Android 内存缓存 LruCache 原理与实现
okhttp和glide都使用的lru缓存,那什么是lru缓存呢?android 又是如何实现lru缓存 的呢?
LRU,即Least Recently Used的缩写,就是最近最少使用,通俗意思就是最近最少被使用的会最先被从内存中除去,举个例子:内存大小为3,我们要1,2,3,4,2,3 六个数字,则:
首次调用1,内存里为1;
调用2,内存里为2,1
调用3,内存里为3,2,1
调用4,内存里为4,3,2
调用2,内存里为2,4,3
调用3,内存里为3,2,4
之后我们在存入一个7,则内存里为7,3,2
这里我们看出来,最先被放进内存的,会被最先删除,如果先被放入内存而被调用,则会放到最前面
我们知道了lrucache的原理,那Android是怎么实现LruCache的呢?
在Android中,使用了LinkedHashMap来实现Lru,
我们知道,Java中HashMap是一个哈希表,hashmap本身是无顺序的,而LinkedHashMap是有序的,LinkedHashMap使用双向链表的形式来存储MapEntry的,我们依次往LinkedHashMap中插入1,2,3,4,5,6 六个数字,然后打印遍历结果

插入数据

遍历
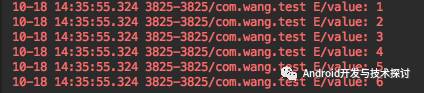
遍历结果
然后我们在get("key3"),再插入一个数据7,之后再遍历

get数据后插入数据
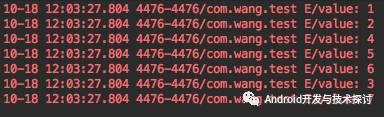
遍历结果
我们发现顺序变成了1,2,4,5,6,3,7 其中get 3后3到了表尾,插入7后7到了表尾,为什么会这样呢?这和LinkedHashMap的实现有关:
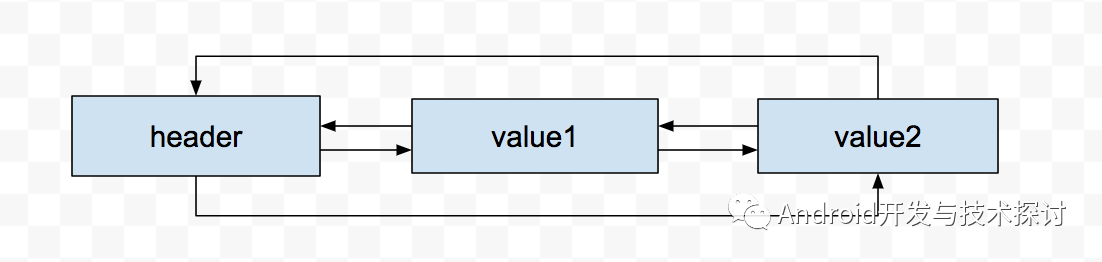
linkedhashmap链表方式
这样,我们添加数据会添加到链表最后的位置,而LinkedHashMap在初始化中,可以设置为按插入顺序来插入还是get读取顺序
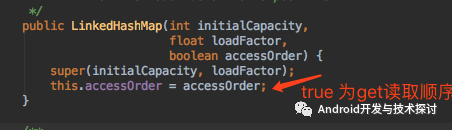
LinkedHashMap 初始化
LinkedHashMap在get数据的时候,会先查找表,如果有,则从链表里删除,移动到表尾,没有,则返回null
//LinkedHashMap get数据
publicVget(Object key) {
LinkedHashMapEntry e = (LinkedHashMapEntry)getEntry(key);//查找表里是否有
//数据,getEntry()为LinkedHashMap继承HashMap方法
if(e ==null)
return null;
e.recordAccess(this);//调用LinkedHashMapEntry的recordAccess()方法
returne.value;
}
我们看LinkedHashMapEntry类
/**
* LinkedHashMap entry.
*/
private static class LinkedHashMapEntry extends HashMapEntry {
LinkedHashMapEntrybefore,after;
LinkedHashMapEntry(inthash,Kkey,Vvalue,HashMapEntry next) {
super(hash,key,value,next);
}
private void remove() {
before.after=after;
after.before=before;
}
private void addBefore(LinkedHashMapEntry existingEntry) {
after= existingEntry;//add value next指向header
before= existingEntry.before;//add value before指向 之前表尾
before.after=this;//之前表尾 next指向 add value
after.before=this;//header before指向 add value
}
void recordAccess(HashMap m) {
LinkedHashMap lm = (LinkedHashMap)m;
if(lm.accessOrder) {//get模式
lm.modCount++;
remove();//从链表中删除
addBefore(lm.header);//添加到表尾
}
}
void recordRemoval(HashMap m) {
remove();
}
}
通过LinkedHashMapEntry的recordAccess我们看到,如果链表中有链表会先将原先的entry 从链表中删除,然后再放到表尾,例如我们使用get方法get 上面 的value1后的链表为以下内容:
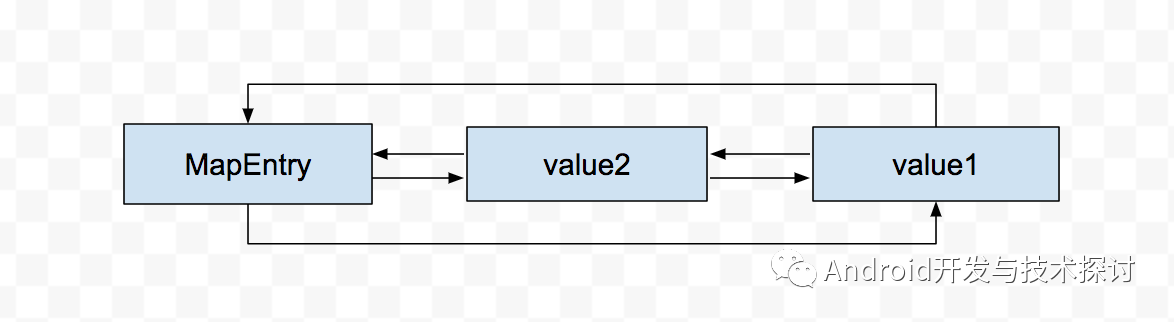
LinkedHashMap get value1后
我们发现,LinkedHashMap和Lru的思路是相同的,最近使用的被放在表尾(内存头),而最远时间使用的呗放在表头(内存尾),这样,就可以使用LinkedHashMap来实现lru
我们在初始化LruCache的时候,给LruCache设置最大大小
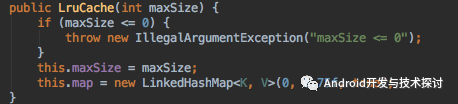
初始化LruCache
//LruCache get数据方法
public final V get(Kkey) {
if(key ==null) {
throw newNullPointerException("key == null");
}
V mapValue;
synchronized(this) {
mapValue =map.get(key);//从LinkedHashMap中查找,找到则放到表尾
if(mapValue !=null) {
hitCount++;//命中次数+1
return mapValue;
}
missCount++;//没有找到,miss次数加1
}
V createdValue = create(key);//创建新的value
if(createdValue ==null) {//创建失败返回null
return null;//未找到,返回null
}
synchronized(this) {
createCount++;//创建成功 ,创建次数+1
mapValue =map.put(key,createdValue);//put到linkedHashMap中,放到表尾
//如果表中原先有数据并且和creat的不一致,返回旧数据,否则返回null
if(mapValue !=null) {
// There was a conflict so undo that last put
map.put(key,mapValue);//撤销put 新的createValue
}else{
size+= safeSizeOf(key,createdValue);//size大小加上新加数据size
}
}
if(mapValue !=null) {
entryRemoved(false,key,createdValue,mapValue);
return mapValue;
}else{
trimToSize(maxSize);//重新计算空间大小,是否能插入下条数据
returncreatedValue;
}
}
get 数据的时候,如果有数据则返回数据,没有则创建数据,如果创建失败了,则返回null,成功了则插入数据并返回,创建成功其实和put是差不多的
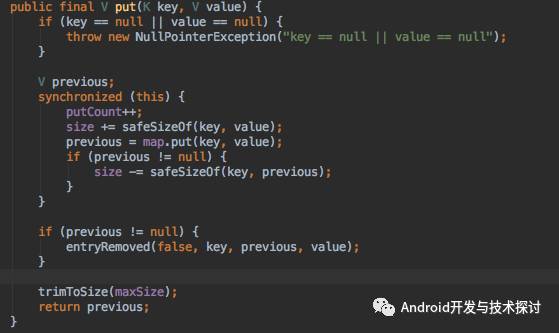
put 插入数据
put 的时候,先计算新加数据的大小,size增加,如果之前有key的数据,size再减去之前数据的大小,最后再重新计算空间大小
trimToSize方法是重新计算空间,如果空间足够,则插入,不够则从表中删除最早插入数据,直到空间足够位置,每次在map中插入数据都要重新计算空间
//LruCatch释放空间
public void trimToSize(intmaxSize) {
while(true) {
K key;
V value;
synchronized(this) {
if(size<0|| (map.isEmpty() &&size!=0)) {
throw newIllegalStateException(getClass().getName()
+".sizeOf() is reporting inconsistent results!");
}
if(size<= maxSize) {//size<=maxSize,返回
break;
}
Map.Entry toEvict =map.eldest();//获取map最早插入数据
if(toEvict ==null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);//删除数据
size-= safeSizeOf(key,value);//size减少
evictionCount++;
}
entryRemoved(true,key,value, null);
}
}

LinkedHashMap 获取最早插入数据
以上就是Android中自带LruCache的基本实现,其实LruCache的思路就是通过LinkedHashMap去存储或删除数据,最主要的还是get(),put()以及释放数据 的trimToSize()方法,当然这个LruCache只是google简单实现的缓存,我们可以根据需求使用LinkedHashMap自己去实现需要的LruCache