当你需要读一个 47M 的 JSON 文件
背景
事情是这样的,最近在做一个 emoji-search 的个人 Project,为了减少服务器的搭建及维护工作,我把 emoji 的 embedding 数据放到了本地,即 Android 设备上。这个文件的原始大小为 123M,使用 gzip 压缩之后,大小为 47.1M,文件每行都可以解析成一个 Json 的 Bean。文件的具体内容可以查看该链接。
链接地址
https://github.com/sunnyswag/emoji-search/releases/download/v1.0.0-beta/emoji_embeddings.gz
// 文件行数为:3753
// embed 向量维度为:1536
{"emoji": "\ud83e\udd47", "message": "1st place medal", "embed": [-0.018469301983714104, -0.004823130089789629, ...]}
{"emoji": "\ud83e\udd48", "message": "2nd place medal", "embed": [-0.023217657580971718, -0.0019081177888438106, ...]}emoji 的 embedding 数据,记录了每个 emoji 的 token 向量。用来做 emoji 的搜索。将用户输入的 embedding 和 emoji 的 embedding 数据做点积,得到点积较大的 emoji,即用户的搜索结果。 Android 测试机配置如下:
hw.cpu 高通 SDM765G
hw.cpu.ncore 8
hw.device.name OPPO Reno3 Pro 5G
hw.ramSize 8G
image.androidVersion.api 33小胆尝试
为了方便读取,我将文件放在了 raw 文件夹下,命名为 emoji_embeddings.gz。关键代码如下,这里我将 .gz 文件一次性加载到内存,然后逐行读取。
override suspend fun process(context: Context) = withContext(Dispatchers.IO) {
context.resources.openRawResource(R.raw.emoji_embeddings).use { inputStream ->
GZIPInputStream(inputStream).bufferedReader().use { bufferedReader ->
bufferedReader.readLines().forEachIndexed { index, line ->
val entity = gson.fromJson(line, EmojiJsonEntity::class.java)
// process entity
}
}
}
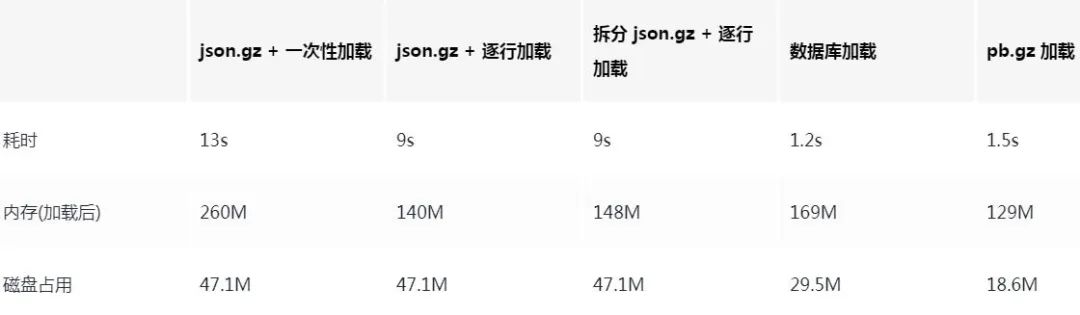
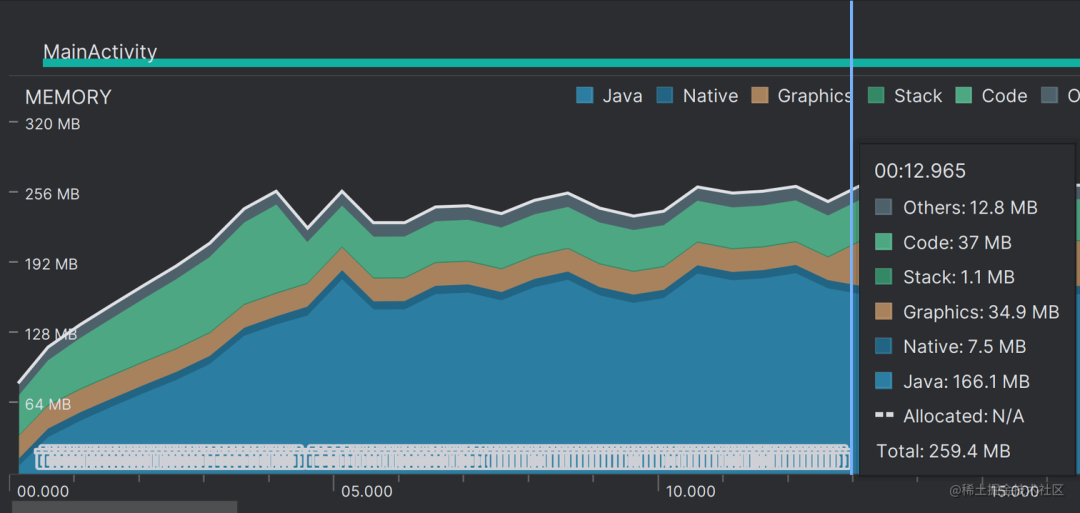
}结果可想而知,由于文件比较大,读取文件到内存的时间大概在 13s 左右。 并且在读取的过程中,内存抖动比较严重,这非常影响用户体验。
将文件一次性加载到内存,占用的内存也比较大,大概在 260M 左右,内存紧张的情况下容易出现 OOM。
于是,接下来的工作,就是优化内存的使用和减少加载的耗时了。
优化内存使用
逐行加载文件
很显然,我们最好不要将文件一次性加载到内存中,这样内存占用比较大,容易 OOM,我们可以使用 Reader 的 useLines API。类似于这样调用 bufferedReader().useLines{ } ,其原理为 Sequence + reader.readLine() 的实现。再使用 Flow 简单切一下线程,数据读取在 IO Dispatcher,数据处理在 Default Dispatcher。
代码如下:
override suspend fun process(context: Context) = withContext(Dispatchers.Default) {
flow {
context.resources.openRawResource(R.raw.emoji_embeddings_json).use { inputStream ->
GZIPInputStream(inputStream).use { gzipInputStream ->
gzipInputStream.bufferedReader().useLines { lines ->
for (line in lines) {
emit(line)
}
}
}
}
}.flowOn(Dispatchers.IO)
.collect {
val entity = gson.fromJson(it, EmojiJsonEntity::class.java)
// process entity
}
}但这样会导致另一个问题,那就是内存抖动。因为逐行加载到内存中,当前行使用完之后,就会等待 GC,这里暂时无法解决。
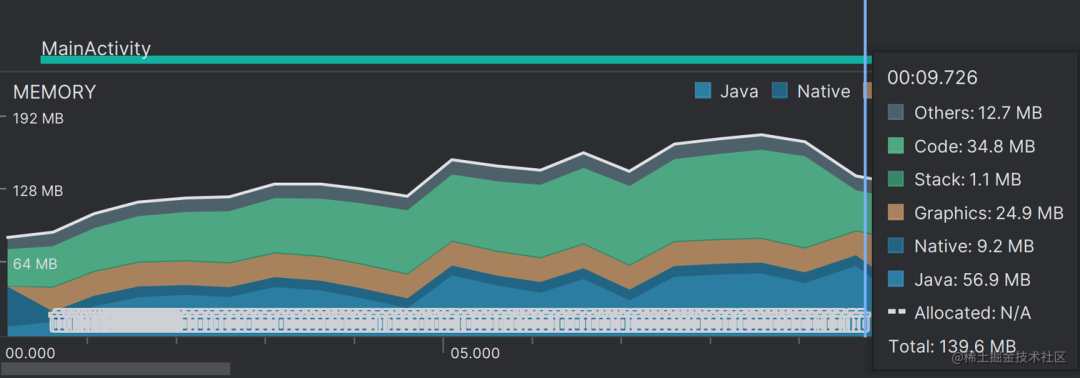
完成之后,加载时的内存可以从 260M 减少到 140M 左右,加载时间控制在 9s 左右。
减少内存抖动
通过查看代码,并使用 Profile 进行调试,我们可以发现,其实主要的 GC 操作频繁,主要是由这行代码导致的:line.toBean
笔者暂时没找到较好的解法,这里需要保证代码逻辑不过于复杂的同时,消除中间变量的创建。暂时先这样吧。有时间可以使用对象池试试。
减少加载耗时
找到最长耗时路径
测试下来,IO 大概耗时 3.8s,但是总的耗时在 9s。这里我指定了 IO 使用 IO 协程调度器,数据处理使用 Default 协程调度器,IO 和数据处理是并行的。所以总的来说,是数据处理在拖后腿。数据处理主要是这部分代码 line.toBean
加快 IO 操作
笔者暂时想到了以下两种处理方式:
单个流分段读取
在 GZIP 文件中,数据被压缩成连续的块,并且每个块的压缩是相对于前一个块的数据进行的。这就意味我们不能只读取文件的一部分并解压它,因为我们需要前面的数据来正确解码当前的块。
所以,对于 GZIP 文件来说,实现分段读取有一些困难。
这个想法,暂时先搁置吧。
多个流分段读取
同一个文件开启多个流
回到 GZIP 的讨论,同一个文件开启多个流也是徒劳的。因为即使多个线程处理各自的流,然后每个线程处理该文件的一部分,这也需要每个流从头开始对 GZIP 文件进行解压,然后跳过自己无需处理的部分。这么算下来,其实并不能加快总的 IO 速度,同时也会造成 CPU 资源的浪费。
将文件拆分成多个文件之后开启多个流
考虑这样的一种实现方式:对原有的 GZIP 文件进行拆分,拆分成多个小的 GZIP 文件,使用多线程读取,利用多核 CPU 加快 IO。听起来似乎可行,我们赶紧实现一下:
override suspend fun process(context: Context) = withContext(Dispatchers.Default) {
val mutex = Mutex()
List(STREAM_SIZE) { i ->
flow {
val resId = getEmbeddingResId(i) // 获取当前的资源文件 Id
context.resources.openRawResource(resId).use { inputStream ->
GZIPInputStream(inputStream).use { gzipInputStream ->
gzipInputStream.bufferedReader().useLines { lines ->
for (line in lines) {
emit(line)
}
}
}
}
}.flowOn(Dispatchers.IO)
}.asFlow()
.flattenMerge(STREAM_SIZE)
.collect { data ->
val entity = gson.fromJson(data, EmojiJsonEntity::class.java)
mutex.withLock {
// process entity
}
}
}笔者将之前的 json.gz 拆分成了 5 个文件,每个文件启动一个流去加载。之后再将这 5 个流通过 flattenMerge 合并成一个流,来进行数据处理。
由于 flattenMerge 有多线程操作,所以这里我们使用协程的 Mutex 加个锁,保证数据操作的原子性。
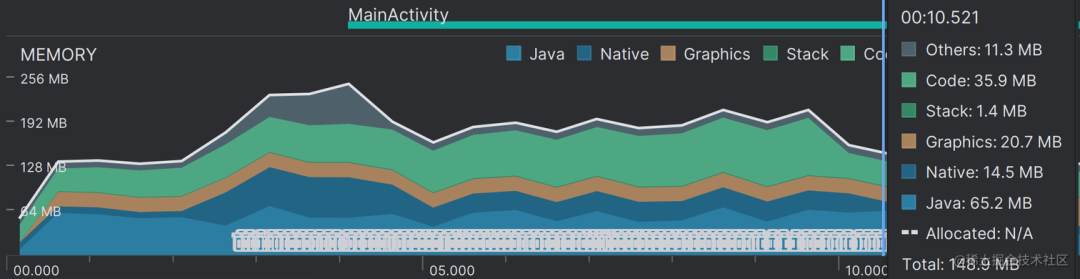
实际测试下来,如此操作的 IO 耗时在 2s,缩短为原来的一半,但总的耗时还是稳定在了 9s 左右,这多出来的 2s 具体花在哪里了暂时未知,咱接着优化一下数据处理。
缩短数据处理时间的方案分析
先明确一下需求:我们需要将文件一次性加载到内存中,文件大小为 40M+,其中有每行都有一个 1536 个元素的 float 数组。了解了一圈下来,目前知道的可行的方案有两个,而且大概率需要更换数据结构和存储方式:
数据库(如 Room)
在一些特定的情况下,使用数据库可能会有利,如当我们需要进行复杂查询、更新数据、或者需要随机访问数据的时候。如果需要使用数据库来缩短数据处理时间,那么我们需要在写入时就处理好数据格式,比如当前情况下,我们需要将 Float 数组使用 ByteArray 来存储。然而,在当前需求下,我们的数据相对简单,且只需要进行读操作。而且,我们的数据包含大量的浮点数数组,使用 ByteArray 来存储也会较为复杂。因此,数据库可能不是最理想的选择。但评论区大家对数据库比较看好,所以我们还是用数据库试试。
Protocol Buffers (PB)
PB 是一个二进制格式,比文本格式(如 JSON)更紧凑,更快,特别擅长存储和读取大量的数值数据(如 embed 数组)。我们的需求主要是读取数据,并且需要一次性将整个文件加载到内存中。因此,PB 可能是一个不错的选择。虽然 PB 数据不易于阅读和编辑,也不适合需要复杂查询或随机访问的情况。
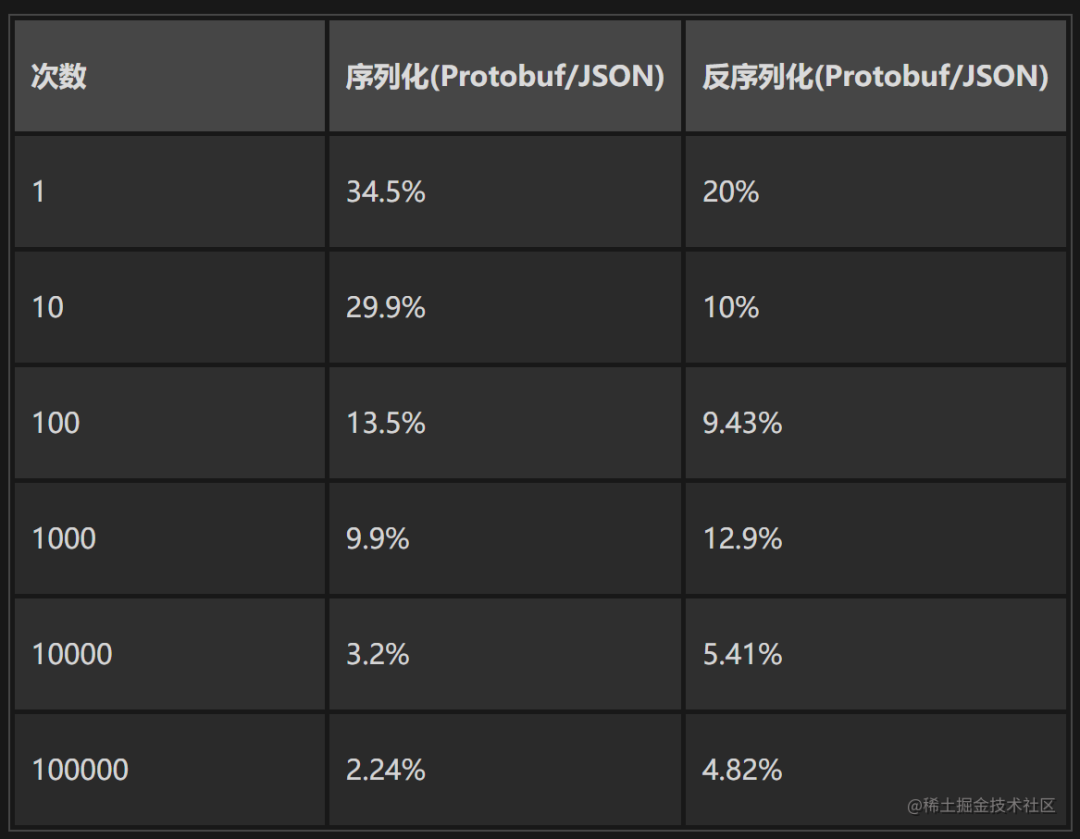
如上是 PB 和 Json 序列化和反序列化的对比 ref。可以看到,在一次反序列化操作的情况下, PB 是 Json 的 5 倍。次数越多,差距越大。
关于为什么二进制文件(PB)会比文本文件(Json)体积更小,读写更快。这里就不过多赘述了,笔者个人理解,简单来说,是信息密度的差异,具体的大家可以去搜索,了解更多。
使用 Room 存储 embedding 数据
使用 Room 存储 embedding 数据都是进行一些常规的 CRDU 操作,这里就不赘述了,基本思路就是我们将 Json 数据存储在数据库中,在需要使用的时候,直接读取数据库即可。
简单贴一下读取的代码:
override suspend fun process(context: Context) = withContext(Dispatchers.IO) {
val embeddingDao = getEmbeddingEntityDao(context)
embeddingDao.queryAll()?.forEachIndexed { index, emojiEmbeddingEntity ->
// process entity
}
Unit
}实在是过于简单了,读取就完事了,多线程由数据库底层来处理。
值得关注的是关于 Float 数组的存储和读取:
class EmbeddingEntityConverter {
@TypeConverter
fun fromFloatArray(floatArray: FloatArray): ByteArray {
val byteBuffer = ByteBuffer.allocate(floatArray.size * 4) // Float 是 4 字节
floatArray.forEach { byteBuffer.putFloat(it) }
return byteBuffer.array()
}
@TypeConverter
fun toFloatArray(byteArray: ByteArray): FloatArray {
val byteBuffer = ByteBuffer.wrap(byteArray)
return FloatArray(byteArray.size / 4) { byteBuffer.float } // Float 是 4 字节
}
}笔者使用了 Room 的 @TypeConverter 注解,会在存储时,将 FloatArray 转换为 ByteArray 存储到数据库中,读取时,将 ByteArray 转换为 FloatArray 供上层使用。
数据库读写的效果确实很惊艳,耗时 1.2s,稳定后内存占用 169MB 的样子,而且还不需要我自己处理多线程读写的问题,有点舒服。
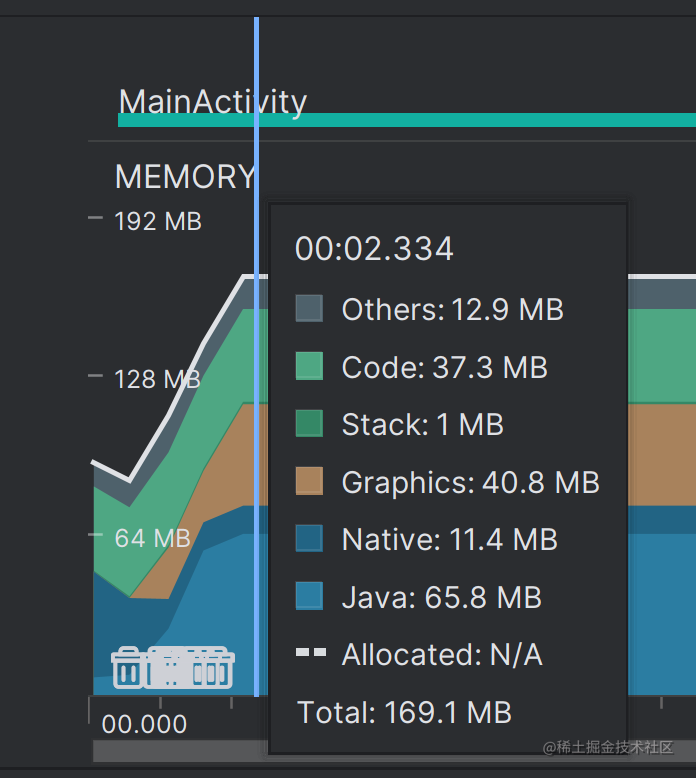
使用 Protocol Buffers (PB) 存储 embedding 数据
PB 文件比 Json 文件的读取要复杂不少,首先我们需要定义一下 proto 文件的格式。 这里的 repeated float 可以理解成 float 类型的 List 。
// emoji_embedding.proto
syntax = "proto3";
message EmojiEmbedding {
string emoji = 1;
string message = 2;
repeated float embed = 3;
}定义好之后,就可以进行数据的序列化操作了。值得一提的是,pb.gz 文件是 json.gz 文件的一半大小,只有 18.6M。在数据序列化的时候,笔者使用了 writeDelimitedTo API,该 API 会在写入数据时带上该条数据的长度,方便之后的数据反序列化操作。
这里我们直接看一下 Android 反序列化 PB 文件的代码:
override suspend fun process(context: Context) = withContext(Dispatchers.Default) {
flow {
context.resources.openRawResource(R.raw.emoji_embeddings_proto).use { inputStream ->
GZIPInputStream(inputStream).buffered().use { gzipInputStream ->
while (true) {
EmojiEmbeddingOuterClass.EmojiEmbedding.parseDelimitedFrom(gzipInputStream)?.let {
emit(it)
} ?: break
}
}
}
}.flowOn(Dispatchers.IO)
.buffer()
.flatMapMerge { byteArray ->
flow { emit(readEmojiData(byteArray)) }
}.collect {}
}
private fun readEmojiData(entity: EmojiEmbeddingOuterClass.EmojiEmbedding) {
// process entity
}这里因为有生成的 EmojiEmbeddingOuterClass 代码,所以解析起来还算方便,解析完操作 entity 即可。值得注意的是,我使用 flatMapMerge 来实现多线程处理,而不是使用 launch/async ,这里的目的是减少协程的创建,减少上下文的切换,减少并发数,来提高数据处理的速度。因为实际测试下来,flatMapMerge 的速度会更快。
那么这么做的实际效果如何呢?1.5s,和数据库读取相差不大。(这里由于开了 build with Profile,会比实际的慢一点)。稳定下来时,内存占用 129 M。
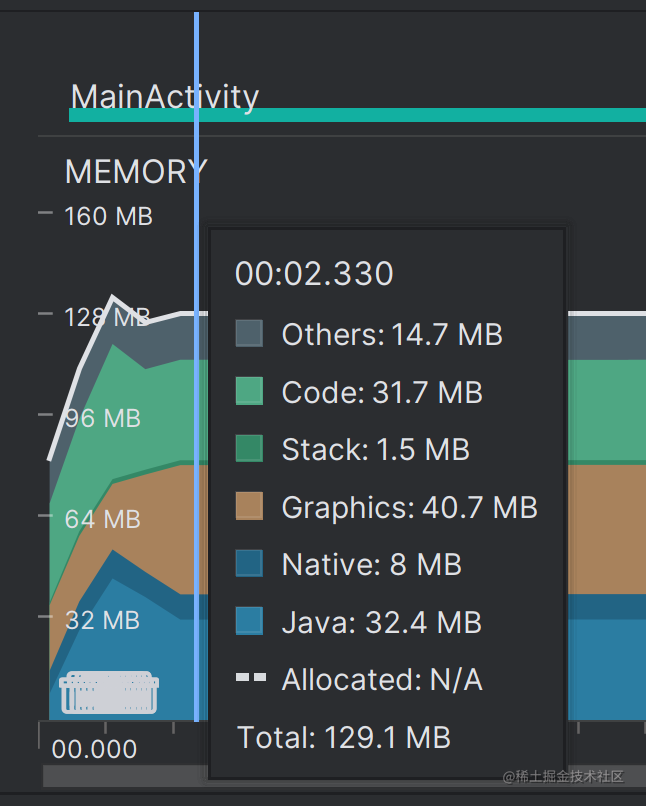
总结
大文件的读写,咱还是老老实实用字节码文件存储吧。小文件可以使用 Json,反序列化速度够用,可读性也可以有明显的提升。
至于是用 PB 还是数据库,可以根据个人喜好及具体的业务场景分析。两者在读写速度上都是没有差别的,但是数据库在内存和磁盘空间上会占用更多。使用 PB 需要自行处理多线程相关问题,难度会较大一点。
具体的性能对比,图表如下: