifecycleObserver) {
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object,
(LifecycleEventObserver) object);
}
if (isFullLifecycleObserver) {
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object, null);
}
if (isLifecycleEventObserver) {
return (LifecycleEventObserver) object;
}
final Class<?> klass = object.getClass();
int type = getObserverConstructorType(klass);
if (type == GENERATED_CALLBACK) {
List<Constructor<? extends GeneratedAdapter>> constructors =
sClassToAdapters.get(klass);
if (constructors.size() == 1) {
GeneratedAdapter generatedAdapter = createGeneratedAdapter(
constructors.get(0), object);
return new SingleGeneratedAdapterObserver(generatedAdapter);
}
GeneratedAdapter[] adapters = new GeneratedAdapter[constructors.size()];
for (int i = 0; i < constructors.size(); i++) {
adapters[i] = createGeneratedAdapter(constructors.get(i), object);
}
return new CompositeGeneratedAdaptersObserver(adapters);
}
return new ReflectiveGenericLifecycleObserver(object);
}该方法主要将传入的监听者进行封装,方便生命周期事件的转发,这个封装分成了三种方式,每一种可看作是后面的优化,第一种性能最高,传入的监听者直接是接口的实例,但由于生命周期回调方法比较多,接口的实例默认是实现了所有方法,而大部分情况并不需要监听所有生命周期,所以这一部分在java8接口默认方法的支持下比较好用。第二种是判断传入的监听者是不是已用注解解析器处理,生成了对应的封装类,如果项目中配置了注解解析,那么在编译过程中就会生成相应的类型,相对应于运行时反射解析方法的方式,编译时通过注解生成类型在代码执行时性能更高。第三种就是运行时反射解析的处理了,限于篇幅,这里就只追踪一下第三种方式的处理过程。
直接定位到ReflectiveGenericLifecycleObserver类。
class ReflectiveGenericLifecycleObserver implements LifecycleEventObserver {
private final Object mWrapped;
private final CallbackInfo mInfo;
ReflectiveGenericLifecycleObserver(Object wrapped) {
mWrapped = wrapped;
mInfo = ClassesInfoCache.sInstance.getInfo(mWrapped.getClass());
}
@Override
public void onStateChanged(@NonNull LifecycleOwner source, @NonNull Event event) {
mInfo.invokeCallbacks(source, event, mWrapped);
}
}该类的实现很简单,在创建实例时,使用getInfo()方法,通过传入监听者的class,构造出CallbackInfo实例。在接受到生命周期回调后,方法流转到CallbackInfo实例的invokeCallbacks()方法上。
CallbackInfo getInfo(Class<?> klass) {
CallbackInfo existing = mCallbackMap.get(klass);
if (existing != null) {
return existing;
}
existing = createInfo(klass, null);
return existing;
}getInfo()查看是否已有缓存,如果没有,就调用createInfo()方法解析class对象。
private CallbackInfo createInfo(Class<?> klass, @Nullable Method[] declaredMethods) {
Map<MethodReference, Lifecycle.Event> handlerToEvent = new HashMap<>();
...
Method[] methods = declaredMethods != null ? declaredMethods : getDeclaredMethods(klass);
for (Method method : methods) {
OnLifecycleEvent annotation = method.getAnnotation(OnLifecycleEvent.class);
if (annotation == null) {
continue;
}
hasLifecycleMethods = true;
Class<?>[] params = method.getParameterTypes();
int callType = CALL_TYPE_NO_ARG;
if (params.length > 0) {
callType = CALL_TYPE_PROVIDER;
if (!params[0].isAssignableFrom(LifecycleOwner.class)) {
throw new IllegalArgumentException(
"invalid parameter type. Must be one and instanceof LifecycleOwner");
}
}
Lifecycle.Event event = annotation.value();
if (params.length > 1) {
callType = CALL_TYPE_PROVIDER_WITH_EVENT;
if (!params[1].isAssignableFrom(Lifecycle.Event.class)) {
throw new IllegalArgumentException(
"invalid parameter type. second arg must be an event");
}
if (event != Lifecycle.Event.ON_ANY) {
throw new IllegalArgumentException(
"Second arg is supported only for ON_ANY value");
}
}
if (params.length > 2) {
throw new IllegalArgumentException("cannot have more than 2 params");
}
MethodReference methodReference = new MethodReference(callType, method);
verifyAndPutHandler(handlerToEvent, methodReference, event, klass);
}
CallbackInfo info = new CallbackInfo(handlerToEvent);
mCallbackMap.put(klass, info);
mHasLifecycleMethods.put(klass, hasLifecycleMethods);
return info;
}createInfo()方法主要是对类中的方法的遍历处理,这里只接受三种类型的方法,使用callType区分,第一种CALL_TYPE_NO_ARG是没有参数的方法,第二种CALL_TYPE_PROVIDER是一个参数的方法,参数类型为LifecycleOwner本身,第三种CALL_TYPE_PROVIDER_WITH_EVENT是二个参数的方法,第一个参数类型同CALL_TYPE_PROVIDER一样,第二个参数则是ON_ANY枚举值的Event。
每次遍历会将方法用MethodReference封装起来,并使用hanlderToEvent建立MethodReference与event的映射关系,注意这时候一个方法只能有一种Event事件类型相对应,最后以hanlderToEvent这个map创建CallbackInfo对象。
static class CallbackInfo {
final Map<Lifecycle.Event, List<MethodReference>> mEventToHandlers;
final Map<MethodReference, Lifecycle.Event> mHandlerToEvent;
CallbackInfo(Map<MethodReference, Lifecycle.Event> handlerToEvent) {
mHandlerToEvent = handlerToEvent;
mEventToHandlers = new HashMap<>();
for (Map.Entry<MethodReference, Lifecycle.Event> entry : handlerToEvent.entrySet()) {
Lifecycle.Event event = entry.getValue();
List<MethodReference> methodReferences = mEventToHandlers.get(event);
if (methodReferences == null) {
methodReferences = new ArrayList<>();
mEventToHandlers.put(event, methodReferences);
}
methodReferences.add(entry.getKey());
}
}
@SuppressWarnings("ConstantConditions")
void invokeCallbacks(LifecycleOwner source, Lifecycle.Event event, Object target) {
invokeMethodsForEvent(mEventToHandlers.get(event), source, event, target);
invokeMethodsForEvent(mEventToHandlers.get(Lifecycle.Event.ON_ANY), source, event,
target);
}
private static void invokeMethodsForEvent(List<MethodReference> handlers,
LifecycleOwner source, Lifecycle.Event event, Object mWrapped) {
if (handlers != null) {
for (int i = handlers.size() - 1; i >= 0; i--) {
handlers.get(i).invokeCallback(source, event, mWrapped);
}
}
}
}CallbakcInfo在创建时,会解析hanlderToEvent,把一个MethodReference对应一个event的关系,转化为一个event对应多个MethodReference,并存入到mEventToHandlers中。这样在被调用invokeCallbacks()方法时,只需要从mEventToHandlers中取出对应的MethodReference,就可以回调监听者了。
static final class MethodReference {
final int mCallType;
final Method mMethod;
MethodReference(int callType, Method method) {
mCallType = callType;
mMethod = method;
mMethod.setAccessible(true);
}
void invokeCallback(LifecycleOwner source, Lifecycle.Event event, Object target) {
//noinspection TryWithIdenticalCatches
try {
switch (mCallType) {
case CALL_TYPE_NO_ARG:
mMethod.invoke(target);
break;
case CALL_TYPE_PROVIDER:
mMethod.invoke(target, source);
break;
case CALL_TYPE_PROVIDER_WITH_EVENT:
mMethod.invoke(target, source, event);
break;
}
} catch (InvocationTargetException e) {
throw new RuntimeException("Failed to call observer method", e.getCause());
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
...
}invokeCallback()就是根据callType对mMethod进行反射调用,最终执行到Lifecycling.lifecycleEventObserver()传入的监听器的方法实现中。
到此,Lifecycle的基本流程已经分析完了。接下来,可以使用类图对Lifecycle的处理流程做下总结。
类关系图
该图使用simpleUML工具生成
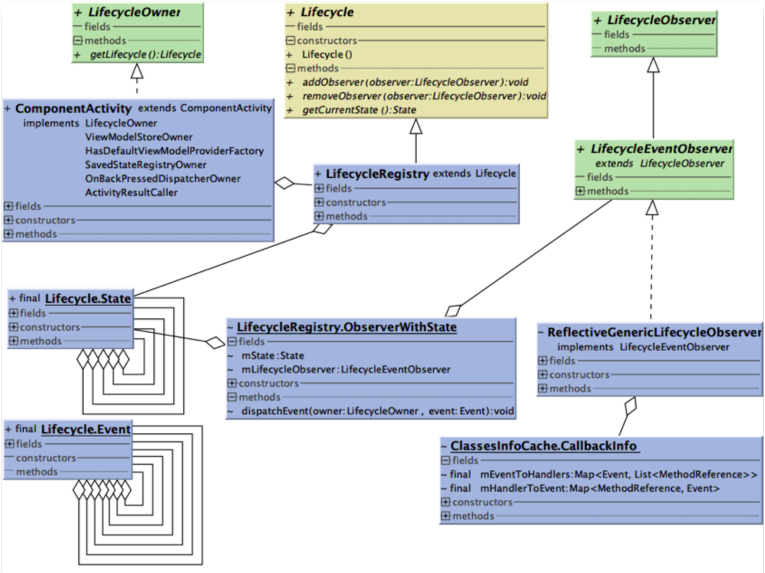
用最初的使用代码来解释一下这个类图。
lifecycleOwner.getLifecycle().addObserver(new MyObserver());首先,通过LifecycleOwner拿到Lifecycle示例,LifecycleOwner是提供获取Lifecycle实例的接口,一般ComponentActvitiy和Fragment会实现这个接口,这个新旧代码有些差别,使用时需要区分。
然后,Lifecycle实例一般具体类型是LifecycleRegistry,它里面使用State管理当前的生命周期状态,同时每个监听者LifecycleObserver也都有一个State,表示监听者当前的状态,生命周期事件Event发生后,会在LifecycleRegistry内与State发生互相转化,再使用这个转化后最新的State,与所有监听者的State比较,到达完整无误地通知监听者生命周期事件的目的。
最后,监听者注册进Lifecycle时,一般情况下会使用ReflectiveGenericLifecycleObserver封装,ReflectiveGenericLifecycleObserver本身也是LifecycleObserver接口的实现,它还封装了从传入监听者类中解析的CallbackInfo,在被通知生命周期事件时,会使用CallbackInfo反射调用到用户声明的接口方法实现上。
自底向上方法总结
自底向上的方式分析源码主要在于分析前问题的提出,上面应用了软件过程中的输入、处理和输出这三个角度提出问题,算是比较通用的一种方式。问题提出后,便可以以解决问题为目的分析源码,不至于在茫茫源码中迷失了方向。解决完问题,紧接着把源码的主要流程梳理一遍,做出总结,即可以加深对原理的理解。
02自顶向下
自顶向下分析源码与自底向上在思路上正好相反,需要先绘制出组件的类关系图,然后抽出主要方法,进一步解析方法,从而掌握实现细节,它适合于在对源码组件有一个整体上的了解前提下进行,可以深刻掌握组件的原理特性。接下来就使用该方法总结出LiveData的特性。
首先还是以一个示例开始:
MutableLiveData<String> liveString = new MutableLiveData<>();
liveString.observe(mOwner, new Observer<String>() {
@Override
public void onChanged(@Nullable final String s) {
Log.d(TAG, "onChanged() called with: s = [" + s + "]");
}
});
liveString.setValue("LiveData使用案例"); 该例子包含了使用LIveData的基本三部分:定义、注册监听者、更新数据。可以同样以软件过程的输入、处理和输出三个角度为切入点进行分析。处了定义外,监听者相关的操作可以看作是输出,比如注册、回调、注销。更新数据则可以看作是输入,而处理则是在LiveData的内部完成。
类关系图
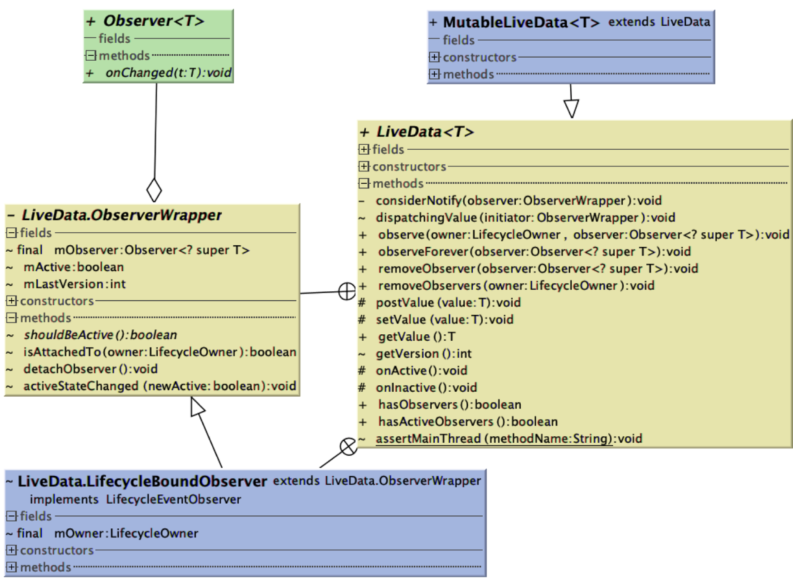
LiveData的类关系图并不复杂,它只有5个类,除了示例中已经出现的有Observer和MutableLiveData,而主要类LiveData则包含和处理的主要逻辑,LiveData的内部类ObserverWrapper和LifecycleBoundObserver则提供了封装Observer和Lifecycle生命周期管理的能力。这里也可以看出LiveData依赖Livecycle的关系。
可以从类图中抽出需要分析的方法,回到输入、处理和输出的角度,对应的就是数据更新、数据流转和监听者处理三类方法。
输入-数据更新:postValue()、setValue()、onStateChanged()
处理-数据流转:activeStateChanged()、dispatchingValue()、considerNotify()
输出-监听者处理:observe()、removeObserver()、onChanged()
接下来,可以使用在源码方法间快速跳转的方式,手动定位并列出相应处理链。
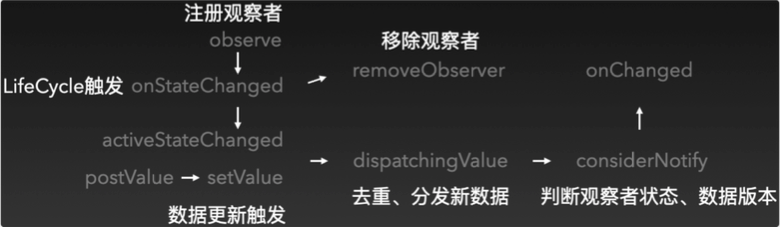
从该图中可以看出触发数据通知的两个处理链:
1. 注册监听者后,可以接收到Lifecycle事件,这时候可能会移除监听者,也可能触发了数据通知
2. 手动postValue或setValue触发数据通知
接下来,便以这两个任务链的顺序,对每个方法进行分析。
observer()注册监听者
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer<? super T> observer) {
assertMainThread("observe");
if (owner.getLifecycle().getCurrentState() == DESTROYED) {
// ignore
return;
}
LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
owner.getLifecycle().addObserver(wrapper);
}该方法就是把Lifecycle持有对象LifecycleOwner和一个监听者observer传进来,实现这个监听者在这个生命周期作用域下对LiveData的数据进行监听。这里主要的处理是对observer使用Lifecycle的监听者LifecycleBoundObserver进行了封装,并存入管理所有监听者的mObservers中。这里除了过滤避免重复外,还对监听者对应的LifecycleOwner进行了判断,防止一个监听者处于多个Lifecycle作用域进而导致混乱的情况发生。
LifecycleBoundObserver的onStateChanged()
class LifecycleBoundObserver extends ObserverWrapper implements LifecycleEventObserver {
@NonNull
final LifecycleOwner mOwner;
LifecycleBoundObserver(@NonNull LifecycleOwner owner, Observer<? super T> observer) {
super(observer);
mOwner = owner;
}
@Override
boolean shouldBeActive() {
return mOwner.getLifecycle()
.getCurrentState().isAtLeast(STARTED);
}
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
if (mOwner.getLifecycle().getCurrentState() == DESTROYED) {
removeObserver(mObserver);
return;
}
activeStateChanged(shouldBeActive());
}
@Override
boolean isAttachedTo(LifecycleOwner owner) {
return mOwner == owner;
}
@Override
void detachObserver() {
mOwner.getLifecycle().removeObserver(this);
}
}onStateChanged()的逻辑是LifecycleBoundObserver中对接口LifecycleEventObserver的实现,通过对Lifecycle组件的了解,可以知道在LifecycleOwner的生命周期发生改变时,onStateChanged()方法就会被调用到。这里判断如果LifecycleOwner销毁了,那么就移除这个监听者,达到防止内存泄漏的目的,其它情况则会以shouldBeActivie()为值调用activeStateChanged()方法。shouldBeActivie()判断LifecycleOwner的状态是否处于STARTED之后,也就是是否显示在屏幕中,这里表明了LiveData的另一个特性,默认情况下,显示在屏幕中的页面中的监听者才会收到数据更新的通知。
ObserverWrapper的activeStateChanged()
private abstract class ObserverWrapper {
final Observer<? super T> mObserver;
boolean mActive;
int mLastVersion = START_VERSION;
ObserverWrapper(Observer<? super T> observer) {
mObserver = observer;
}
abstract boolean shouldBeActive();
boolean isAttachedTo(LifecycleOwner owner) {
return false;
}
void detachObserver() {
}
void activeStateChanged(boolean newActive) {
if (newActive == mActive) {
return;
}
// immediately set active state, so we'd never dispatch anything to inactive
// owner
mActive = newActive;
boolean wasInactive = LiveData.this.mActiveCount == 0;
LiveData.this.mActiveCount += mActive ? 1 : -1;
if (wasInactive && mActive) {
onActive();
}
if (LiveData.this.mActiveCount == 0 && !mActive) {
onInactive();
}
if (mActive) {
dispatchingValue(this);
}
}
}activeStateChanged()方法是在LifecycleBoundObserver的父类ObserverWrapper中实现的,先看ObserverWrapper的属性,ObserverWrapper不仅封装了监听者,还用mActive管理是否为活跃状态,以及用mLastVersion管理监听者当前的数据版本。回到activeStateChanged()方法,这里的处理主要分三点,首先,用活跃状态是否发生变化做了一个闭路逻辑,防止重复处理,比如onStart()处理后又接收到onResume()。其次,更新当前状态,并判断如果这是第一个监听者活跃,就调用onActive()方法,如果是最后一个监听者非活跃,就调用onInactive()方法。最后,如果是新的活跃状态,则以当前ObserverWrapper对象为参数值调用dispatchingValue()方法分发事件。
setValue()
@MainThread
protected void setValue(T value) {
assertMainThread("setValue");
mVersion++;
mData = value;
dispatchingValue(null);
}setValue()是LiveData的一个成员方法,用于在主线程中手动更新LiveData中的值,这里先将数据版本mVersion自增后,更新mData的值,并以null为参数值调用dispatchingValue()方法。
postValue()
protected void postValue(T value) {
boolean postTask;
synchronized (mDataLock) {
postTask = mPendingData == NOT_SET;
mPendingData = value;
}
if (!postTask) {
return;
}
ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);
}
private final Runnable mPostValueRunnable = new Runnable() {
@SuppressWarnings("unchecked")
@Override
public void run() {
Object newValue;
synchronized (mDataLock) {
newValue = mPendingData;
mPendingData = NOT_SET;
}
setValue((T) newValue);
}
};postValue()也是用来手动更新LiveData中的值的,不过和setValue()有区别的是,它可以在非主线程中调用。它的处理就是在保证线程安全的前提下,通知主线程调用setValue()方法更新数据。
具体细节是,定义一个volatile修饰的成员变量mPandingData,用作线程间共享数据,这个变量的默认值为NOT_SET。通过对共享数据mPandingData的读写访问进行加锁的方式实现线程安全,同时,主线程读取mPandingData的值后,也就被认为是消费掉了共享数据,这时会把mPandingData设置会默认值NOT_SET,而其他线程在拿到锁后写入mPandingData,也就是生产共享数据时,只有之前主线程已消费掉或还未生产过共享数据,才会向主线程发送处理消息。
这个逻辑实现了另外一个特性,当主线程还没来得及处理消息,这时多个线程同时排队拿锁更新数据,主线程最终只会使用最后最新的数据去处理,调用setValue()通知监听者。
dispatchingValue()
无论是生命周期回调的activeStateChanged()还是手动发起数据更新setValue(),最终都通过dispatchingValue()完成了数据更新的分发。
void dispatchingValue(@Nullable ObserverWrapper initiator) {
if (mDispatchingValue) {
mDispatchInvalidated = true;
return;
}
mDispatchingValue = true;
do {
mDispatchInvalidated = false;
if (initiator != null) {
considerNotify(initiator);
initiator = null;
} else {
for (Iterator<Map.Entry<Observer<? super T>, ObserverWrapper>> iterator =
mObservers.iteratorWithAdditions(); iterator.hasNext(); ) {
considerNotify(iterator.next().getValue());
if (mDispatchInvalidated) {
break;
}
}
}
} while (mDispatchInvalidated);
mDispatchingValue = false;
}dispatchingValue()如果传入的参数不为null,那么就针对该对象单独分发,对应的就是生命周期回调的调用。而如果传入了null,那就遍历mObservers,对每一个监听者完成分发。每次分发是调用considerNotify()完成。
dispatchingValue()的处理中首先使用了两个成员变量mDispatchingValue和mDispatchInvalidated做了一个短路逻辑,这俩成员变量分别表示是否处于分发中和分发的数据是否过期。进入分发过程时,会将mDispatchingValue置为true,mDispatchInvalidated置为false,这时表示处于正常的分发状态。如果在正常分发状态时,再有新的分发请求,那么就会将mDispatchInvalidated值为true,正常的分发状态便会中断,重新开始分发。这就实现了一个特性,只对监听者通知最新的数据。
可以使用下面的单元测试加深对该特性的理解。
@Test
public void testSetValueDuringSetValue() {
mOwner.handleLifecycleEvent(ON_START);
final Observer observer1 = spy(new Observer<String>() {
@Override
public void onChanged(String o) {
assertThat(mInObserver, is(false));
mInObserver = true;
if (o.equals(("bla"))) {
mLiveData.setValue("gt");
}
mInObserver = false;
}
});
final Observer observer2 = spy(new FailReentranceObserver());
mLiveData.observe(mOwner, observer1);
mLiveData.observe(mOwner, observer2);
mLiveData.setValue("bla");
verify(observer1, Mockito.atMost(2))
.onChanged("gt");
verify(observer2, Mockito.atMost(2))
.onChanged("gt");
}这个单元测试在源码库中可以找到,有兴趣的同学可以debug一下看看处理流程,后面会介绍一下这个技巧,这里先简单描述一下代码执行过程。
在这个单元测试中,对于mLiveData有两个监听者observer1和observer2,正常情况下,当mLiveData.setValue("bla")时,dispatchingValue()对监听者进行遍历,两个监听者应该依次收到数据“bla”的通知,但是observer1在收到“bla”后,又执行mLiveData.setValue("gt")发起了新的数据更新,这个第二次dispatchingValue()便会短路,且会中断并重启第一次的遍历,于是observer1会再次收到“gt”,然后才是observer2,它只会收到“gt”。
这个流程便是保证了数据更新只通知最新的,在实际开发中如果遇到setValue()的过程中再次setValue()的情况,就需要特别注意一下这条特性。
considerNotify()
private void considerNotify(ObserverWrapper observer) {
if (!observer.mActive) {
return;
}
// Check latest state b4 dispatch. Maybe it changed state but we didn't get the event yet.
//
// we still first check observer.active to keep it as the entrance for events. So even if
// the observer moved to an active state, if we've not received that event, we better not
// notify for a more predictable notification order.
if (!observer.shouldBeActive()) {
observer.activeStateChanged(false);
return;
}
if (observer.mLastVersion >= mVersion) {
return;
}
observer.mLastVersion = mVersion;
observer.mObserver.onChanged((T) mData);
}considerNotify()才是最终发起数据更新通知的方法,这里首先检查了监听者及其所处生命周期的活跃状态,并比较了监听者的数据版本和当前数据版本,保证了监听者所在页面处于前台时并且数据版本需要更新时才发起通知。发起通知前会更新监听者的数据版本到最新,确保数据一致。
LiveData特性
分析完这些主要方法后,便可以对LiveData的特性做一个总结了,以便在实际使用过程中更加得心应手。
1. 一个监听者只能处于一个生命周期作用域中
2. 监听者通过Lifecycle的特性实现页面销毁后自动注销,防止内存泄漏
3. 监听者只会在所处的页面在前台的情况下收到数据更新的通知
4. 由于Lifecycle的特性,监听者如果在所处页面在前台的情况下,注册进LiveData,会立即调用到considerNotify(),这时候如果LiveData的数据版本变化过,便会立即对该监听者发送通知,这也就是所谓的粘性事件。
5. postValue()经过线程安全处理,最终通过setValue()发起数据更新通知。N次postValue()并不能保证同样N次setValue(),post中防止了重复向主线程发消息,主线程中只会拿当前最新的值调用setValue()。
6. N次setValue()同样不能保证活跃的监听者被通知到N次,LiveData保证了只通知最新的数据。
自顶向下分析总结
自顶向下方法主要难点在于从类关系图中找出要分析的核心方法及其调用关系链,这需要提前对该组件有一定的理解,本次LiveData的分析先使用了软件过程的三个角度框定了方法范围,再通过在源码快速跳转的方式整理出调用链,大家可以在自己分析时参考。确定了要分析的方法后,接下来就是细心的分析工作,需要注意的是在这个过程中要总结出其实现的特性,从而更好地指导在日常实际开发工作。
03逐类分析
逐类分析的方式适合对一个组件不了解的情况下使用,以期快速地掌握大概原理。整个过程就是以总结类功能为目的,对组件的相关类逐个通过跳转方法进入,快速阅读并做出总结,掌握类功能定义,为以后使用其它方式进一步理解源码做好准备。下面以这个方式分析一下ViewModel的源码。
首先,还是先看一个例子:
public class MyViewModel extends ViewModel {
private MutableLiveData<List<User>> users;
public LiveData<List<User>> getUsers() {
if (users == null) {
users = new MutableLiveData<List<User>>();
loadUsers();
}
return users;
}
private void loadUsers() {
// Do an asynchronous operation to fetch users.
}
}
public class MyActivity extends AppCompatActivity {
public void onCreate(Bundle savedInstanceState) {
MyViewModel model = new ViewModelProvider(this).get(MyViewModel.class);
}
}该例子定义了一个ViewModel的子类MyViewModel,然后通过ViewModelProvider的实例方法get()获取到MyViewModel的实例。
ViewModelProvider
/**
* Creates {@code ViewModelProvider}. This will create {@code ViewModels}
* and retain them in a store of the given {@code ViewModelStoreOwner}.
* <p>
* This method will use the
* {@link HasDefaultViewModelProviderFactory#getDefaultViewModelProviderFactory() default factory}
* if the owner implements {@link HasDefaultViewModelProviderFactory}. Otherwise, a
* {@link NewInstanceFactory} will be used.
*/
public ViewModelProvider(@NonNull ViewModelStoreOwner owner) {
this(owner.getViewModelStore(), owner instanceof HasDefaultViewModelProviderFactory
? ((HasDefaultViewModelProviderFactory) owner).getDefaultViewModelProviderFactory()
: NewInstanceFactory.getInstance());
}
/**
* Creates {@code ViewModelProvider}, which will create {@code ViewModels} via the given
* {@code Factory} and retain them in the given {@code store}.
*
* @param store {@code ViewModelStore} where ViewModels will be stored.
* @param factory factory a {@code Factory} which will be used to instantiate
* new {@code ViewModels}
*/
public ViewModelProvider(@NonNull ViewModelStore store, @NonNull Factory factory) {
mFactory = factory;
mViewModelStore = store;
}从构造方法中可以看出ViewModelProvider需要ViewModelStore和Factory两个类型的成员变量才能构造处理,分别是mViewModelStore和mFactory,ComponentActivity和Fragment分别都实现了ViewModelStoreOwner和HasDefaultViewModelProviderFactory接口,所以都可以从中获取到ViewModelStore和Factory的实例。
@NonNull
@MainThread
public <T extends ViewModel> T get(@NonNull Class<T> modelClass) {
String canonicalName = modelClass.getCanonicalName();
if (canonicalName == null) {
throw new IllegalArgumentException("Local and anonymous classes can not be ViewModels");
}
return get(DEFAULT_KEY + ":" + canonicalName, modelClass);
}
@MainThread
public <T extends ViewModel> T get(@NonNull String key, @NonNull Class<T> modelClass) {
ViewModel viewModel = mViewModelStore.get(key);
if (modelClass.isInstance(viewModel)) {
if (mFactory instanceof OnRequeryFactory) {
((OnRequeryFactory) mFactory).onRequery(viewModel);
}
return (T) viewModel;
} else {
//noinspection StatementWithEmptyBody
if (viewModel != null) {
// TODO: log a warning.
}
}
if (mFactory instanceof KeyedFactory) {
viewModel = ((KeyedFactory) mFactory).create(key, modelClass);
} else {
viewModel = mFactory.create(modelClass);
}
mViewModelStore.put(key, viewModel);
return (T) viewModel;
}get()方法首先尝试通过mViewModelStore的get()方法获取ViewModel的实例,如果没获取到则使用mFactory的create()创建实例,创建出来后则存入到mViewModelStore中。在这里mFactory就是ViewModel的构造工厂,mViewModelStore则是ViewModel的缓存管理者。
ViewModelProvider作为ViewModel的提供者,使用缓存mViewModelStore和工厂mFactory实现,第一次提供ViewModel时会通过工厂创建出来,后续则都是从缓存中拿。
ViewModelStore
public ComponentActivity() {
...
getLifecycle().addObserver(new LifecycleEventObserver() {
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
if (event == Lifecycle.Event.ON_DESTROY) {
if (!isChangingConfigurations()) {
getViewModelStore().clear();
}
}
}
});
}
@NonNull
@Override
public ViewModelStore getViewModelStore() {
if (getApplication() == null) {
throw new IllegalStateException("Your activity is not yet attached to the "
+ "Application instance. You can't request ViewModel before onCreate call.");
}
if (mViewModelStore == null) {
NonConfigurationInstances nc =
(NonConfigurationInstances) getLastNonConfigurationInstance();
if (nc != null) {
// Restore the ViewModelStore from NonConfigurationInstances
mViewModelStore = nc.viewModelStore;
}
if (mViewModelStore == null) {
mViewModelStore = new ViewModelStore();
}
}
return mViewModelStore;
}ViewModelStoreOwner接口getViewModelStore()的实现就是提供一个ViewModelStore实例,而ComponentActivity使用Lifecycle能力在页面销毁时调用ViewModelStore实例的clear方法,清空其中的ViewModel。
public class ViewModelStore {
private final HashMap<String, ViewModel> mMap = new HashMap<>();
final void put(String key, ViewModel viewModel) {
ViewModel oldViewModel = mMap.put(key, viewModel);
if (oldViewModel != null) {
oldViewModel.onCleared();
}
}
final ViewModel get(String key) {
return mMap.get(key);
}
Set<String> keys() {
return new HashSet<>(mMap.keySet());
}
/**
* Clears internal storage and notifies ViewModels that they are no longer used.
*/
public final void clear() {
for (ViewModel vm : mMap.values()) {
vm.clear();
}
mMap.clear();
}
}ViewModelStore中使用HashMap管理ViewModel缓存,它被页面持有,并在页面真正销毁时才清空缓存。
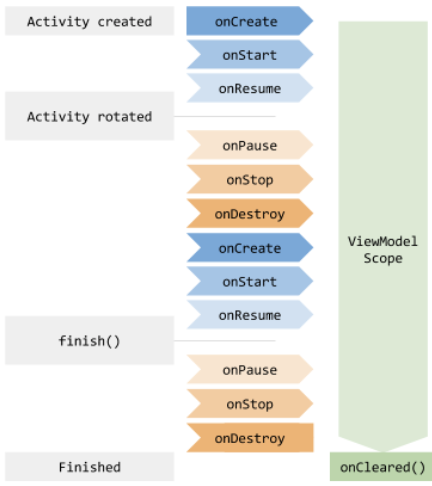
官网的这张图中可以说明ViewModel的生命周期。
SaveStateViewModelFactory
public ViewModelProvider.Factory getDefaultViewModelProviderFactory() {
if (getApplication() == null) {
throw new IllegalStateException("Your activity is not yet attached to the "
+ "Application instance. You can't request ViewModel before onCreate call.");
}
if (mDefaultFactory == null) {
mDefaultFactory = new SavedStateViewModelFactory(
getApplication(),
this,
getIntent() != null ? getIntent().getExtras() : null);
}
return mDefaultFactory;
}ComponentActivity中getDefaultViewModelProviderFactory()方法通过构造方法创建一个SavedStateViewModelFactory对象,传入了Application、当前ComponentActivity实例和Intent中的数据bundle。
SavedStateViewModelFactory构造方法
public SavedStateViewModelFactory(@NonNull Application application,
@NonNull SavedStateRegistryOwner owner,
@Nullable Bundle defaultArgs) {
mSavedStateRegistry = owner.getSavedStateRegistry();
mLifecycle = owner.getLifecycle();
mDefaultArgs = defaultArgs;
mApplication = application;
mFactory = ViewModelProvider.AndroidViewModelFactory.getInstance(application);
}构造方法接受的参数中,页面实例是SavedStateRegistryOwner接口类型的,通过该接口获取到SavedStateRegistry和Lifecycle。另外成员变量mFactory是AndroidViewModelFactory的单例对象。
SavedStateViewModelFactory的create()
@Override
public <T extends ViewModel> T create(@NonNull String key, @NonNull Class<T> modelClass) {
boolean isAndroidViewModel = AndroidViewModel.class.isAssignableFrom(modelClass);
Constructor<T> constructor;
if (isAndroidViewModel) {
constructor = findMatchingConstructor(modelClass, ANDROID_VIEWMODEL_SIGNATURE);
} else {
constructor = findMatchingConstructor(modelClass, VIEWMODEL_SIGNATURE);
}
// doesn't need SavedStateHandle
if (constructor == null) {
return mFactory.create(modelClass);
}
SavedStateHandleController controller = SavedStateHandleController.create(
mSavedStateRegistry, mLifecycle, key, mDefaultArgs);
try {
T viewmodel;
if (isAndroidViewModel) {
viewmodel = constructor.newInstance(mApplication, controller.getHandle());
} else {
viewmodel = constructor.newInstance(controller.getHandle());
}
viewmodel.setTagIfAbsent(TAG_SAVED_STATE_HANDLE_CONTROLLER, controller);
return viewmodel;
} catch (IllegalAccessException e) {
throw new RuntimeException("Failed to access " + modelClass, e);
} catch (InstantiationException e) {
throw new RuntimeException("A " + modelClass + " cannot be instantiated.", e);
} catch (InvocationTargetException e) {
throw new RuntimeException("An exception happened in constructor of "
+ modelClass, e.getCause());
}
}create()方法支持创建三种类型的ViewModel:AndroidViewModel、支持SavedState的ViewModel、普通ViewModel,这里由于篇幅原因,只分析一下普通ViewModel的创建。普通ViewModel通过mFactory的create()方法创建出来。
AndroidViewModelFactory的create()
public static class AndroidViewModelFactory extends ViewModelProvider.NewInstanceFactory {
...
@NonNull
@Override
public <T extends ViewModel> T create(@NonNull Class<T> modelClass) {
if (AndroidViewModel.class.isAssignableFrom(modelClass)) {
//noinspection TryWithIdenticalCatches
try {
return modelClass.getConstructor(Application.class).newInstance(mApplication);
} catch (NoSuchMethodException e) {
throw new RuntimeException("Cannot create an instance of " + modelClass, e);
} catch (IllegalAccessException e) {
throw new RuntimeException("Cannot create an instance of " + modelClass, e);
} catch (InstantiationException e) {
throw new RuntimeException("Cannot create an instance of " + modelClass, e);
} catch (InvocationTargetException e) {
throw new RuntimeException("Cannot create an instance of " + modelClass, e);
}
}
return super.create(modelClass);
}
}AndroidViewModelFactory的create()方法判断如果不是AndroidViewModel类型,就直接通过父类的create()方法创建,而AndroidViewModelFactory的父类是NewInstanceFactory。
NewInstanceFactory的create()
public static class NewInstanceFactory implements Factory {
...
@SuppressWarnings("ClassNewInstance")
@NonNull
@Override
public <T extends ViewModel> T create(@NonNull Class<T> modelClass) {
//noinspection TryWithIdenticalCatches
try {
return modelClass.newInstance();
} catch (InstantiationException e) {
throw new RuntimeException("Cannot create an instance of " + modelClass, e);
} catch (IllegalAccessException e) {
throw new RuntimeException("Cannot create an instance of " + modelClass, e);
}
}
}NewInstanceFactory的create()则是直接通过反射创建出ViewModel实例。
SaveStateViewModelFactory作为ComponentActivity和Fragment提供的对象,在NewInstanceFactory的基础上增加了对AndroidViewModel和支持SavedStated的ViewModel的创建,但对于普通的ViewModel创建,最后还是降级使用NewInstanceFactory完成。
到此,ViewModel的主要类已经分析完了,接下来可以结合类关系,一定程度上总结出对全局视角的理解。
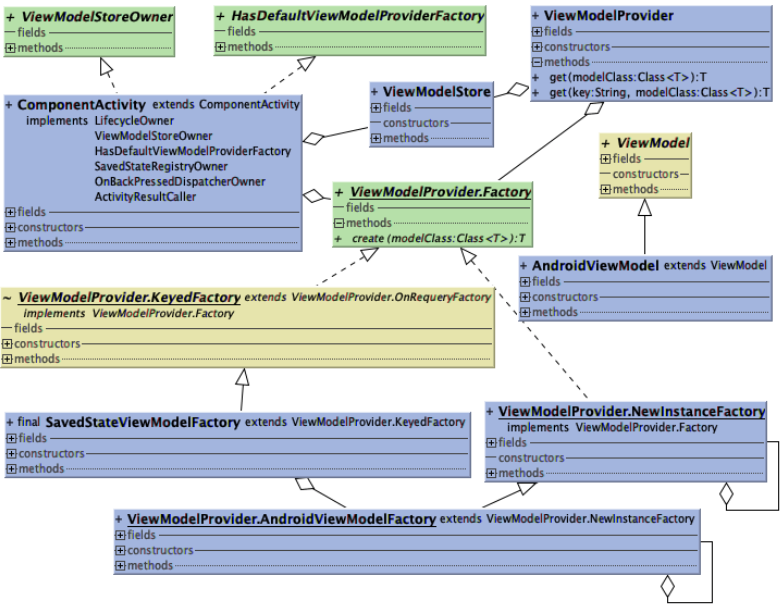
主要类说明:
- ViewModelProvider:ViewModel提供者
- ViewModelStore:ViewModel缓存管理
- ViewModelProvider.Factory:ViewModel创建工厂
- SavedStateViewModelFactory:ViewModel创建工厂的实现
- NewInstanceFactory:普通ViewModel创建工厂的实现
类关系描述:
ViewModel通过ViewModelProvider的get()方法获取到,ViewModelProvider由缓存ViewModelStore和创建工厂ViewModelProvider.Factory组合而成,ViewModelStore和ViewModelProvider.Factory也是ComponentActivity的一部分,ComponentActivity通过实现ViewModelStoreOwner和HasDefaultViewModelProviderFactory两个接口对外提供ViewModelStore和ViewModelProvider.Factory。其中,ViewModelProvider.Factory在ComponentActivity的具体实现是SavedStateViewModelFactory,SavedStateViewModelFactory一部分由AndroidViewModelFactory组合而成,它提供创建三种ViewModel的能力,其中普通ViewModel的创建是由AndroidViewModelFactory的父类NewInstanceFactory完成。
逐类分析方法总结
逐类分析重点在于抓大放小,分析每个类的主要目的是掌握该类的功能定位,达到目的即可,不要深陷到源码细节中。在快速分析完后,结合相关的类做出总结,从而获得整体上的了解,为以后进一步源码原理分析打好基础。
源码分析技巧
Android Jetpack是一个比较新的开源库,有几个技巧可以提高分析的效率,比如查看代码提交记录和使用单元测试。
01查看代码提交记录
比如Lifecycling的lifecycleEventObserver()方法比较复杂,刚开始不太能理解这个方法封装注解解析后的监听者那部分逻辑。可以使用以下方法查看这几行的提交记录,方便理解。
查看Annotate:
点击相关行,查看提交信息
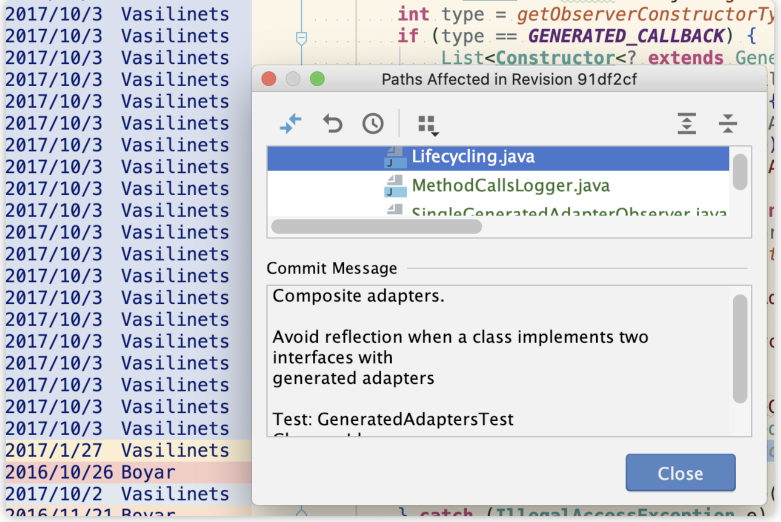
双击相关类,查看改动记录
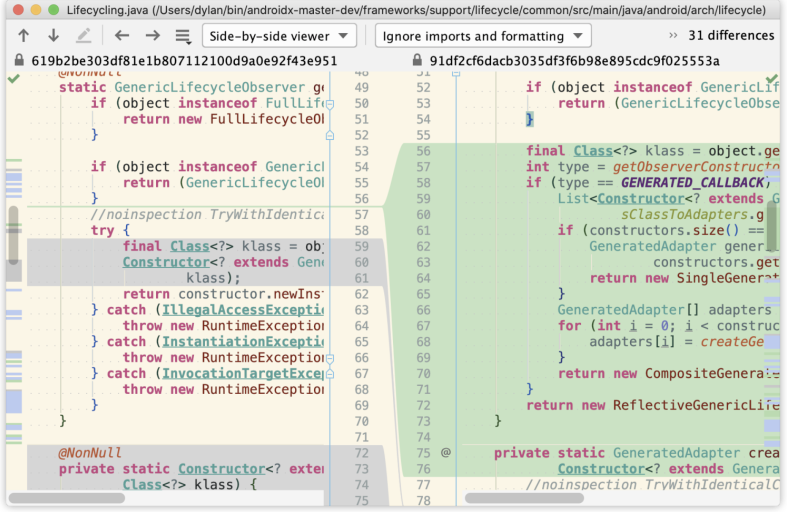
在改动记录中,还可以继续查看Annotation,理解原有的功能

可以使用该技巧先理解旧功能是什么样的,从而对比出这次改动所增加的特性。
以本例来说,可以看出旧getObserverConstructorType()方法是直接返回构造对象,这个构造对象可能是注解处理器生成的类的,也可能是普通监听者需要用反射处理的类的,然后用这个构造对象创建出监听器的封装。而这次修改了getObserverConstructorType()返回为解析后的结果类型,包括REFLECTIVE_CALLBACK和GENERATED_CALLBACK,再用这个类型和getObserverConstructorType()方法中解析的缓存判断应该创建哪个监听器的封装对象。这次增加的功能点是对实现多个LifecycleObserver接口的监听器的支持,可以在单元测试类GeneratedAdapterTest中找到具体使用示例。
interface OnPauses extends LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
void onPause();
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
void onPause(LifecycleOwner owner);
}
interface OnPauseResume extends LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
void onPause();
@OnLifecycleEvent(Lifecycle.Event.ON_RESUME)
void onResume();
}
class Impl1 implements OnPauses, OnPauseResume {
List<String> mLog;
Impl1(List<String> log) {
mLog = log;
}
@Override
public void onPause() {
mLog.add("onPause_0");
}
@Override
public void onResume() {
mLog.add("onResume");
}
@Override
public void onPause(LifecycleOwner owner) {
mLog.add("onPause_1");
}
}比如上面的Impl1实现了OnPauses和OnPauseResume两个LifecycleObserver接口,这次增加的功能点就是对Impl1也可以使用注解解析器生成封装类,以优化性能。
02使用单元测试用例
JetPack中的单元测试非常丰富,而且从提交信息中一般都可以看到本次改动对应修改的单元测试类,比如上面的例子中,Commit Message可以看到“Test: GeneratedAdaptersTest”,可以很快定位到该单元测试,再加上断点调试的手段,更快地理解源码。
比如,之前一直有提到注解解析器生成的监听器封装类,那这个类具体代码是什么样的呢,就可以在GeneratedAdaptersTest找到使用注解的实例,再通过断点找到这个类。
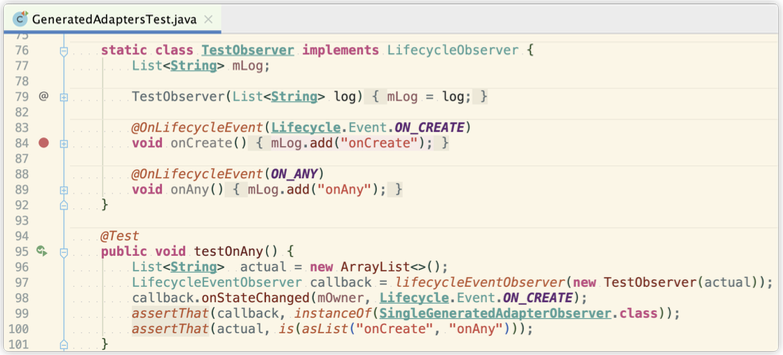
debug运行testOnAny()测试
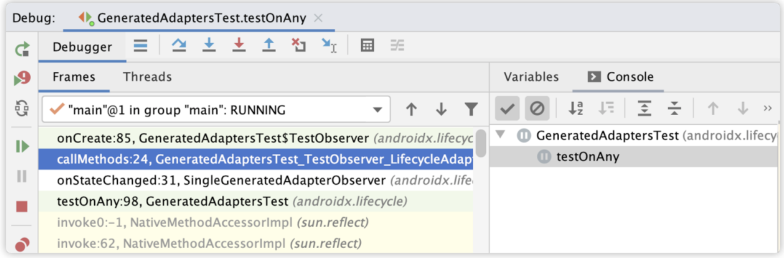
通过堆栈可以定位到GeneratedAdaptersTest_TestObserver_LifecycleAdapter类,
public class GeneratedAdaptersTest_TestObserver_LifecycleAdapter implements GeneratedAdapter {
final GeneratedAdaptersTest.TestObserver mReceiver;
GeneratedAdaptersTest_TestObserver_LifecycleAdapter(GeneratedAdaptersTest.TestObserver receiver) {
this.mReceiver = receiver;
}
@Override
public void callMethods(LifecycleOwner owner, Lifecycle.Event event, boolean onAny,
MethodCallsLogger logger) {
boolean hasLogger = logger != null;
if (onAny) {
if (!hasLogger || logger.approveCall("onAny", 1)) {
mReceiver.onAny();
}
return;
}
if (event == Lifecycle.Event.ON_CREATE) {
if (!hasLogger || logger.approveCall("onCreate", 1)) {
mReceiver.onCreate();
}
return;
}
}
}该类既是注解解析器生成的监听器封装类,它的callMethods()方法的实现由TestObserver的注解决定,TestObserver中使用了ON_CREATE和ON_ANY注解,所以除了onAny为true的情况,callMethods()只回调监听者的onCreate()方法。
注解处理器的实现可以定位到lifecycle-compiler项目中看,这里限于篇幅就不展开了。
总结
本文以Lifecycle、LiveData和ViewModel三个组件,分别介绍了自底向上、自顶向下和逐类分析三种分析方法,以及查看代码提交记录和使用单元测试用例两个简单的技巧。需要说明的是,分析方法和技巧都不是独立的,比如逐类分析其实就是简单版的自底向上,只不过它更适合在对一个组件不太了解的情况下快速掌握大概原理,使用逐类分析掌握基本原理后,还可以继续采用自顶向下的方法再分析一遍,以便更好地掌握组件的特性,减少实际工作中踩坑的可能。
而在分析源码后,对分析方法和技巧做一些总结,可以使得分析工作的效率越来越高。大家如果有其它想法和心得,欢迎和我交流。